layline.io Blog
Vorteile von layline.io Workflows im Vergleich zu traditionellen Microservices innerhalb von layline.io unter Verwendung des K8S/Docker-Modells.
Das traditionelle Microservices-Modell auf Kubernetes/Docker hat einige Nachteile, die zu einem übermäßig komplexen Management und Ressourcenverbrauch führen. Wir erklären die Hintergründe und wie layline.io helfen kann.
Reading time: 7 min.

Das traditionelle Microservices-Modell auf Kubernetes/Docker hat einige Nachteile, die zu einem übermäßig komplexen Management und Ressourcenverbrauch führen. In diesem Artikel erläutern wir, wie layline.io die Container- und Container-Orchestrierungs-Technologie einsetzt und dabei hilft, die oben genannten Herausforderungen mit einem besseren Ansatz zu lösen.
Kurzer Erklärer: Kubernetes (K8S) & Docker
Container
Programme, die auf Kubernetes laufen, werden in Containern verpackt. Das hat den Vorteil, dass Software und Abhängigkeiten zusammen gepackt werden. So muss man sich um eine Sache weniger kümmern und die Unabhängigkeit des Containers ist gewährleistet. Es gibt tonnenweise fertige Container, die von Portalen wie DockerHub (https://hub.docker.com) heruntergeladen werden können und alle Arten von Software zusammenfassen.
Theoretisch kann man viele Programme in einen Container packen, aber die Empfehlung und der Industriestandard lautet: ein Container = ein Prozess. Dadurch wird alles granularer, und Sie können einzelne Container (und damit Prozesse) leichter ersetzen.
Pods
Container laufen nicht alleine, sondern sind in einem weiteren "Container" verpackt.
Diesmal heißen sie Pods.
Pods verwalten - unter anderem - virtuelle Ressourcen wie Netzwerk, Speicher, CPU etc. für die darin laufenden Containers.
Es ist wichtig zu verstehen, dass man die CPU-Leistung nicht einem Container, sondern einem Pod zuweist. Wenn Sie also mehr als einen Container in einem Pod betreiben, müssen sich alle die Ressourcen teilen, die dem Pod zur Verfügung stehen. Aus denselben Gründen, aus denen Sie nicht mehr als ein Programm in einen Container packen sollten, sollten Sie auch nicht mehr als einen Container in einen Pod packen, es sei denn, mehrere Container sind für den Zweck des Microservice erforderlich. Ein Beispiel hierfür wäre ein Container C1, der die eigentliche Servicelogik enthält, ein Container C2, der die Datenbank für den Service in C1 enthält, und ein Container C3, in dem etwas wie Istio läuft. **Der Einfachheit halber und für die Zwecke dieses Artikels wird dies jedoch als ein einziger Container betrachtet.
Ressourcenprobleme bei der Skalierung in Kubernetes
Die Währung der Skalierbarkeit in Kubernetes sind Pods. Um mehr Rechenleistung zu haben, schaltet man mehr Pods ein, auch bekannt als Replikation.
Wenn man sich dieses Design ansieht, ist ein Pod selbst eigentlich ziemlich statisch. Wenn Sie ein Höchstmaß an Flexibilität anstreben und ein Programm durch ein anderes ersetzen möchten, enthält Ihr Pod einen Container, der wiederum ein Programm enthält, das als ein Prozess ausgeführt wird.
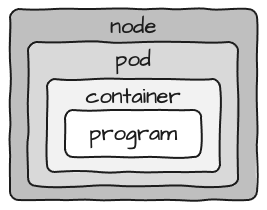
Wenn man bedenkt, dass die für den Container benötigten Ressourcen auf Pod-Ebene konfiguriert werden, sieht das Bild in etwa so aus:
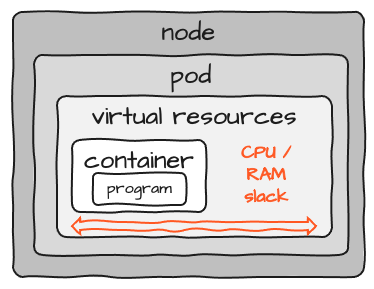
Achten Sie auf den als "Schlupf" markierten Platz. Wenn Sie die Ressourcen für einen Container dimensionieren, müssen Sie einen gewissen Spielraum bei CPU und Speicher einkalkulieren. Da es jedoch fast unmöglich ist, die erforderlichen Ressourcen für ein Programm genau zu bestimmen, bleibt in jedem Pod eine gewisse Reserve. Wenn Sie 100 dieser Programme laufen lassen, summiert sich der Spielraum auf das 100-fache. Es gibt keine gemeinsame Nutzung von Ressourcen zwischen Pods. Hinzu kommt ein gewisser Overhead für jeden Pod und Knoten, der dem Cluster hinzugefügt wird. Das Konzept von K8S ist zwar großartig, verursacht aber auch einen erheblichen Ressourcen-Overhead.
Verteilung von Containern innerhalb eines Kubernetes-Clusters
Pods sind auch der kleinste Nenner, um die Funktionalität innerhalb eines Kubernetes-Clusters zu verteilen. Nehmen wir an, Sie haben Microservices A, B und C und wollen diese ungleichmäßig innerhalb eines Clusters verteilen, dann haben Sie entweder einzelne Pods, die jeweils entweder A, B oder C enthalten, oder Sie müssen eine Reihe von Pods haben, um alle Permutationen von Pods zu bilden, die Container A, B und C enthalten (z. B. ein Pod mit A und B, ein Pod mit A und C, usw.). Das ist eine Menge Pods, die verwaltet werden müssen und die schnell überwältigend und ineffizient werden können.
Die Verteilung von Pods ist dann eine große Konfigurationsherausforderung innerhalb von Kubernetes und/oder dem CI/CD-Tool Ihrer Wahl. Hinzu kommt die Verwaltung der automatisierten Skalierung und des Lastausgleichs zwischen den Nodes, was die Einrichtung und Überwachung zu einem großen Problem macht.
Wie layline.io mit Skalierbarkeit, Ressourcen und Verteilung in einem Kubernetes Cluster umgeht
Reaktive Engine
layline.io führt die Reactive Engine ein.
Die Engine dient als Ausführungskontext für Workflows, die für die Ausführung innerhalb einer Reactive Engine konfiguriert werden können.
Workflows sind insofern mit Microservices vergleichbar, als dass sie spezifische Datenverarbeitungsaufgaben wie Ingestion, Analyse und Anreicherung sowie die Beantwortung von Abfragen etc. erfüllen.
Workflows werden über das webbasierte Configuration Center konfiguriert:
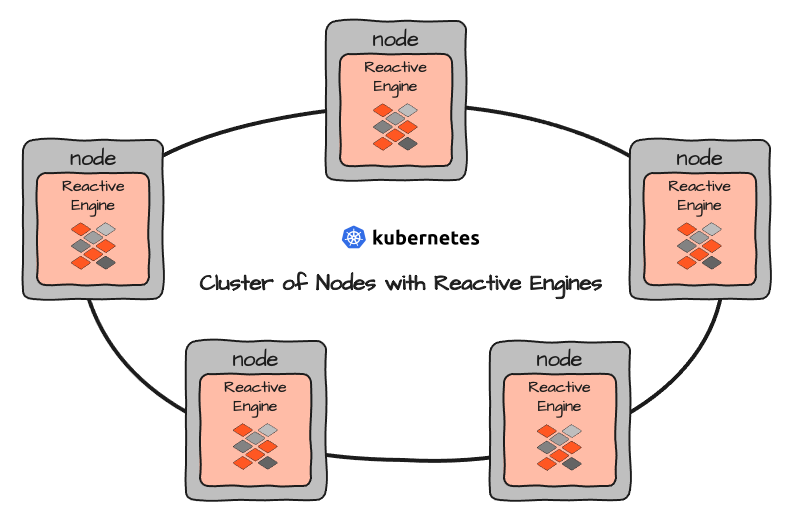
Mehrere Reactive Engines bilden einen eigenen Reactive Cluster. Wenn Sie layline.io in einer Cluster-Umgebung wie Kubernetes einrichten, richten Sie eigentlich eine Reihe von Nodes ein, auf denen dann in Containern gekapselte Reactive Engines laufen:
Alle Reactive Engines sind gleich aufgebaut. Sie dienen als Ausführungskontext für Workflows. Vereinfacht kann man Workflows als Äquivalent zu Microservices betrachten. Der Unterschied besteht darin, dass Workflows konfiguriert werden und daher eine Konfiguration sind und nicht wie bei typischen Microservices als Objektcode programmiert werden.
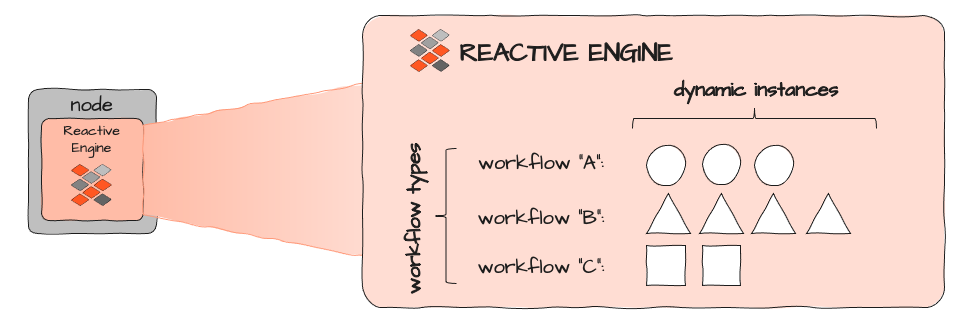
Jede Reactive Engine kann verschiedene Workflows ausführen (A, B und C oben). Jeder Workflow kann dynamisch mehrfach instanziiert werden. Die Anzahl der Instanzen wird dadurch begrenzt, wie viele Ressourcen eine einzelne Workflow-Instanz verbraucht und wie viele Ressourcen verfügbar sind und dem Ausführungskontext zugewiesen werden, in dem die Reactive Engine selbst läuft. In einem Kubernetes-Cluster wäre dies das Image eines entsprechenden Pods:
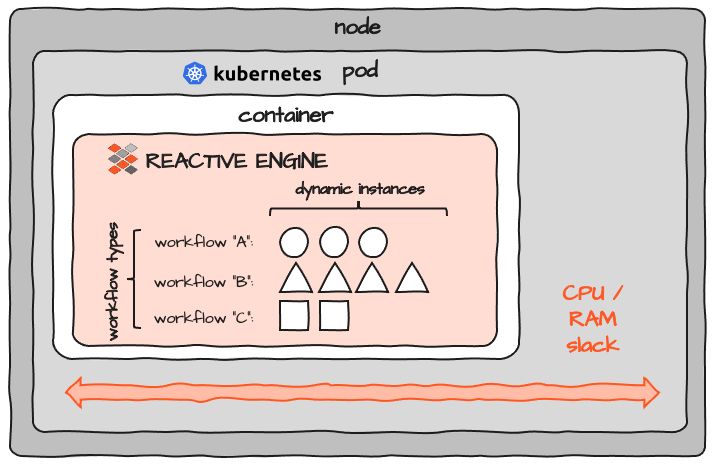
Jede Reactive Engine kann jeden Workflow ausführen. Workflows werden entweder direkt über das Configuration Center oder über Ihr bevorzugtes CI/CD-Tool (z. B. Bamboo und andere) bereitgestellt.
Dies könnte zu einem Setup wie diesem führen:
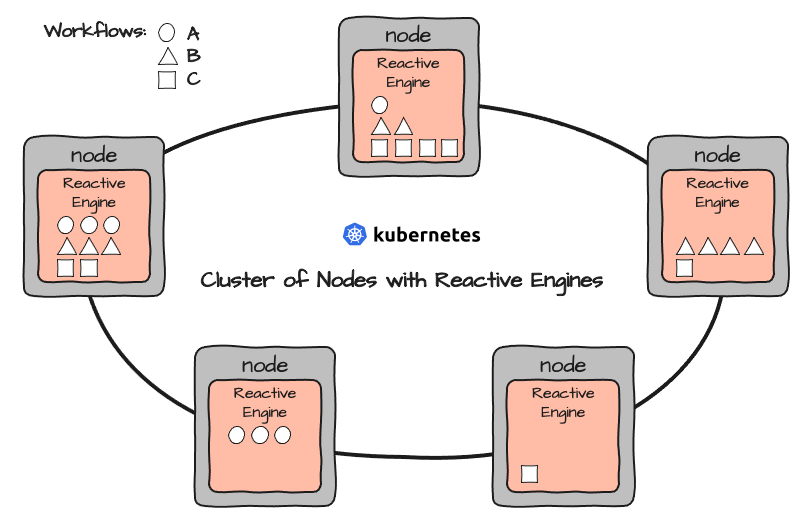
Wie die Abbildung zeigt, führen identische Reactive Engines unterschiedliche Workflows und eine unterschiedliche Anzahl von Instanzen aus.
Elastische Skalierung
Die Anzahl der Instanzen jedes Workflows kann dynamisch nach oben und unten skaliert werden, entweder durch manuelle Eingriffe über das Config Center oder die Befehlszeile oder automatisch auf der Grundlage des Datendrucks.
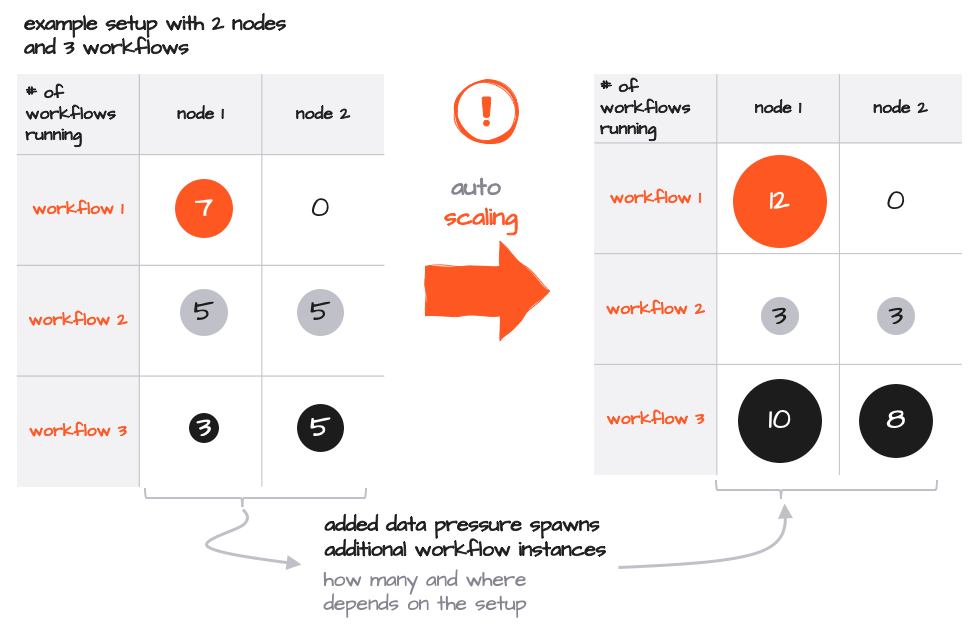
Während der Standard-Kubernetes-Weg zur Skalierung durch das Aktivieren zusätzlicher Pods weiterhin gültig ist, können Sie einfach zusätzliche Workflow-Instanzen innerhalb eines Pods aktivieren. Beachten Sie, dass in diesem Beispiel keine zusätzlichen Pods aktiviert werden, da jeder Pod genügend Spielraum für die Skalierung bietet. Da alles innerhalb einer Reactive Engine skaliert wird, ist dieser Prozess extrem schnell und effizient und erfordert nur wenige zusätzliche Ressourcen pro Instanz und keinen Eingriff auf Kubernetes-Ebene.
Man könnte argumentieren, dass dieses Konzept einfach Ressourcen vorreserviert, die bei geringer Last ungenutzt bleiben. Das wollen wir uns im nächsten Kapitel ansehen.
Vorteil Ressourcen
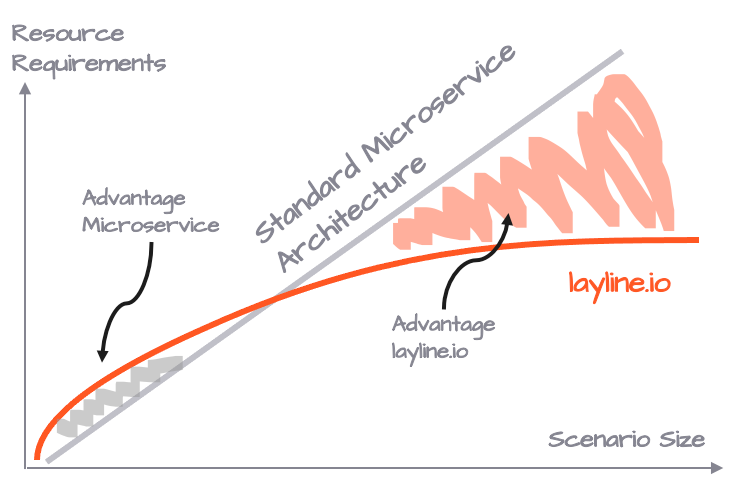
Es macht Sinn zu denken, dass man entsprechende CPU-Leistung und RAM benötigt, egal ob man 30 Pods mit demselben Microservice auf drei Nodes verteilt oder drei Reactive Engines mit je 10 Instanzen desselben Workflows auf drei Nodes. Das ist aber nicht der Fall.
Je nach Charakteristik des Microservices, der durch einen Workflow ersetzt wird, spart man typischerweise zwischen 25-50% der Ressourcen im Vergleich zur traditionellen Art der Bereitstellung von Microservices. Es stimmt jedoch auch, dass eine Reactive Engine, die nur eine Workflow-Instanz ausführt, mehr Ressourcen benötigt als ein benutzerdefinierter Microservice, der nur einmal ausgeführt wird.
Es ist ein Kompromiss zwischen Flexibilität und Ressourcenbedarf, der mit der Größe des Verarbeitungsszenarios schnell zu Gunsten des layline.io Modells kippt. Es gibt natürlich noch eine Menge anderer Vorteile, aber wenn man nur die Ressourcen betrachtet, sieht man, dass es so aussieht.
Vorteil Einrichtung
Die Einrichtung von layline.io in einem Kubernetes/Docker-Cluster bedeutet, dass auf jedem Node der gleiche Container eingesetzt wird. Auf jedem Container läuft eine Reactive Engine und es gibt keine weiteren Containertypen mit unterschiedlichen Inhalten. Nur einen.
Damit eine Reactive Engine weiß, welche Workflows sie ausführen soll, wird zur Laufzeit eine Konfiguration injiziert. Da alle Reactive Engines einen eigenen Reactive Cluster bilden, reicht es aus, die Konfiguration in eine Reactive Engine zu injizieren. Sie wird dann automatisch an alle anderen Engines im Cluster verteilt. Auch dies kann manuell oder automatisch über CI/CD-Tools getriggert werden. Der vorteilhafte Nebeneffekt ist, dass Konfigurationen in einer Instanz ohne neue Pod/Container-Deployments geändert und ausgetauscht werden können. Der Kubernetes-Cluster bleibt dabei unverändert.
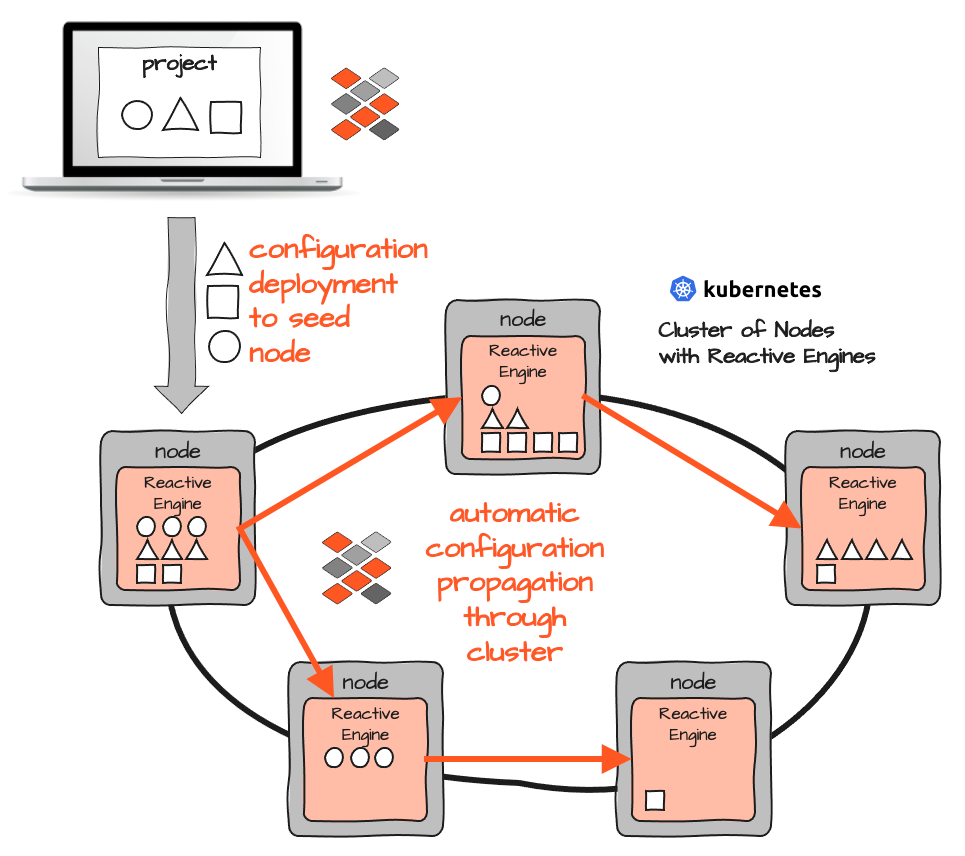
Im Gegensatz zum reinen Kubernetes/Docker-Konzept gibt es also keine Probleme mit verschiedenen Pods, die unterschiedliche Container enthalten, die bei jeder Änderung neu erstellt und dann vom Standpunkt der Bereitstellung aus verwaltet werden müssen. Im Gegensatz zu Kubernetes muss man sich nicht im Vorfeld Gedanken darüber machen, wo welcher Pod/Container laufen soll, oder wie man Pods umschichtet, wenn man sie neu anordnen möchte. In layline.io können Sie einfach einen vorgeladenen Workflow in einer oder mehreren Reactive Engines aktivieren, oder eine neue Workflow-Konfiguration in den Cluster deployen, um diesen Workflow online zu bringen.
Zusammenfassung
| Was | Standard K8S/Docker | layline.io |
|---|---|---|
| Skalierung | Skalierung über Pods | Skalierung innerhalb des Pods über Workflow-Instanzen |
| Skalierung Reaktionszeit | mittel | schnell |
| Ressourcenverbrauch | Besser bei kleinen Szenarien | Besser bei mittleren bis großen Szenarien |
| Setup | Viele verschiedene Pods und Container | Konfigurationen werden in die Reactive Engine eingespeist |
Kubernetes ist großartig. Punkt. Aber es gibt Nachteile in der Komplexität und im Betrieb.
layline.io bietet einen viel besseren und schlankeren Weg, um Services nicht nur zu erstellen und zu verwalten, sondern auch um sie in einer Cluster-Umgebung zu verwalten und zu verteilen. Für mittlere bis große Szenarien ergeben sich zudem erhebliche Vorteile in Bezug auf die Ressourcenverwaltung und den Ressourcenverbrauch.
Sie können layline.io kostenlos herunterladen und nutzen hier. Wenn Sie Fragen zu layline.io haben, zögern Sie bitte nicht, uns zu kontaktieren!
Resources
- Download layline.io
- Korrektur von Problemen mit Microservices
- Erfahren Sie hier mehr über layline.io.
- Kontaktieren Sie uns hello@layline.io.