layline.io Blog
Output zu Kafka.
Showcase zum Lesen von Daten aus einer strukturierten Datei, Mapping von Datensätzen und Ausgabe der Daten in der Kafka-Cloud.
Reading time: 10 min.
Was wir demonstrieren
Wir zeigen ein einfaches layline.io Projekt, das Daten aus einer Datei liest und deren Inhalt in ein Kafka-Topic ausgibt.

Um den Showcase in einem realen Setup zu verfolgen, können Sie die Assets dieses Projekts aus dem Ressourcen-Bereich unten herunterladen. Lesen Sie this, um zu erfahren, wie Sie das Projekt in Ihre Umgebung importieren können.
Konfiguration
Der Arbeitsablauf
Gliederung
Der Workflow dieses Showcases wurde mit dem Workflow-Editor von layline.io erstellt und sieht wie folgt aus:
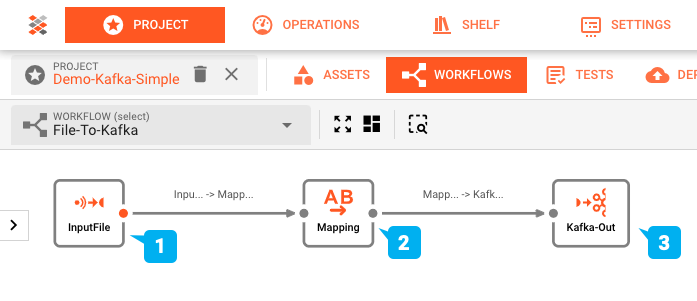
- (1) Eingabeprozessor: Einlesen einer Eingabedatei mit einer Header/Detail/Trailer-Struktur, dann
- (2) Flow Processor: Umwandlung in ein Ausgabeformat, das anschließend
- (3) Output Processor: Schreiben in ein Kafka-Thema.
Für diesen Showcase verwenden wir ein Kafka-Topic, das von Cloud Karafka (https://www.cloudkarafka.com/) gehostet wird. Wenn Sie den Showcase also selbst ausführen, benötigen Sie keine eigene Kafka-Installation.
Konfiguration der zugrunde liegenden Assets
Der Workflow basiert auf einer Reihe von zugrunde liegenden Assets, die mit dem Asset Editor konfiguriert werden. Die logische Verbindung zwischen Workflow und Assets kann wie folgt verstanden werden:
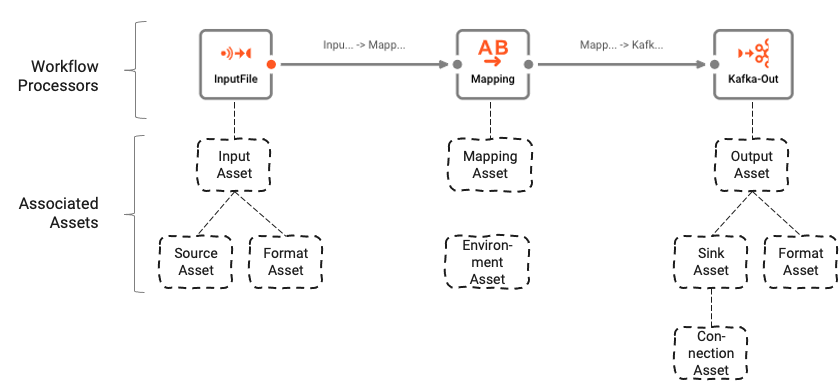
Workflows bestehen aus einer Reihe von Prozessoren, die durch Links miteinander verbunden sind.
Prozessoren basieren auf Assets (siehe Ressourcen für weitere Informationen). Assets sind Konfigurationseinheiten, die einer bestimmten Klasse und einem bestimmten Typ angehören. In der obigen Abbildung sehen wir einen Processor mit dem Namen "InputFile ", der der Klasse Input Processor und dem Typ Stream Input Processor angehört. Er stützt sich wiederum auf zwei andere Assets "Source Asset " und "Format Asset ", die vom Typ File System Source bzw. Generic Format sind.
Zusammengefasst:
- Ein Workflow besteht aus miteinander verbundenen Prozessoren
- Prozessoren stützen sich auf Assets, die sie definieren
- Assets können auf andere Assets zurückgreifen
In den folgenden Abschnitten zeigen wir
- die Anatomie des Workflows und einige wichtige Konfigurationen, und
- wie man den Workflow einsetzt und ausführt
Umgebung Asset: "Meine-Umgebung"
Erstens: layline.io kann mit Hilfe von Umgebungs-Assets mehrere verschiedene Umgebungen verwalten.
Dies ist sehr hilfreich, wenn das gleiche Projekt in Test-, Staging- und Produktionsumgebungen verwendet wird, die unterschiedliche Verzeichnisse, Verbindungen, Passwörter etc. erfordern.
Wir verwenden ein Environment Asset (2) in diesem Projekt. Schauen wir uns das mal an.
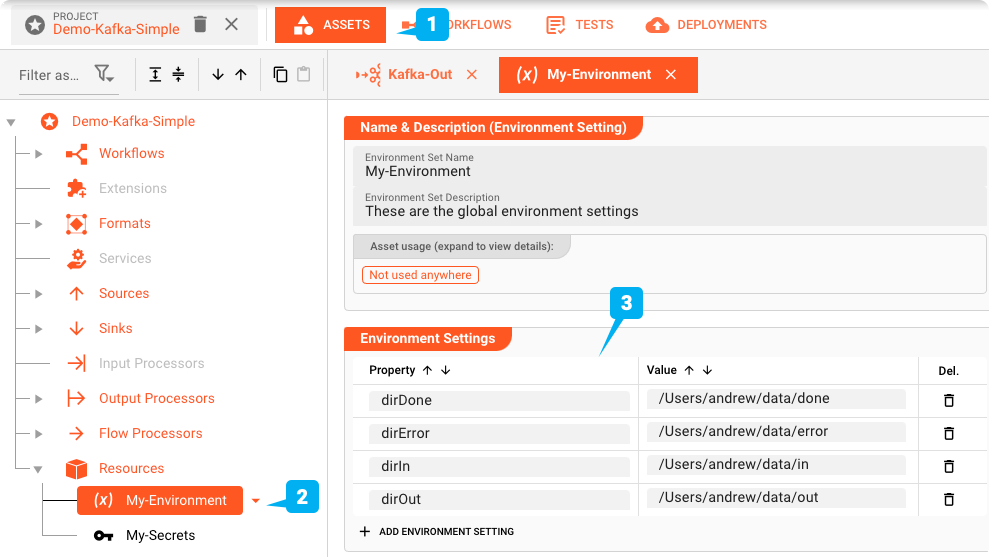
Unter (3) sehen Sie die Umgebungsvariablen, die wir erstellt haben. Falls Sie das Projekt selbst testen, müssen Sie die Werte wahrscheinlich so ändern, dass sie auf gültige Verzeichnisse von Ihnen verweisen, sonst erhalten Sie beim Start einen Fehler.
Variablen wie diese können im gesamten Projekt verwendet werden, indem man ein Makro wie ${lay:dirIn} verwendet.
Betriebssystem- oder Java-Systemumgebungsvariablen werden mit env: bzw. sys: vorangestellt, anstatt mit lay:.
Wenn Sie das Input Source Asset weiter unten untersuchen, werden Sie sehen, wie dies funktioniert und warum es wichtig ist, dass Sie sie an Ihre Umgebung
anpassen, um das Projekt auszuführen.
Sie können auch ein völlig neues Umgebungs-Asset neben dem mit dem Beispiel gelieferten erstellen und dann das Projekt zusammen mit Ihrem Umgebungs-Asset bereitstellen, wie wir im Abschnitt über
die Bereitstellung dieses Showcases sehen werden.
Stream Input Processor: "InputFile"
Der Input Processor (2) (Name: InputFile / Typ: Stream Input Processor) sorgt für das Einlesen der Eingabedateien und die Weiterleitung der Daten innerhalb des Workflows. Um seine Aufgabe zu erfüllen, muss der Input Processor wissen, wo die Daten zu lesen sind und wie der Inhalt zu interpretieren ist. Beide Informationsgruppen werden durch spezielle Assets (Source Asset und Format Asset) repräsentiert, die dem Input Asset zugeordnet sind:
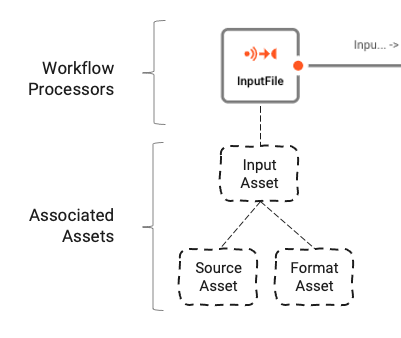
Schauen wir uns an, wie die unterstützenden Assets konfiguriert sind:
Generisches Format Asset: "InputFileFormat"
layline.io bietet die Möglichkeit, komplexe Datenstrukturen mit einer eigenen Grammatiksprache zu definieren. Die Datei in unserem Beispiel ist ein Beispiel für eine Banktransaktion. Sie besteht aus einem Header-Record mit zwei Feldern, einer Reihe von Detail-Records, die die Transaktionsdetails enthalten, und schließlich einem Trailer-Record. Insgesamt eine sehr gängige Dateistruktur.
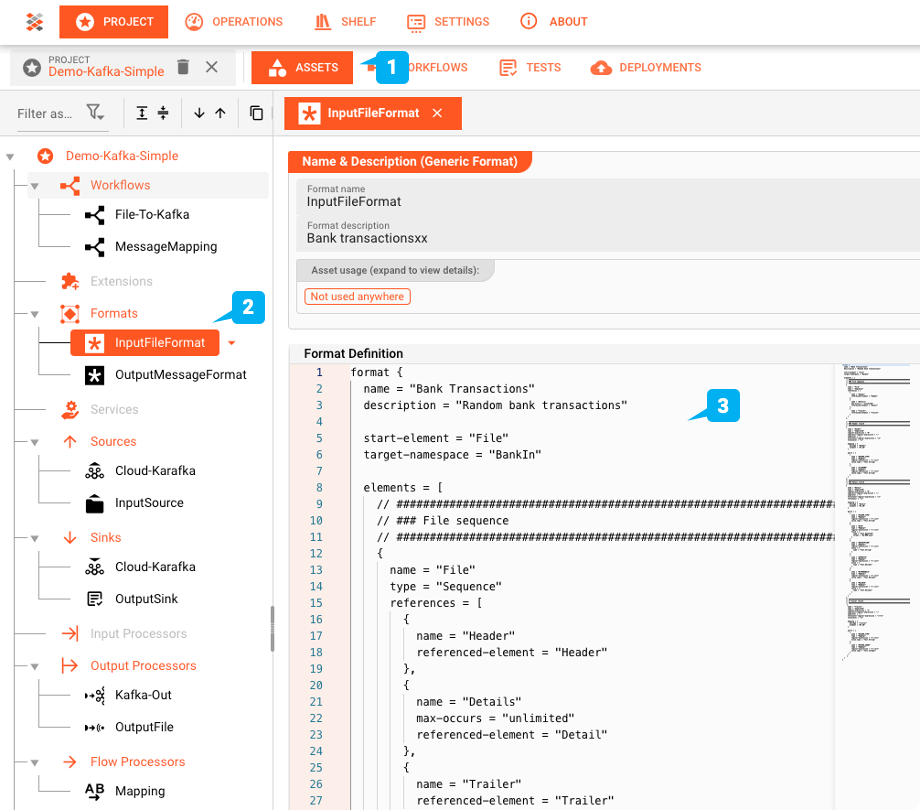
Alle Assets sind im Asset-Editor (1) zu finden. Das konfigurierte Generic Format Asset "InputFileFormat " ist in der Asset-Struktur auf der linken Seite des Editors zu finden.
Diese Formatkonfiguration wird im Dateisystem-Quell-Asset "InputSource " verwendet.
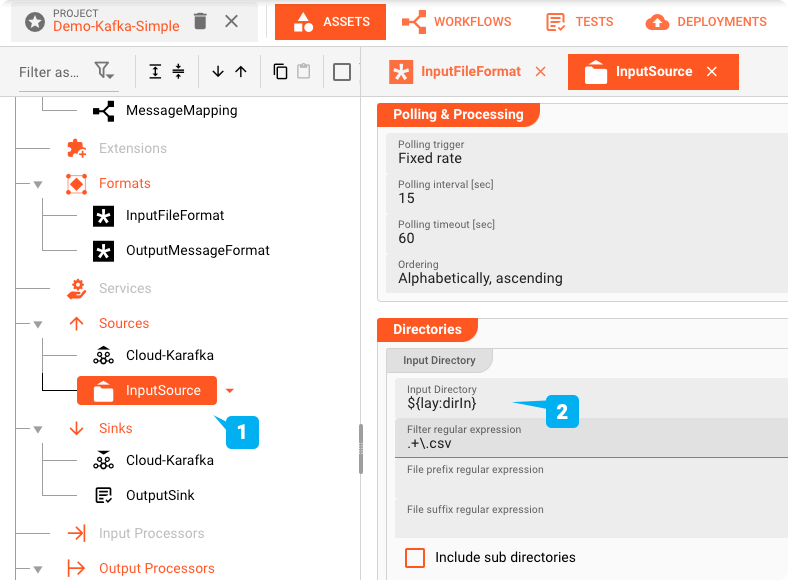
Dateisystem-Quell-Asset: "InputSource"
Das (1) "InputSource " ist ein Asset des Typs Dateisystemquelle, das verwendet wird, um zu definieren, woher die Datei gelesen wird. Es enthält Informationen über den Speicherort des Verzeichnisses für die Eingabe (2), Fehler und Beendigung (done) der Dateiverarbeitung, Abfrageintervalle, Dateisortierung, Fehlerverhalten und mehr.
Rückblick: Stream Input Processor "InputFile"
Wenn das Eingabeformat und die Eingabequelle Assets bereit sind, kann der Input File Processor (2) (vom Typ Stream Input Processor) im Workflow (1) definiert werden:
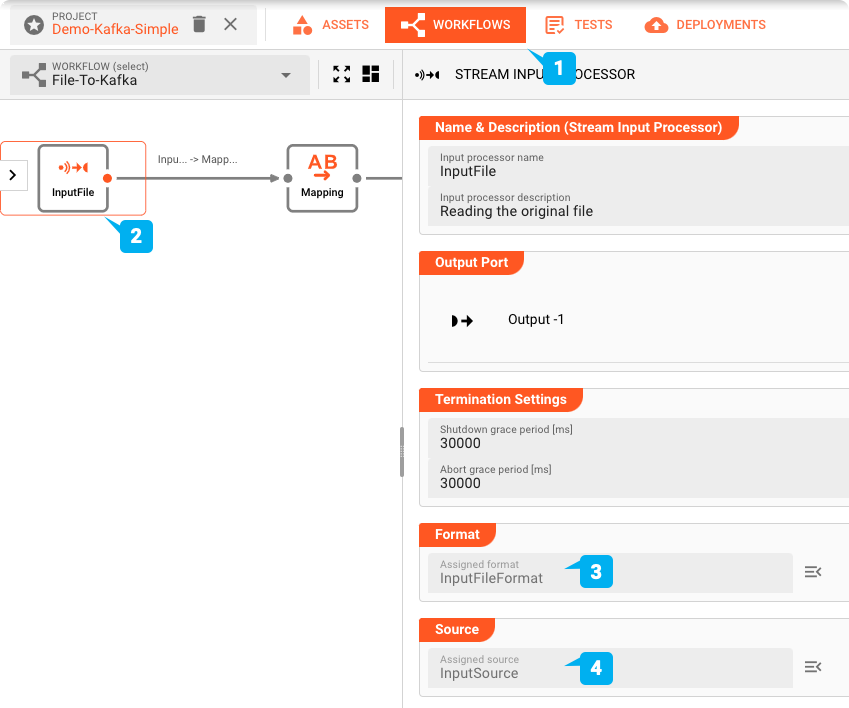
Die beiden zuvor definierten Assets "InputFileFormat " und "InputSource " werden diesem Prozessor zugewiesen ((3) und (4)). Abgesehen von einigen weiteren Parametern ist die Konfiguration des Prozessors "InputFile " (2) nun abgeschlossen.
Flow Processor: Map
Als nächstes definieren wir den Flussprozessor "Mapping", der auf einem Asset des Typs Mapping basiert, wie im nächsten Abschnitt definiert.
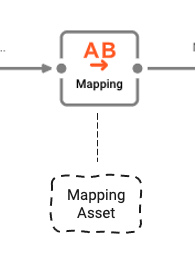
Vermögenswert: Mapping
Die Struktur der Datei, die wir lesen, entspricht nicht genau der Struktur dessen, was wir in Kafka schreiben. Daher müssen wir die Werte von der Eingabe zur Ausgabe mit einem entsprechenden Asset (1) zuordnen.
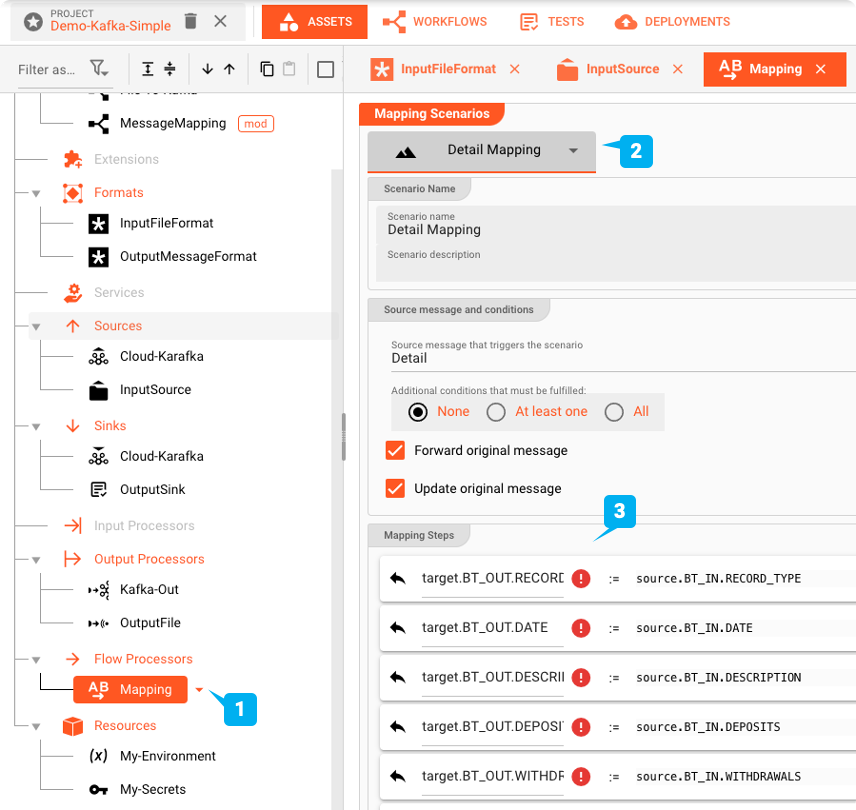
Wie bereits erläutert, besteht das Format der Eingabedatei aus einem Header, Details und einem Trailer Record. Das Gleiche gilt für das Ausgabeformat. Die obige Abbildung zeigt das Mapping vom Quell- (Input) zum Zielformat (Output) für die Detaildaten (2). Die verwendete Notation basiert auf der Definition der Eingangs- ("BT_IN") und Ausgangsgrammatik ("BT_OUT").
Stream Output Processor: Kafka
Der letzte Prozessor im Workflow, den wir definieren, ist der Output-Prozessor "Kafka-Out".
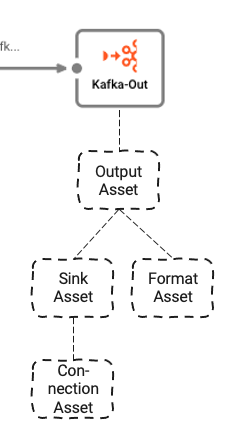
Sie hängt von drei zugrunde liegenden Vermögenswerten ab:
- Output Asset: Definiert die Kafka-Themen und -Partitionen, in die wir schreiben. Dies wiederum hängt von zwei weiteren Assets ab, nämlich
- Kafka-Sink-Asset**_: Der Sink, den das Output-Asset verwenden kann, um Daten zu senden
- Generic Format Asset: Definiert, in welchem Format die Daten in Kafka geschrieben werden sollen
- Kafka-Verbindungs-Asset**_: Definiert die physischen Kafka-Verbindungsparameter.
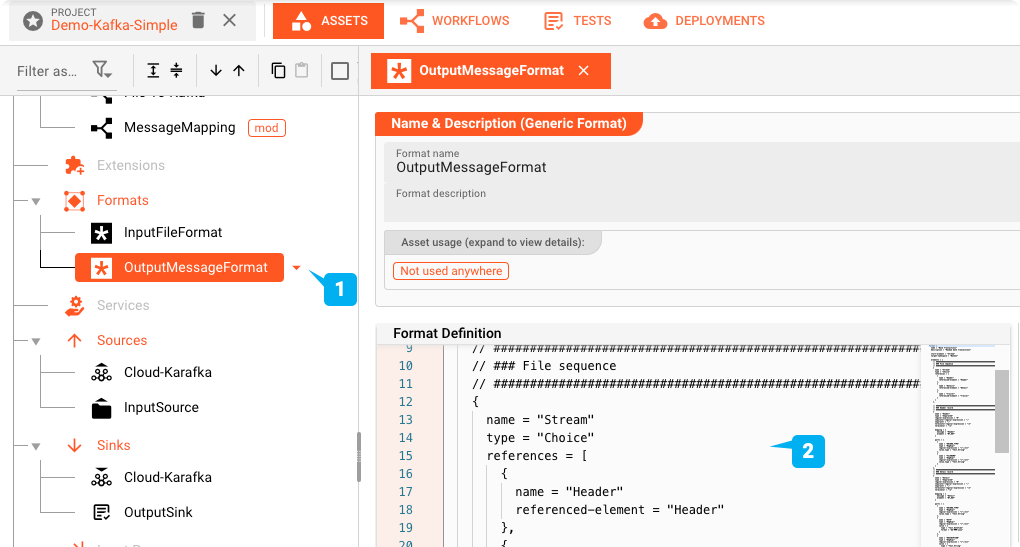
Generisches Format Asset: "OutputMessageFormat"
Die Daten, die wir an Kafka ausgeben wollen, ähneln der Eingabe, sind aber nicht völlig identisch. Wie beim input format definieren wir daher ein Asset vom Typ Generic Format und nennen es "OutputMessageFormat". Wir definieren die Grammatik analog zur Eingabegrammatik mit nur geringen Unterschieden (2).
Kafka-Verbindungs-Asset: "Cloud-Karafka-Verbindung"
Für die Ausgabe an Kafka müssen wir zunächst ein Kafka Connection Asset definieren. Hier legen wir fest, wie wir uns physisch mit Cloud Karafka verbinden.
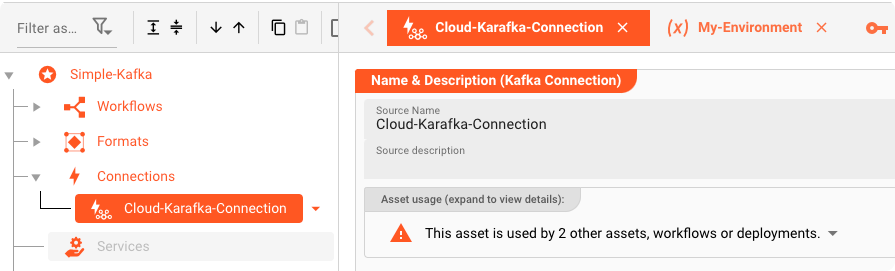
Der wichtigste Teil hier sind natürlich die Kafka-Einstellungen. Schauen wir sie uns genauer an:
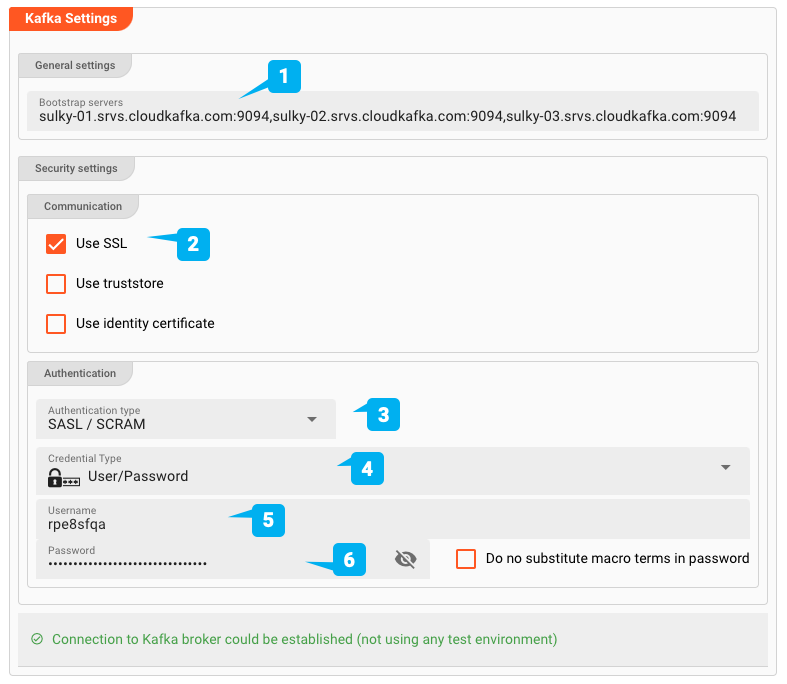
- (1) Bootstrap-Server: Die Adressen von einem oder mehreren Bootstrap-Servern. Für unser Karafka-Hosting sind sie definiert als sulky-01.srvs.cloudkafka.com:9094,sulky-02.srvs.cloudkafka.com: 9094,sulky-03.srvs.cloudkafka.com:9094.
- (2) SSL verwenden: Legt fest, ob es sich um eine SSL-Verbindung handelt. Für Cloud Karafka ist dies eine SASL/SCRAM-gesicherte Verbindung. Wir aktivieren daher SSL.
- (3) Authentifizierungstyp: Hier können Sie Keine, SASL / Klartext oder SASL / SCRAM wählen. Cloud Karafka erfordert SASL/SCRAM
- (4) Zertifikatstyp: Sie haben die Wahl zwischen Benutzer/Geheimnis und Benutzer/Passwort. In unserem Fall haben wir der Einfachheit halber Benutzer/Passwort verwendet.
- (5/6) Benutzername/Kennwort: Der richtige Benutzername und das richtige Passwort sind im Showcase-Projekt enthalten, das Sie im Abschnitt Ressourcen herunterladen können.
Kafka Sink Asset: "CloudKarafka"
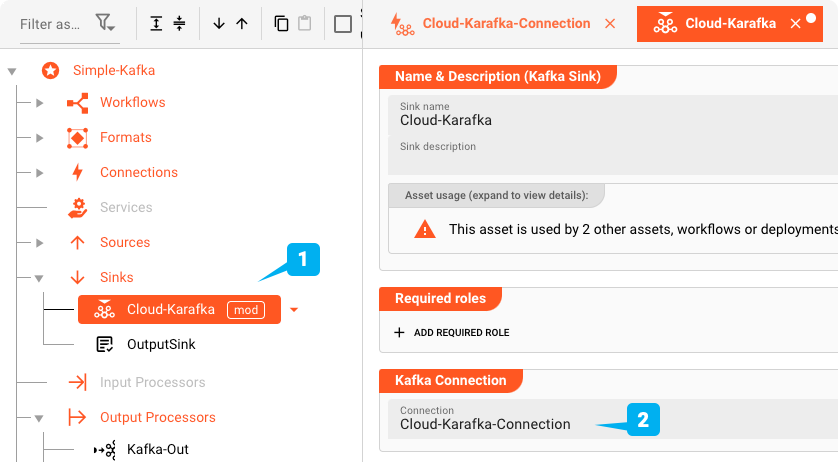
Als nächstes definieren wir ein Kafka-Sink-Asset. Das Kafka-Sink-Asset verwendet die Kafka-Verbindung, die wir gerade definiert haben. Es ist jedoch nicht der Ort, an dem wir definieren, welches Topic ausgegeben werden soll.
Stellen Sie sicher, dass die zuvor definierte Kafka-Verbindung zugewiesen ist (2).
Rückblick: Kafka Output Processor "Kafka-Out"
Nachdem wir oben die Format- und Sink-Assets definiert haben, können wir nun das Kafka-Output-Asset im Workflow definieren (1):
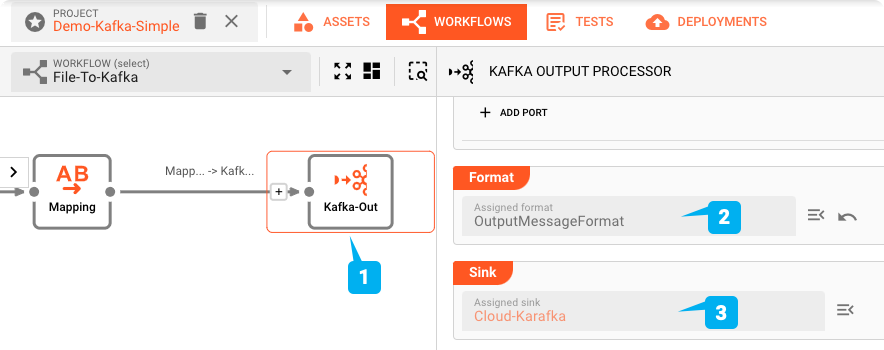
Prüfen Sie, wie sowohl das Format OutputMessageFormat (2) als auch die Senke (3) diesem Prozessor zugeordnet sind.
Zusätzliche Einstellungen:
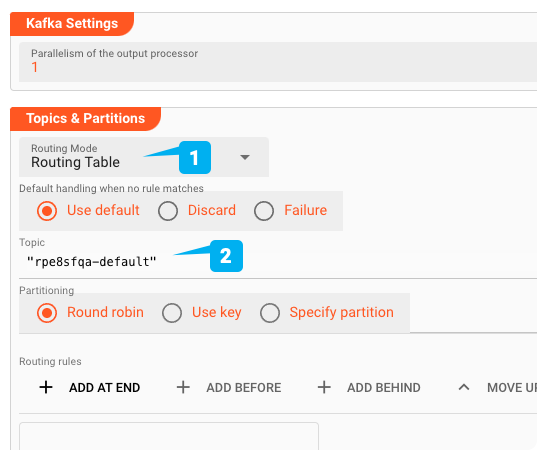
- Routing-Modus: Sie haben die Wahl zwischen Routing Table und Exclusive Partition. In diesem Fall ist Routing Table geeignet, da wir für diesen Showcase keinen exklusiven Partitionszugang benötigen.
- Thema: Name des Themas, in das wir schreiben.
Es gibt noch weitere Optionen, die wir setzen können, die aber für den Zweck der Demo nicht relevant sind. Sie können sie in der Online-Dokumentation nachschlagen.
Config Zusammenfassung
Damit ist die Konfiguration des Workflows abgeschlossen.
Deploy & Run
Übertragen der Bereitstellung
Wir sind bereit, den Workflow zu testen. Dazu müssen wir ihn auf einen Reactive Engine Cluster übertragen. Sie können einfach den Cluster auf Ihrem Laptop verwenden (einzelner Knoten). Oder wenn Sie anderswo einen größeren layline.io-Cluster haben, können Sie ihn dort bereitstellen.
Zum Deployment wechseln wir auf den Reiter DEPLOYMENT des Projekts (1):
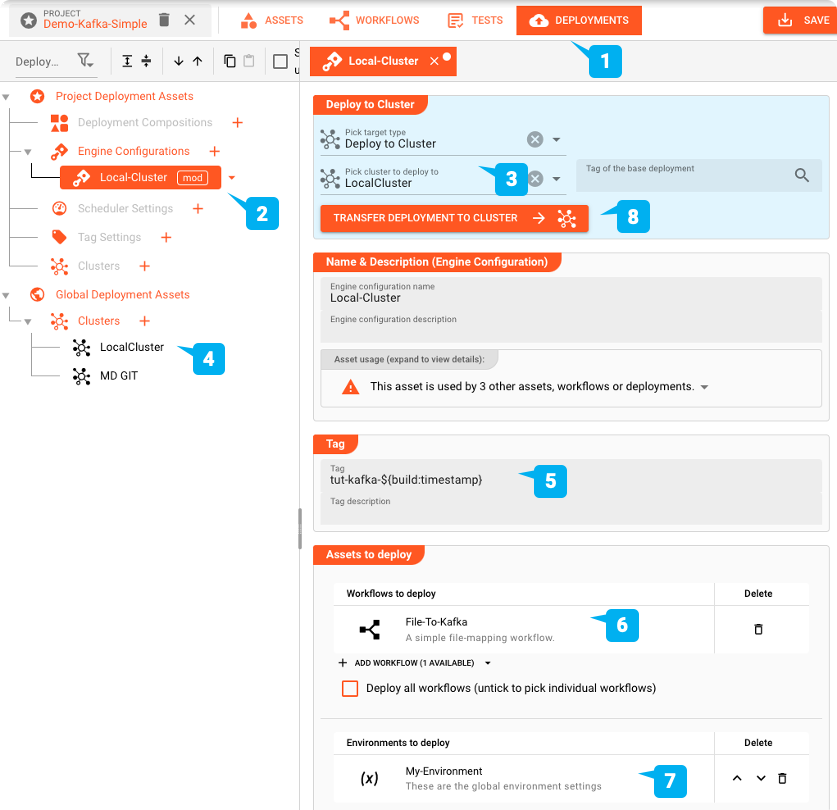
Wir erstellen eine Engine-Konfiguration (2) für die Bereitstellung des Projekts. Diese definiert die Teile des Projekts, die wir bereitstellen möchten. In unserem Beispiel wäre das der eine Workflow, den wir definiert haben, sowie das dazugehörige Environment Asset.
Da wir das Projekt im lokalen Cluster bereitstellen wollen, wählen wir "Deploy to Cluster" und dann unser vordefiniertes "Local Cluster" Setup (3 und 4).
Jede Bereitstellung benötigt einen Tag (5). Wir verwenden "tut-kafka-" gefolgt von einem Makro "${build-timestamp}", um das Deployment zu identifizieren. Das Makro wird bei der Übertragung des Deployments durch einen Zeitstempel ersetzt. Auf diese Weise wird sichergestellt, dass wir mit jeder Bereitstellung immer ein anderes Tag erhalten.
Vergewissern Sie sich, dass der soeben erstellte Workflow in die Liste der "Assets to deploy" (6) aufgenommen wurde, da sonst nichts bereitgestellt wird.
Wir benötigen auch die Umgebungsvariablen, die wir im Quell-Asset verwenden, um die Verzeichnisse zu definieren, aus denen wir lesen (7).
Schließlich starten wir die Übertragung der Bereitstellung durch Klicken auf "TRANSFER DEPLOYMENT TO CLUSTER" (8) (Vergewissern Sie sich, dass der Cluster, für den Sie die Bereitstellung vornehmen, in Betrieb ist).
Wenn die Bereitstellung erfolgreich war, sollten Sie dies sehen:
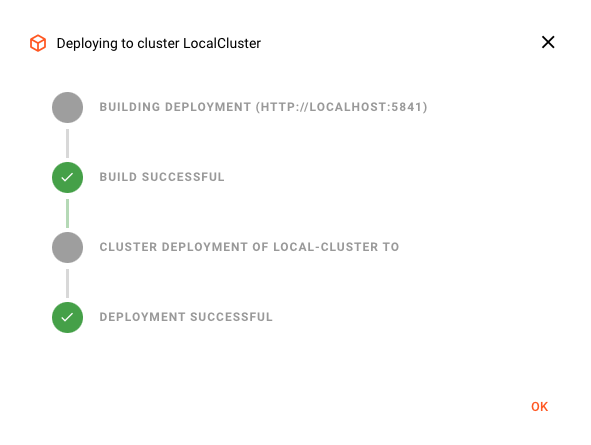
Andernfalls wird eine Fehlermeldung angezeigt, die Sie anleitet, wie Sie das Problem beheben können.
Aktivieren der Bereitstellung
Wir sollten nun bereit sein, die Bereitstellung zu aktivieren. Dazu wechseln wir auf die Registerkarte "CLUSTER" (1). Hier erhalten wir einen Überblick über alle "Cluster". Falls Sie mehr als einen Cluster verwalten, vergewissern Sie sich, dass Sie in der Dropdown-Box oben links den richtigen ausgewählt haben.
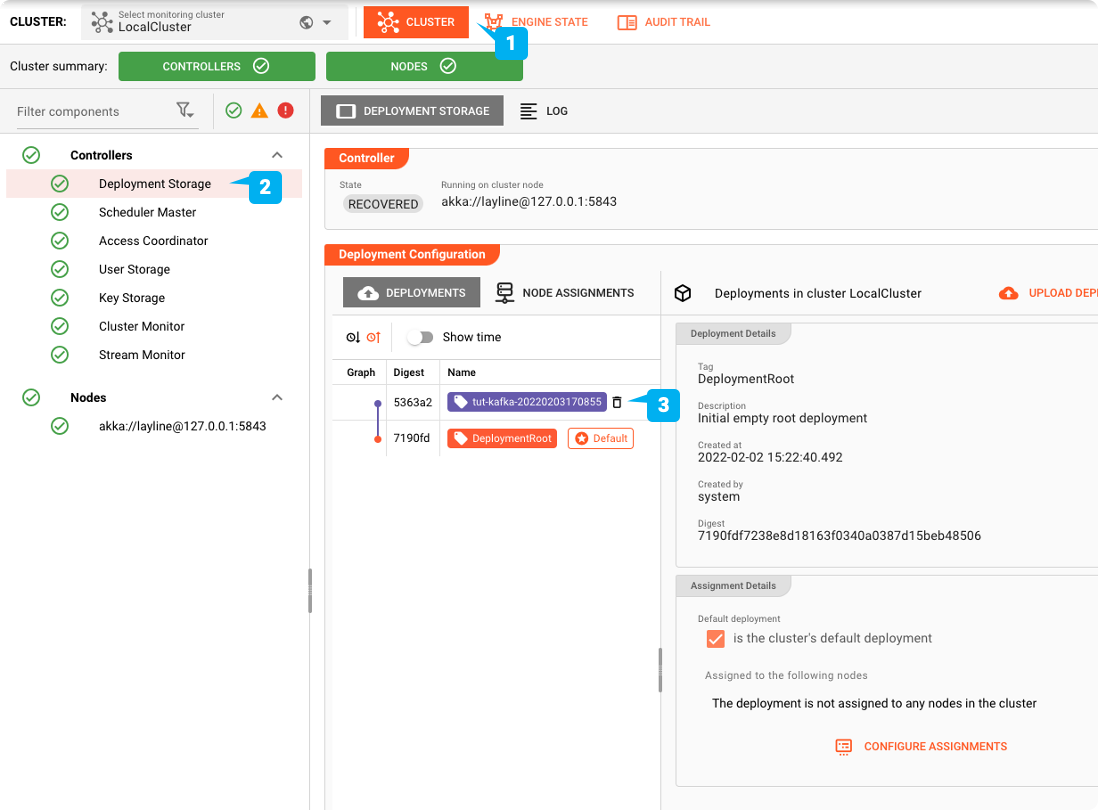
Machen Sie sie zur Standardbereitstellung
Wählen Sie in der Baumstruktur auf der linken Seite "Einsatzspeicher".
Hier finden wir alle Einsätze, die dem ausgewählten Cluster derzeit bekannt sind.
In unserem Beispiel-Screenshot sehen wir im Abschnitt "Einsatzkonfiguration"
- "EinsatzRoot": Dies ist die grundlegende leere Standardbereitstellung, die immer vorhanden ist.
- "tut-kafka-20220204184304": Dies ist das Deployment, das wir gerade in den Cluster übertragen haben.
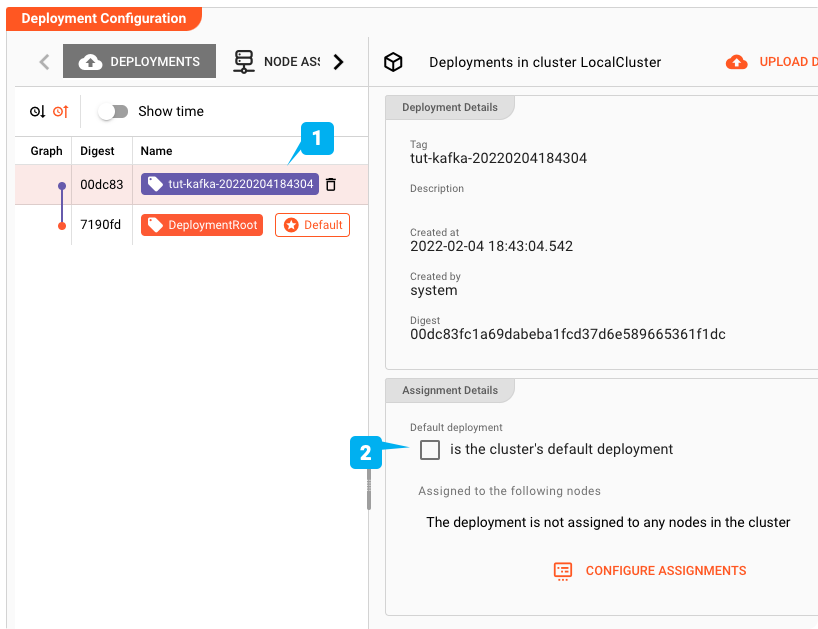
Um nun das neue Deployment auf dem Cluster zu aktivieren, wählen Sie es aus (1) und aktivieren Sie das Kästchen "is the cluster's default deployment" (2).
Zeitplan
Jetzt, da die Bereitstellung auf dem Cluster aktiv ist, müssen wir überprüfen, ob tatsächlich Instanzen des Workflows ausgeführt werden. Wenn Sie diesen Workflow zum ersten Mal bereitstellen, lautet die Antwort wahrscheinlich "nein".
Lassen Sie uns das überprüfen:
- Wählen Sie die Registerkarte "Cluster" (1)
- Wählen Sie den Eintrag "Scheduler Master" in der Baumstruktur auf der linken Seite (2)
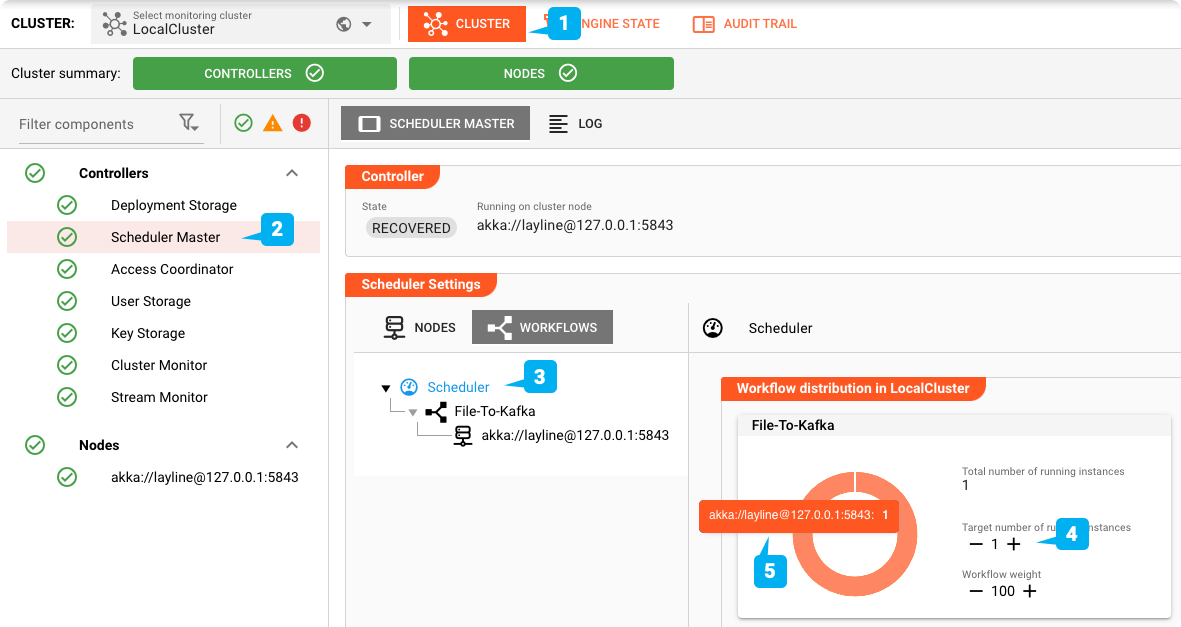
- Wählen Sie in der Box Scheduler Settings den Knoten Scheduler in der Baumstruktur (3)
- Vergewissern Sie sich anschließend, dass die Zielanzahl der Instanzen auf mindestens 1 gesetzt ist (4). Wenn Sie eine höhere Zahl einstellen, werden mehr Instanzen desselben Workflows gestartet.
Sie müssen dies nur einmal tun. Wenn Sie den Workflow das nächste Mal bereitstellen, merkt sich die Reactive Engine die Anzahl der Instanzen, die Sie mit diesem Workflow starten möchten. Sie können auch die gewünschten Scheduler-Einstellungen als Teil eines Deployments definieren. Das ist aber ein Thema für einen anderen Showcase.
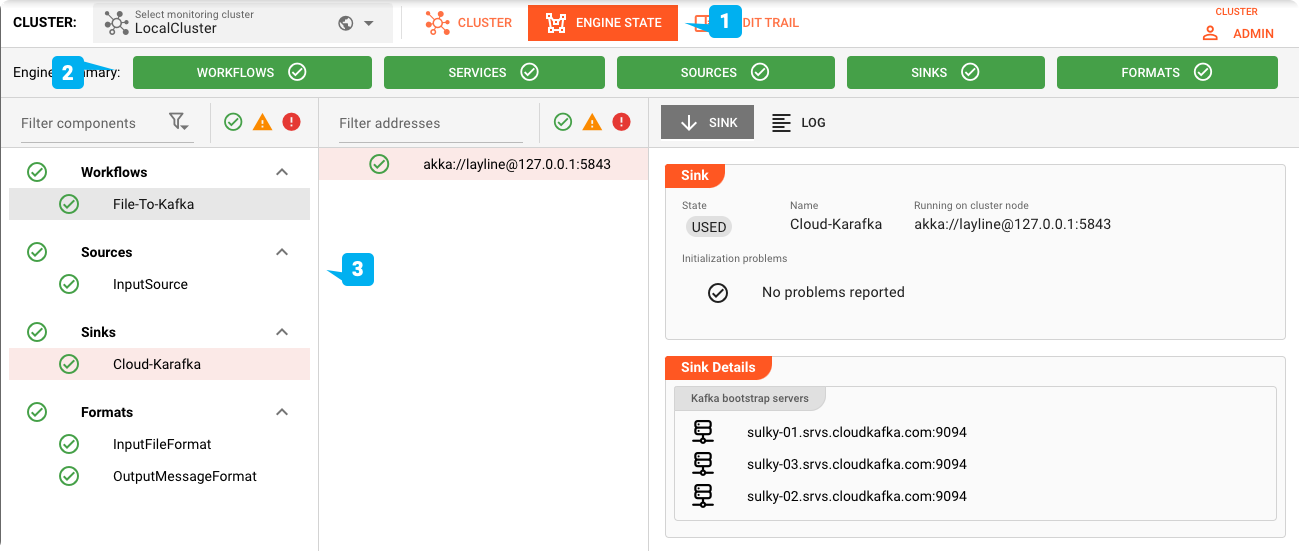
Engine-Status
Wechseln Sie auf die Registerkarte "Engine" (1). Stellen Sie sicher, dass alle Engine-Kategorien grün sind (2). Überprüfen Sie auch den Status der einzelnen Assets in der Baumstruktur auf der linken Seite (3).
Einspeisen der Testdatei
Zum Testen füttern wir unsere Testdatei in das Eingabeverzeichnis, das wir hier konfiguriert haben.
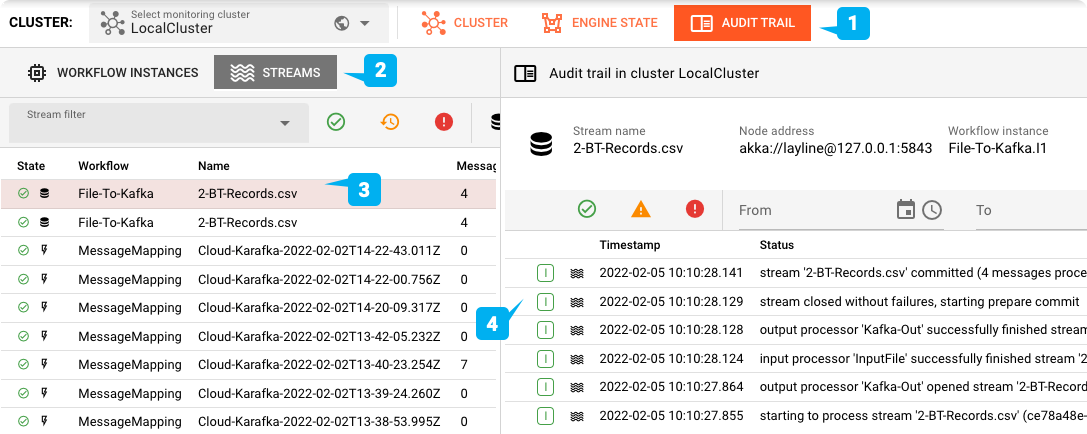
Um dann zu überprüfen, ob die Verarbeitung erfolgreich war, wechseln Sie zur Registerkarte "Audit Trail" (1). Stellen Sie sicher, dass Sie "Streams" (2) sehen. Markieren Sie den ersten Eintrag in der Liste (3). Dort sollte stehen, dass vier Nachrichten verarbeitet wurden. Vergewissern Sie sich, dass der Zeitstempel des Eintrags mit dem Zeitpunkt übereinstimmt, zu dem Sie die Eingabedatei im Verzeichnis zur Verarbeitung abgelegt haben. Sie können die einzelnen Protokolleinträge für die Verarbeitung dieser Datei auf der rechten Seite einsehen (4).
Sie können das Cloud-Karafka-Thema (Anmeldeinformationen in der Ressource am Ende des Dokuments) mit einem Tool Ihrer Wahl überprüfen, um die Themeneinträge zu prüfen:

Zusammenfassung
Dieser Showcase zeigt, wie Sie einen File-to-Kafka Workflow on-the-fly ohne großen Aufwand erstellen können. Und Sie erhalten noch viel mehr mit diesem Out-of-the-Box: Reaktiv - Umfasst das Paradigma der reaktiven Verarbeitung. Vollständig auf reaktiver Stream-Verwaltung aufbauend
- Hohe Skalierbarkeit -- Skaliert innerhalb einer Engine-Instanz und darüber hinaus über mehrere Engines und verteilte Knoten Ausfallsicherheit -- Failover sicher in verteilten Umgebungen. Vollständiger 24/7-Betrieb und Upgrademöglichkeit
- Automatische Bereitstellung -- Bereitstellung geänderter Konfigurationen mit einem Klick
- Echtzeit und Batch** -- Führen Sie sowohl Echtzeit- als auch Batch-Datenintegrationen über dieselbe Plattform aus
- Metriken -- Automatische Generierung von Metriken zur Verwendung in Ihrem bevorzugten Überwachungs- und Alarmierungs-Toolkit (z.B. Prometheus)
Es gibt zu viele Funktionen, um sie hier zu erklären. Weitere Informationen finden Sie in der Dokumentation oder kontaktieren Sie uns einfach unter hello@layline.io.
Vielen Dank für die Lektüre!
Ressourcen
| # | Projektdateien |
|---|---|
| 1 | Github: Simple Kafka Project |
| 2 | Eingabetestdateien im Verzeichnis _test_files des Projekts |
| 3 | Cloud-Karafka-Anmeldeinformationen in der Datei cloud-karafka-credentials.txt des Projekts |
| # | Documentation |
|---|---|
| 1 | Getting Started |
| 2 | Importing a Project |
| 3 | What are Assets, etc? |
- Erfahren Sie hier mehr über layline.io.
- Kontaktieren Sie uns hello@layline.io.