layline.io Blog
Verdammt sei die Datenformat-Hölle.
Der Umgang mit komplexen Datenformaten und -änderungen kann entmutigend sein. Erfahren Sie, wie layline.io diese Herausforderung mit einer konfigurierbaren Grammatiksprache meistert.
Reading time: 10 min.
Einstellung
Sie sind der Mann/die Frau, der/die sich um die Datenverarbeitungsinfrastruktur der ACME Corp. kümmert und diese betreibt. Das ist die komplexe und empfindliche Maschinerie, die die ganze schwere Datenarbeit in Ihrem Unternehmen erledigt, aber nie eine Belohnung dafür erhält. Es ist die Pumpe, die nicht aufhören darf zu pumpen, es ist der Saft, der die Dinge am Laufen hält.
Doch wenn Ihre Eltern, Freunde oder sogar Kollegen Sie fragen, was Sie bei ACME tun, schlafen sie mitten in Ihrer begeisterten Erklärung ein.
Machen wir uns nichts vor: Du bekommst nicht genug Anerkennung für das, was du für die Welt tust 🙃.
Herausforderungen
In Ihrem Job müssen Sie zwar nicht in einem Mechaniker-Outfit herumlaufen, aber es fühlt sich so an, als müssten Sie ständig beobachten, ausbessern, korrigieren oder einfach nur neuen Schwung in die datenverarbeitende Infrastruktur bringen.
Es gibt zwar viele alltägliche Herausforderungen, aber eine davon ist die VERÄNDERUNG. Man sagt zwar, dass man niemals ein laufendes System ändern sollte, aber so ist die Welt nicht. Eine der häufigeren Änderungen ist ...
Änderung des Datenformats
AAHHHH! Roter Alarm ... Sirenen ertönen ...! Wenn es um die Änderung von Datenformaten geht, kommen oft mehrere Herausforderungen gleichzeitig auf uns zu:
- Datenschnittstellen sind oft fest in einem Quellcode kodiert. Man kann sie nicht einfach "ändern" (wie der Chef vorschlägt), oder zumindest ist es nicht so einfach.
- Während der Migration werden die Daten sowohl im alten als auch im neuen Format empfangen. Selbst mit einer kleinen Änderung sind das immer noch zwei verschiedene Formate, die parallel verarbeitet werden müssen.
- Es geht nicht nur um ein weiteres Feld. Manchmal handelt es sich um eine ganz neue Datenstruktur und eine Reihe anderer Dinge, die gleichzeitig bearbeitet werden müssen.
- Geänderte Daten erfordern möglicherweise die interne Verarbeitung zusätzlicher Informationen usw. Auch hier kann es sein, dass einige Dinge fest kodiert sind und daher der Code geändert werden muss, um sie zu berücksichtigen.
- Sie haben keinen Kaffee mehr. Das ist keine Hilfe.
Wir haben hier zwei Hauptprobleme, nämlich
- Änderung des Codes und
- Handhabung der Formatmigration.
Dies kann ziemlich viel Kopfzerbrechen bereiten und lange Zyklen der Planung, Entwicklung, Freigabe, Prüfung und schließlich Bereitstellung erfordern.
Wenn es nur einen besseren Weg gäbe, dies schnell und einfach zu erledigen ...
Generische Datenformate als Retter
Natürlich ist dies ein Blog über layline.io und wie großartig es ist, falls Sie das noch nicht wussten (siehe unten). Werfen wir also einen Blick darauf, wie layline.io diese Herausforderung angeht:
layline.io bietet Generische Datenformate, die nicht alle, aber die meisten der oben genannten Herausforderungen lösen können.
Was sind generische Datenformate?
Wie der Name schon sagt, erlaubt dieses Konzept, Datenformate auf generische Weise zu definieren. Zu diesem Zweck bietet es
- eine Sprache, um die Struktur (Grammatik) des Formats zu definieren, um das Sie sich bemühen.
- Diese Sprache verwendet reguläre Ausdrücke, um einzelne Elemente einer Struktur zu definieren und zu identifizieren, und dann
- die Unterelemente dieser Struktur, usw..
- Sie ist insofern objektorientiert, als dass man Element-Strukturen durchgängig definieren und wiederverwenden kann.
Wie sieht diese Sprache aus?
Schauen wir uns das mal an. Zu diesem Zweck werden wir mit einem supereinfachen Datenformat arbeiten, das kommagetrennt ist, einen Header-Datensatz, 1..n Detail-Datensätze und einen Trailer-Datensatz haben muss. Ein Format, das wir alle auf die eine oder andere Weise kennen.
Beispieldaten für ein einfaches Bank-Transaktionsprotokoll:
H;Sample Bank Transactions
D;20-Aug-2021;NEFT;23237.00;00.00;37243.31
D;21-Aug-2021;NEFT;00.00;3724.33;33518.98
T;100
Und hier ist, wie dieses Format in layline.io unter Verwendung der generischen Grammatiksprache definiert wird:
format
{
name = "Bank Transactions"
description = "Random bank transactions"
start - element = "File"
target - namespace = "BankIn"
elements = [
// #####################################################################
// ### File sequence
// #####################################################################
{
name = "File"
type = "Sequence"
references = [
{
name = "Header"
referenced-element = "Header"
},
{
name = "Details"
max-occurs = "unlimited"
referenced-element = "Detail"
},
{
name = "Trailer"
referenced-element = "Trailer"
}
]
},
// #####################################################################
// ### Header record
// #####################################################################
{
name = "Header"
type = "Separated"
regular-expression = "H"
separator-regular - expression = ";"
separator = ";"
terminator-regular - expression = "\n"
terminator = "\n"
mapping = {
message = "Header"
element = "BT_IN"
}
parts = [
{
name = "RECORD_TYPE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
},
{
name = "FILENAME"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
}
]
},
// #####################################################################
// ### Detail record
// #####################################################################
{
name = "Detail"
type = "Separated"
regular-expression = "D"
separator-regular - expression = ";"
separator = ";"
terminator-regular - expression = "\n"
terminator = "\n"
mapping = {
message = "Detail"
element = "BT_IN"
}
parts = [
{
name = "RECORD_TYPE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
},
{
name = "DATE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value = {
type = "Text.DateTime"
format = "dd-MMM-uuuu"
}
},
{
name = "DESCRIPTION"
type = "RegExpr"
regular-expression = "[^;\n]*"
value = {
type = "Text.String"
}
},
{
name = "DEPOSITS"
type = "RegExpr"
regular-expression = "[^;\n]*"
value = {
type = "Text.Decimal"
}
},
{
name = "WITHDRAWALS"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.Decimal"
},
{
name = "BALANCE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value = {
type = "Text.Decimal"
}
}
]
},
// #####################################################################
// # Trailer record
// #####################################################################
{
name = "Trailer"
type = "Separated"
regular-expression = "T"
separator-regular - expression = ";"
separator = ";"
terminator-regular - expression = "\r?\n"
terminator = "\n"
mapping = {
message = "Trailer"
element = "BT_IN"
}
parts = [
{
name = "RECORD_TYPE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
},
{
name = "RECORD_COUNT"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.Integer"
}
]
}
]
}
Sie ist ziemlich selbsterklärend und sieht einer JSON-formatierten Datei sehr ähnlich. Aber auf den zweiten Blick ist es kein JSON. Schauen wir uns einige Details an.
Das "Format"-Element
Alles beginnt mit dem Top-Level-Element "format":
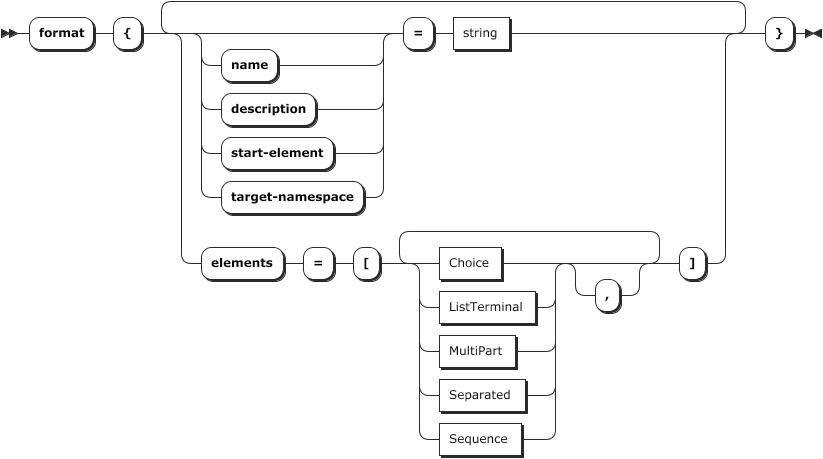
Neben einem "Namen" und einer "Beschreibung" hat es auch eine Reihe von "Elementen". Diese Elemente definieren eine Reihe von Unterelementen (Klassen), die von unterschiedlichem Typ sein können und die dann das gesamte Format bilden. In unserem Beispiel ist dies nur ein Element mit dem Namen "File" und dem Typ "Sequence".
Das File-Element vom Typ Sequence
Dieses Element definiert eine logische Struktur von Unterelementen in seiner references Struktur mit den Namen "Header", "Detail", und "Trailer".
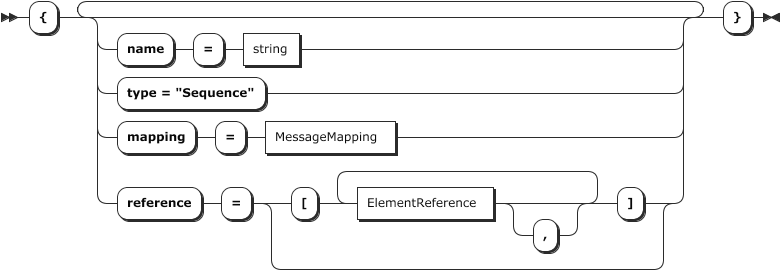
Sie können vielleicht erkennen, dass wir hier einen Baum bauen:
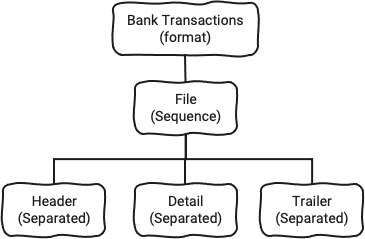
Das Header Element vom Typ Separated
Bislang hatten wir nur logische Elemente, die eine Struktur definieren. Das Element Header vom Typ Separated definiert nun zum ersten Mal, wie Daten in der Datei tatsächlich identifiziert werden
können.
...
// #####################################################################
// ### Header record
// #####################################################################
{
name = "Header"
type = "Separated"
regular - expression = "H"
separator - regular - expression = ";"
separator = ";"
terminator - regular - expression = "\n"
terminator = "\n"
mapping = {
message = "Header"
element = "BT_IN"
}
...
Ein Element des Typs Separated hat eine Eigenschaft regular-expression, die zur Angabe eines regulären Ausdrucks (tataa!) zur Identifizierung des Elements im Datenstrom verwendet wird. In unserem
Fall ist dies einfach "H", um einen Header-Datensatz zu identifizieren. Siehe die Beispieldatei oben. Es hat auch einen terminator-regular-expression, der auf "\n" gesetzt wird, um das Ende des
Elements zu markieren. In unserem Fall ist das resultierende Element dann eine ganze Zeile von "H" bis zum Zeilenvorschub am Ende der ersten Zeile.
H;Sample Bank Transactions
...
Sie verstehen die Idee.
Der "Mapping"-Teil teilt layline.io mit, wie dieses Element in einem layline.io Workflow referenziert werden kann, sobald die Daten geparst sind. Dazu kommen wir etwas später.
Außerdem finden wir in der Header-Deklaration:
...
parts = [
{
name = "RECORD_TYPE" // name of the element
type = "RegExpr" // pick a type
regular-expression = "[^;\n]*" // this is how we identify the first field (element)
value.type = "Text.String" // this is the field type
},
{
name = "FILENAME"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
}
]
...
Hier werden nun einzelne Teile (wiederum Elemente) des Headers definiert. Im Fall des Headers sind das die beiden Elemente RECORD_TYPE und FILENAME. Beide sind vom Typ RegExpr, was bedeutet,
dass sie wiederum durch einen regulären Ausdruck innerhalb des Header-Datensatzes identifiziert werden können. Es gibt zwei weitere Typen Calculated und Fixed zur Auswahl.
Die Elemente Detail und Trailer vom Typ Separated
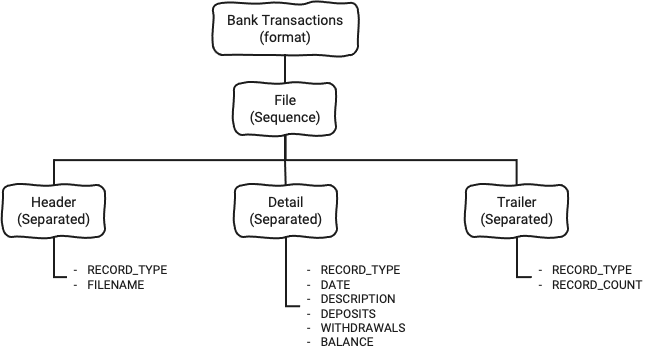
Wie beim Header fahren wir einfach damit fort, die Struktur mit den Detail- und Trailer-Elementen zu definieren, auf die wir in der obigen File-Sequence verwiesen haben.
Am Ende erhalten wir eine fertige Struktur wie diese:
Vorläufige Schlussfolgerung
Wir haben gelernt, dass die Grammatik folgendermaßen funktioniert:
- Eine Grammatik besteht aus einer Reihe von Elementen,
- Diese Elemente gibt es in verschiedenen Arten, die unterschiedlichen Zwecken dienen,
- Das erste Element ist
format, das auf ein Startelement verweist, das Sie ebenfalls definieren, - Sie können eine beliebige Anzahl von zusätzlichen Elementen definieren,
- Einige Elemente können dann auf andere Elemente verweisen. Elemente können als wiederverwendbare Klassen betrachtet werden.
Das bietet EINE MENGE an Möglichkeiten, wie eine Grammatik auf reale Datenformate abgebildet werden kann
Wie sieht es mit anderen, komplexeren Formaten aus?
Wir wissen natürlich, dass die Datenformate in IHRER Welt nicht so einfach sind wie das, das wir in unserem Beispiel gewählt haben. Hier ist, was sonst noch funktioniert:
- Sehr komplexe ASCII/Unicode-Formate, z.B. alle Arten von verschiedenen Satztypen, hierarchische Strukturen.
- Bedingtes Parsen von Daten durch Verwaltung des bedingten Parser-Status, z.B. "Satztyp B darf nur direkt nach A kommen".
- Binäre Strukturen.
- Eine Mischung aus ASCII- und Binärformaten.
Wir glauben, dass dies mehr als 80% aller Datenaustauschformate abdeckt. Es gibt natürlich immer noch andere, wie z.B. ASN.1-basierte Formate u.a. layline.io verfügt auch über andere, bessere Parser für diese Typen.
Unterstützung mehrerer Formate
Sie können beliebig viele Formate definieren. layline.io kompiliert alle Formate zur Laufzeit zu einem "Superformat". Dadurch können Sie
- alle Formate von überall referenzieren,
- Daten von einem Format auf ein anderes abbilden,
- neue Nachrichteninstanzen auf Basis eines bestimmten Formats zu erzeugen,
- einzelne Elementstrukturen innerhalb einer Nachricht erstellen oder zerstören und
- Daten in jedem der definierten Formate einlesen oder ausgeben.
Wo konfiguriere ich das alles?
Um Sie nicht noch mehr zu verärgern, haben wir eine schöne Benutzeroberfläche bereitgestellt, die Ihnen bei der Konfiguration hilft und Sie aufmuntert. Sie finden diese im webbasierten layline.io
Configuration Center unter Projekt --> Formate --> Generisches Format:
Hier geben Sie die gesamte Grammatik ein:
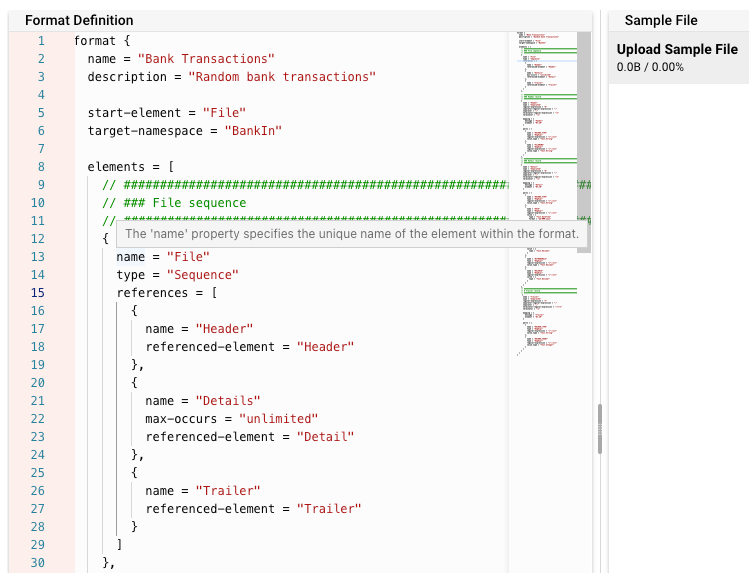
Und das ist noch nicht alles. Während Sie Ihre Grammatik definieren, können Sie eine Beispieldatei hochladen und Seite an Seite sehen, ob Ihre Grammatik mit der Dateistruktur übereinstimmt:
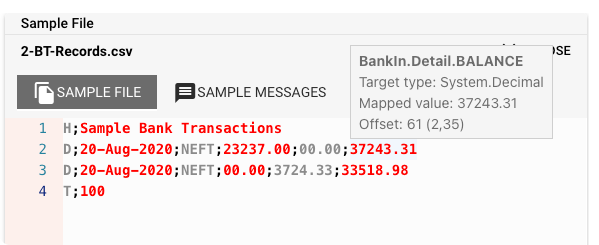
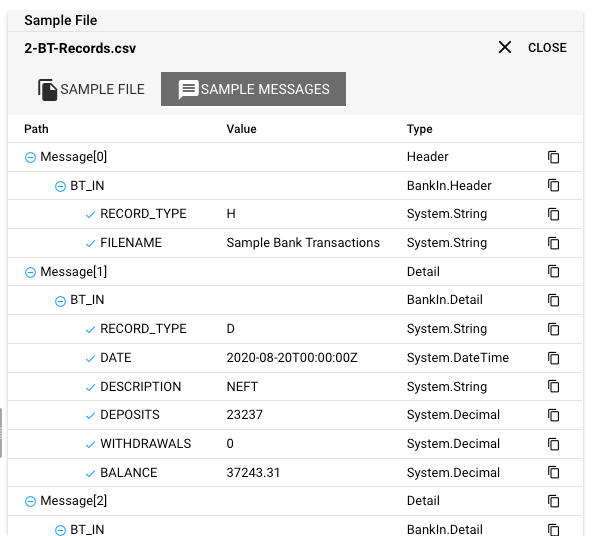
Ziemlich cool, oder?
Referenzierung von Daten innerhalb der Logik
Es macht keinen Sinn, Grammatiken zu definieren, wenn Sie nicht vorhaben, Daten innerhalb Ihrer Verarbeitungskette zu referenzieren und ggf. zu manipulieren. Nachdem Sie eine oder mehrere Grammatiken in layline.io definiert haben, können Sie auf einzelne Elemente und Strukturen innerhalb dieser Grammatiken zugreifen wie folgt:
Beispiel: Datenzugriff im Mapping-Asset
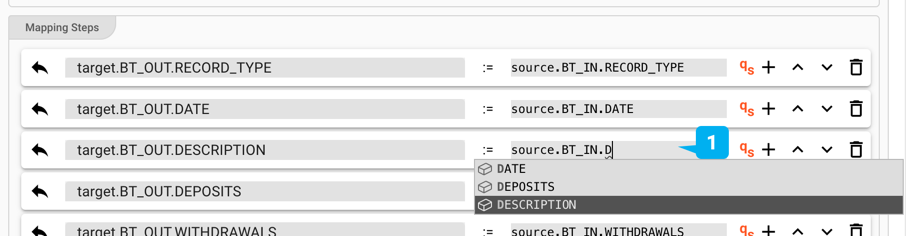
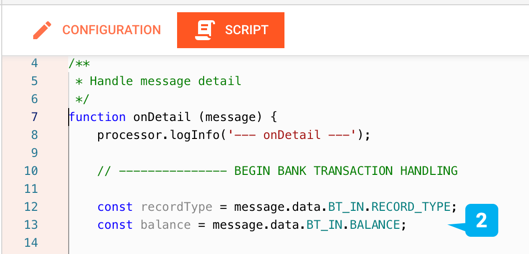
Beispiel: Datenzugriff in Javascript Asset
Umgang mit Formatänderungen
Wenn wir uns die Herausforderungen ansehen, über die wir zu Beginn gesprochen haben, sollte jetzt klarer sein, wie einfach es ist, sich an Formatänderungen anzupassen.
- Sie brauchen ein weiteres Feld? Fügen Sie es einfach in die Grammatik ein.
- Sie brauchen eine andere Datensatzstruktur? Wiederum fügen Sie es einfach der Grammatik hinzu.
- Müssen Sie eine alte und eine neue Version eines Detaildatensatzes gleichzeitig unterbringen? Kein Problem: Sie können ein "Choice"-Element einfügen, um entweder eine "Detail-Old"- oder eine " Detail-New"-Version eines Datensatzes zu ermöglichen, solange sie durch unterschiedliche reguläre Ausdrücke identifiziert werden können.
- Sie müssen Inhalte auf der Grundlage anderer Inhalte berechnen. Fügen Sie einfach Formeln hinzu.
Das ist alles schon erledigt.
Und was dann?
Datenformat-Konfigurationen sind ein wichtiger Bestandteil bei der Definition der Datenverarbeitung in layline.io. Sie sind in der Regel Teil eines
- layline.io-Projekts, das besteht aus
- einer Reihe von Workflows, die alle mit unterschiedlichen Formaten arbeiten können
- vielen verschiedenen Formaten oder sogar demselben arbeiten.
All diese Workflows können dann über das layline.io Configuration Center in den hoch belastbaren und skalierbaren layline.io Reactive Cluster deployt werden. Und genau dort findet die Magie statt.
Mehr ...
Es gibt hier noch viel mehr zu erzählen. Zum Beispiel, was ist layline.io überhaupt? In den untenstehenden Links können Sie mehr über layline.io erfahren und auch tiefer in die Dokumentation eintauchen, wie diese spezielle Grammatik in layline.io funktioniert.
Sie können sich auch eine kostenlose Kopie von layline.io von unserer Website herunterladen und mit einem Beispielprojekt arbeiten, das Sie ebenfalls herunterladen können.
Weitere Informationen finden Sie in der Dokumentation oder kontaktieren Sie uns einfach unter hello@layline.io.
Vielen Dank für die Lektüre!
Ressourcen
| # | Ressource |
|---|---|
| 1 | Dokumentation: Erste Schritte |
| 2 | Dokumentation: Generic Format Asset? |
| 3 | Beispielprojekt: Ausgabe in Kafka |
- Erfahren Sie hier mehr über layline.io.
- Kontaktieren Sie uns hello@layline.io.