layline.io Blog
Beispielreihe: Http-Client-Anfragen.
ReST-Schnittstellen sind beliebt und zahlreich vorhanden. Wir zeigen Ihnen, wie Sie Http-Client-Requests in layline.io am Beispiel von Yahoo Finance konfigurieren können.
Reading time: 8 min.
Was wir zeigen werden
In diesem Artikel zeigen wir, wie man einen layline.io Workflow schnell konfigurieren kann, um eine REST-API abzufragen. Als Beispiel dient die Yahoo Finance API. Wir werden einen Workflow erstellen, der in regelmäßigen Abständen Yahoo nach Aktienkursen abfragt.

Einrichten des Http-Dienstes
Zuerst starten wir die Web-UI und erstellen ein neues Projekt "sample-http-client-yahoo". Dann erstellen wir ein Http-Service Asset "Yahoo-Finance-Source".
Was sind Dienste?
Services in layline.io stellen spezifische Assets dar, die komplexe Schnittstellendefinitionen kapseln und diese dann anderen Assets als einfache benannte Funktionsaufrufe zur Verfügung stellen, um sie einfach aufrufen zu können. REST-API-Definitionen passen in dieses Muster, ebenso wie z.B. Datenbank-Statements. Zu diesem Zweck stellt layline.io eine Reihe von Service Assets zur Verfügung, die auf die jeweiligen Schnittstellentypen ausgerichtet sind, wie z.B. Http, JDBC, Aerospike, und mehr. In unserem Beispiel verwenden wir das Http-Service Asset, um auf die Yahoo Finance API zuzugreifen.
Die Yahoo Börsenkurse REST-API
Yahoo Finance bietet eine sehr umfassende API für den Zugriff auf Finanzinformationen börsennotierter Unternehmen. Für diese Demo verwenden wir die Rapid-API (https://rapidapi.com/), die als Proxy-Dienst fungiert. Wenn Sie Rapid-API nicht kennen, sollten Sie es ausprobieren. Es ist wirklich cool.
Sie können die genaue URL des Dienstes und seine Beschreibung hier nachschlagen und dann nach dem Pfad "market/v2/get-quotes".
Konfigurieren des Http-Dienstes
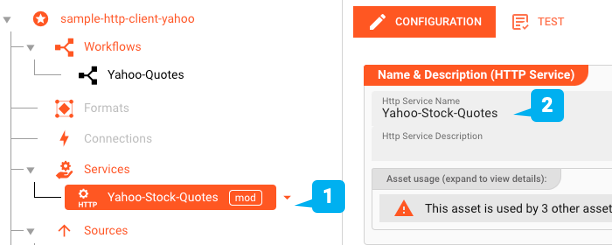
Mit Hilfe des Configuration Centers erstellen wir ein Http-Service Asset (1 + 2):
Host
Als nächstes legen wir die allgemeine Host-Adresse fest, unter der auf die Daten zugegriffen werden kann (1). Hierfür sind keine Anmeldeinformationen erforderlich, sondern API-Schlüssel, die wir später definieren werden.
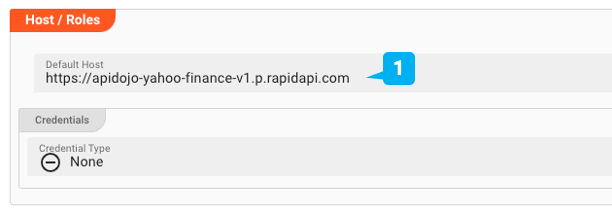
Abfragen
Bevor wir Funktionen definieren, stellen wir sicher, dass layline.io die Anfragen und die entsprechenden Antworten versteht. Sie können eine beliebige Anzahl von Anfragen definieren. Hier wird nur die Anfrage "GetQuotes" (2) definiert, die die Aktienkurse und die dazugehörigen Daten für eine bestimmte Anzahl von Tickersymbolen abrufen soll. Hier wird auch der Pfad zur Anfrage definiert (3). Außerdem konfigurieren wir die für den Aufruf der API erforderlichen Parameter (Region und Symbole sowie RapidAPI-Schlüssel und Host) (4). Die Werte werden bei der Definition des Quell-Assets in einem nächsten Schritt angegeben.
Wenn wir andere Anfragen verwenden wollten, könnten wir sie einfach hier hinzufügen.
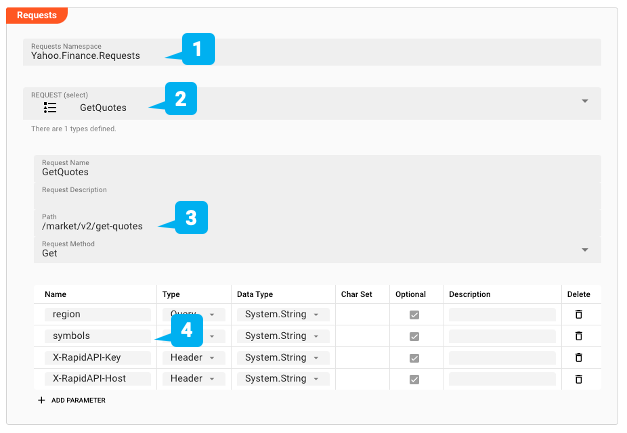
Antwort
Als nächstes definieren wir mögliche Antworten auf unsere Anfrage. Wir erwarten ein JSON-Dokument, das wir in "Quotes" (1) definiert haben. layline.io ist stark typisiert. In unserem Fall bilden wir die Antwort einfach auf den internen Typ "AnyMap" ab. Weitere Antworten könnten 3xx bis 5xx-Fehler sein, die uns ebenfalls interessieren.
Funktionen
Nachdem wir nun die Anfragen und Antworten definiert haben, können wir die abstrakten Funktionen erstellen, die wir intern zur Verfügung stellen wollen.
Wir erstellen eine Funktion mit dem Namen "GetQuotes" (1a + b). Sie verweist auf die gleichnamige Anfrage, die wir oben erstellt haben (2), und weist dieser Anfrage ("Quotes") mögliche Antworten zu (3).
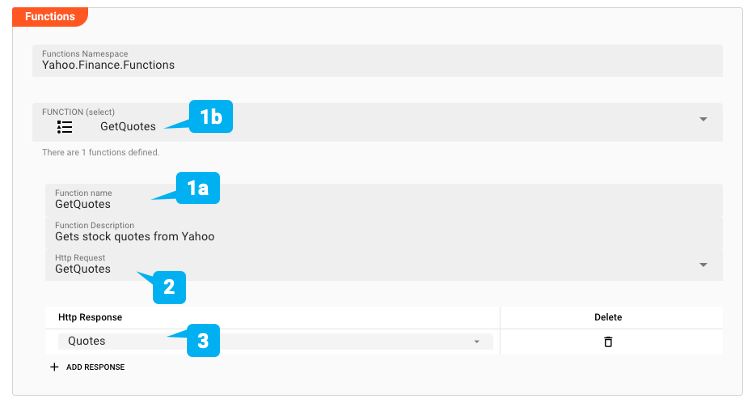
Wir können nun auf die Yahoo Finance API zugreifen, indem wir einfach die Funktion "GetQuotes" aufrufen und ihr die erforderlichen Parameter übergeben. Wir werden ein Beispiel dafür sehen, wenn wir unten die Service Source definieren.
Leider muss man für einen ersten Http-Dienst ziemlich viel konfigurieren. Aber beachten Sie, dass zusätzliche Anfragen an denselben Host sehr schnell hinzugefügt werden können.
Konfiguration der Service-Quelle
Wir planen, die API ständig nach den neuesten Börsendaten abzufragen und wollen sie als reguläre Datenquelle im Workflow behandeln. Hierfür müssen wir ein Service-Source-Asset definieren (1). Ein Service-Quellen-Asset ist ein spezieller Typ von Quelle, der Funktionen verwendet, die in Service-Assets definiert sind, genau wie das oben definierte Asset.
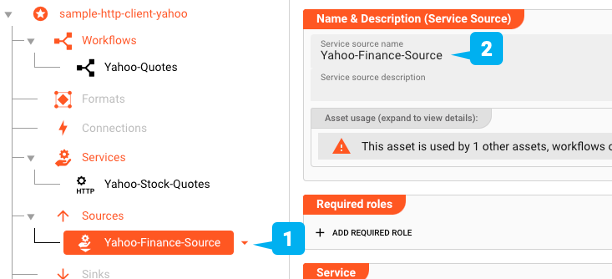
Wir verknüpfen den von uns definierten Http-Dienst mit dieser Quelle:

Schließlich legen wir die Häufigkeit der API-Abfrage und die eigentlichen API-Aufrufparameter fest.
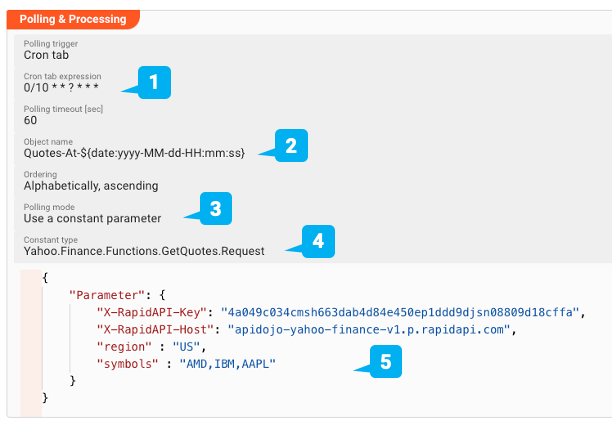
Über eine Cron-Table-ähnliche Einstellung legen wir ein Abfrageintervall von 10 Sekunden fest (1).
Objektname" gibt den Namen des Objekts an, das bei jeder Abfrage zurückgegeben wird (2).
Wir fügen dem Objektnamen das Datum und die Uhrzeit hinzu, um jedes Antwortobjekt zu unterscheiden.
Wir verwenden einen konstanten Parameter für die Abfrage, was nichts anderes bedeutet, als dass wir fest kodierte Parameter an die Servicefunktion übergeben wollen und keine dynamischen Parameter.
In unserem Beispiel (3) rufen wir die Funktion also immer für die gleichen Börsensymbole auf.
Der Constant Type beschreibt den Pfad zu der eigentlichen Service Function, die wir aufrufen wollen, und deren Request-Objekt (4).
Im Moment muss dies noch manuell eingegeben werden, wird aber in Kürze benutzergeführt sein.
Wir geben hier Yahoo.Finance.Functions.GetQuotes.Request ein.
Schließlich geben wir die Parameter, die wir an die Funktion "GetQuotes" übergeben wollen, im JSON-Format an (5). Denken Sie daran, dass wir sie bei der Erstellung des Http-Service-Assets definiert haben.
Das war's, jetzt können wir den eigentlichen Workflow erstellen.
Erstellen des Workflows
Wir gehen zur Workflow-Benutzeroberfläche und richten einen einfachen Workflow mit einem Stream-Input und einem JavaScript-Prozessor ein.
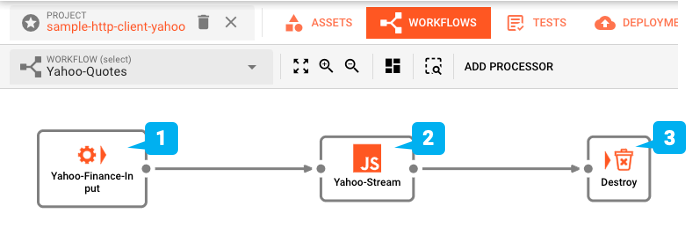
In den Einstellungen für das Service-Input-Asset verknüpfen wir es mit der soeben erstellten Http-Quelle (1).
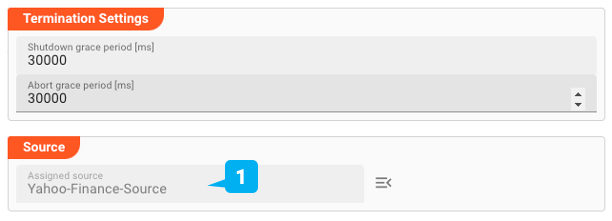
Für den Javascript-Prozessor (1a) fügen wir ein sehr einfaches Skript hinzu, das die empfangene Nachricht in das Stream-Log (1b) ausgibt. Auf diese Weise können wir die Ergebnisse über den Audit Traill in der Benutzeroberfläche überprüfen. Natürlich würden Sie die Ergebnisse normalerweise nicht in das Protokoll ausgeben, sondern sie im nachgelagerten Workflow verarbeiten.

Auf Cluster übertragen und ausführen
Wir sind bereit, den Workflow zu testen. Dazu müssen wir ihn in einem Reactive Engine Cluster bereitstellen. Sie können einfach den Cluster auf Ihrem Laptop verwenden (Single Node). Oder wenn Sie anderswo einen größeren layline.io Cluster haben, können Sie ihn dort deployen. Zum Deployment wechseln wir auf den Reiter DEPLOYMENT des Projekts (1):
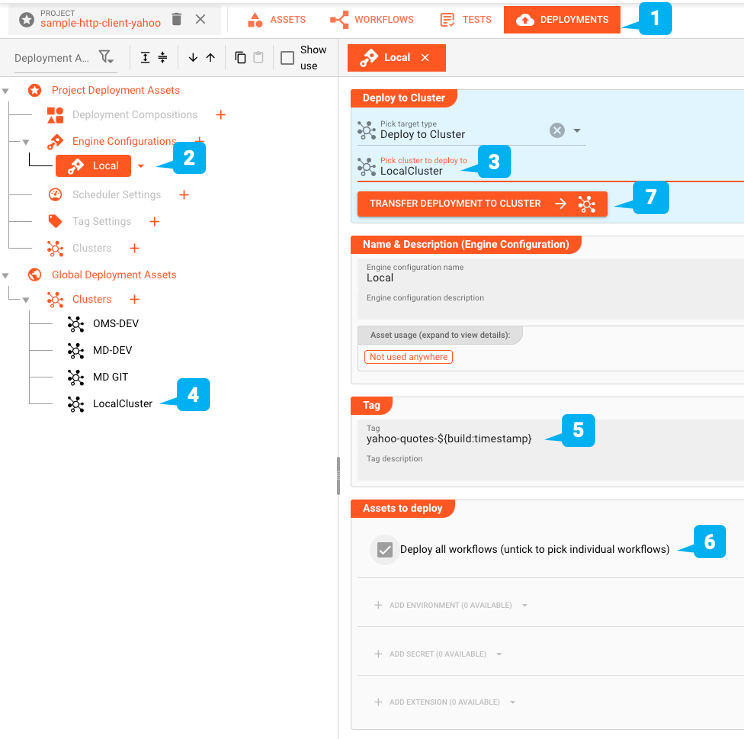
Wir erstellen eine Engine Configuration (2), um das Projekt bereitzustellen. Diese definiert die Teile des Projekts, die wir bereitstellen möchten. In unserem Beispiel wäre das der eine Workflow, den wir definiert haben, sowie das dazugehörige Environment Asset.
Da wir das Projekt auf dem lokalen Cluster bereitstellen wollen, wählen wir "Deploy to Cluster" und dann unser vordefiniertes "Local Cluster"-Setup (3 und 4). Jede Bereitstellung benötigt einen Tag (5). Wir verwenden "yahoo-quotes-", gefolgt von einem Makro "${build-timestamp}", um das Deployment zu identifizieren. Das Makro wird bei der Übertragung der Bereitstellung durch einen Zeitstempel ersetzt. Dadurch wird sichergestellt, dass wir mit jeder Bereitstellung ein anderes Tag erhalten.
Wir wählen die Bereitstellung aller Workflows, die wir erstellt haben (nur einen) (6). Schließlich starten wir die Übertragung der Bereitstellung, indem wir auf "TRANSFER DEPLOYMENT TO CLUSTER" (7) klicken (stellen Sie sicher, dass der Cluster, in dem Sie die Bereitstellung vornehmen, in Betrieb ist).
Wenn die Bereitstellung erfolgreich war, sollten Sie dies sehen:
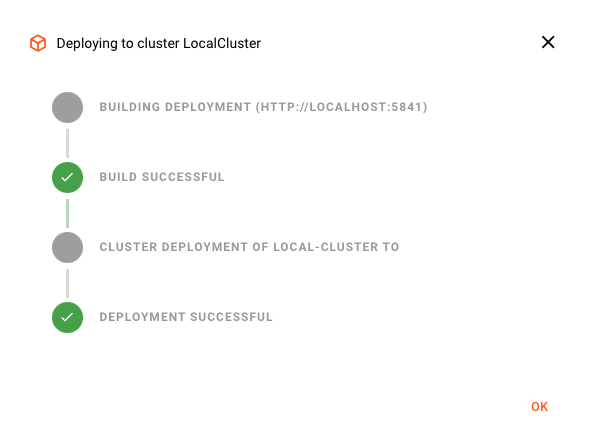
Andernfalls wird eine Fehlermeldung angezeigt, die Sie anleitet, wie Sie das Problem beheben können.
Aktivieren der Bereitstellung
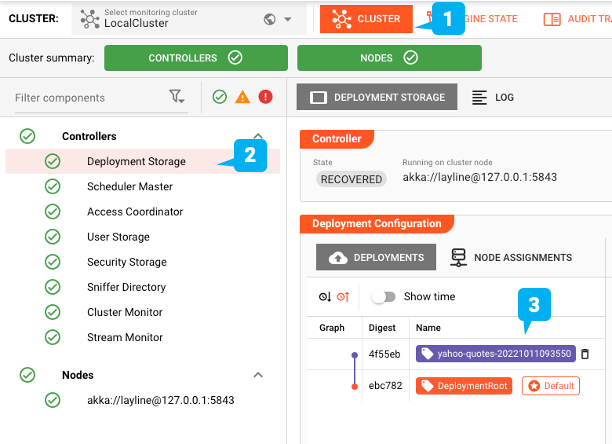
Wir sollten nun bereit sein, die Bereitstellung zu aktivieren. Dazu wechseln wir auf die Registerkarte "CLUSTER" (1). Hier erhalten wir einen Überblick über alle Dinge, die mit "Clustern" zu tun haben. Falls Sie mehr als einen Cluster verwalten, vergewissern Sie sich, dass Sie den richtigen Cluster aus dem Dropdown-Feld oben links ausgewählt haben.
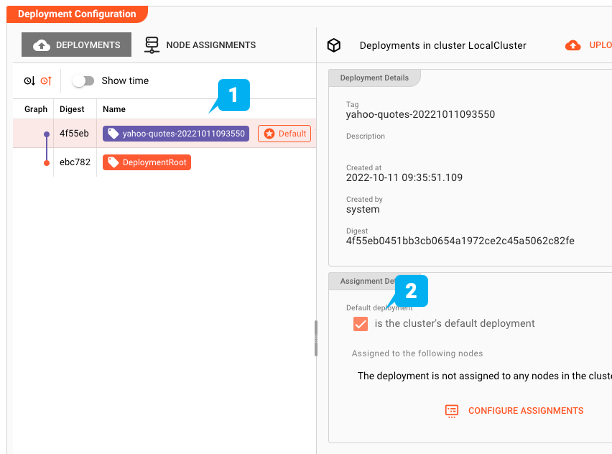
Machen Sie sie zur Standardbereitstellung
Wählen Sie in der Baumstruktur auf der linken Seite "Einsatzspeicher". Hier finden wir alle Einsätze, die dem ausgewählten Cluster derzeit bekannt sind. In unserem Beispiel-Screenshot sehen wir im Abschnitt "Deployment Configuration" 1 "DeploymentRoot": Dies ist die grundlegende leere Standardbereitstellung, die immer vorhanden ist. 2 “yahoo-quotes-20221011093550”: Dies ist die Bereitstellung, die wir gerade in den Cluster übertragen haben. Um nun das neue Deployment auf dem Cluster zu aktivieren, wählen Sie es aus (1) und markieren Sie dann das Kästchen "is the cluster's default deployment" (2).
Zeitplan
Jetzt, da die Bereitstellung auf dem Cluster aktiv ist, müssen wir überprüfen, ob tatsächlich Instanzen des Workflows ausgeführt werden. Wenn Sie diesen Workflow zum ersten Mal bereitstellen, lautet die Antwort wahrscheinlich "nein". Überprüfen wir das:
- Wählen Sie die Registerkarte "Cluster" (1)
- Wählen Sie den Eintrag "Scheduler Master" in der Baumstruktur auf der linken Seite (2)
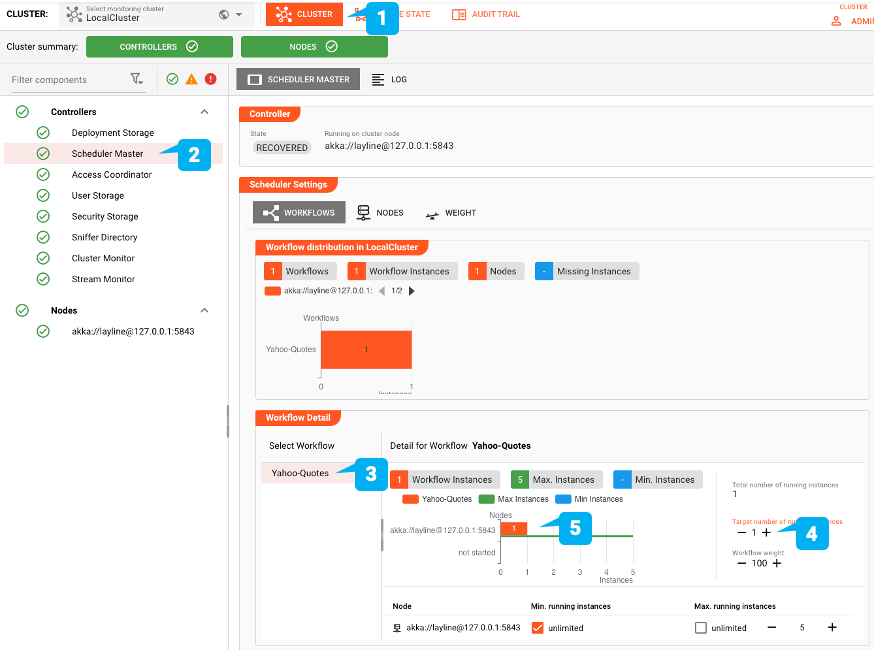
- Wählen Sie in der Box Scheduler Settings den Knoten Scheduler in der Baumstruktur (3)
- Vergewissern Sie sich, dass die Zielanzahl der Instanzen auf mindestens 1 gesetzt ist (4). Wenn Sie eine höhere Zahl einstellen, werden mehr Instanzen desselben Workflows gestartet. Innerhalb weniger Sekunden sollten Sie sehen, dass die Instanz gestartet wurde (5) Sie müssen dies nur einmal tun. Wenn Sie den Workflow das nächste Mal bereitstellen, merkt sich die Reactive Engine die Anzahl der Instanzen, die Sie mit diesem Workflow starten möchten. Sie können die gewünschten Scheduler-Einstellungen auch als Teil eines Deployments definieren. Das ist aber ein Thema für einen anderen Showcase.
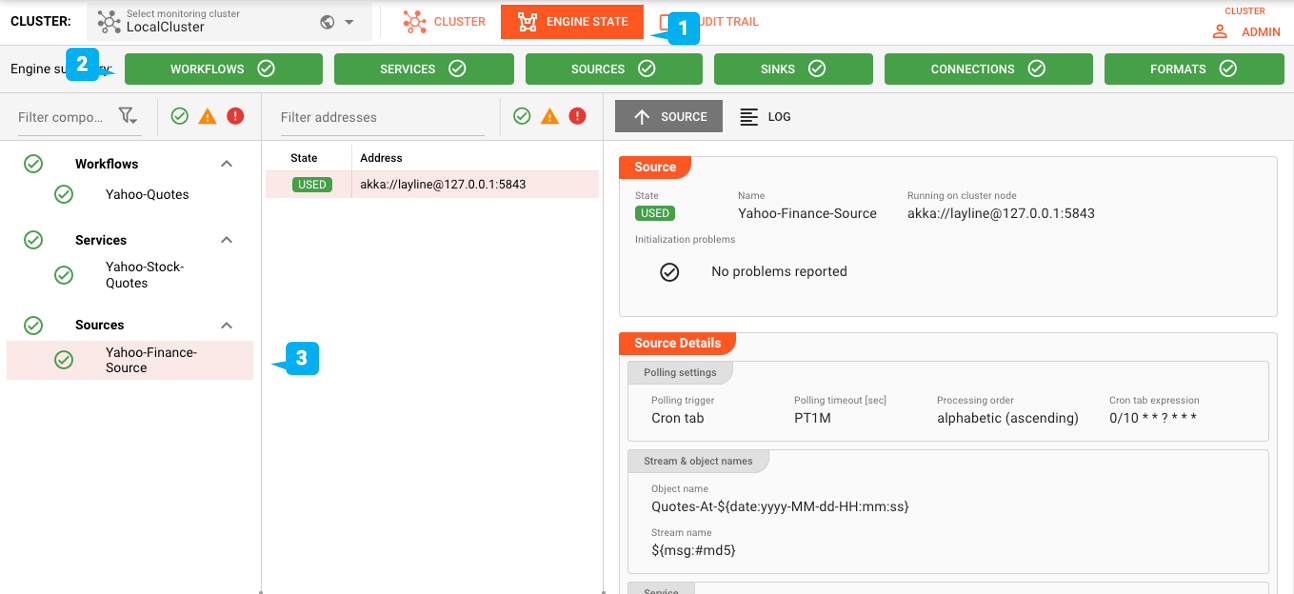
Engine-Status
Wechseln Sie auf die Registerkarte "Engine" (1). Stellen Sie sicher, dass alle Engine-Kategorien grün sind (2). Überprüfen Sie auch den Status der einzelnen Assets in der Baumstruktur auf der linken Seite (3).
Überprüfen der Ergebnisse
Sobald Sie den Workflow (siehe oben) geplant haben, beginnt er, die Yahoo Finance-Schnittstelle alle paar Sekunden nach Ergebnissen abzufragen.
Gehen Sie zur Registerkarte Audit Trail (1), um die Ergebnisse im Stream Log im JSON-Format zu sehen (2 + 3):
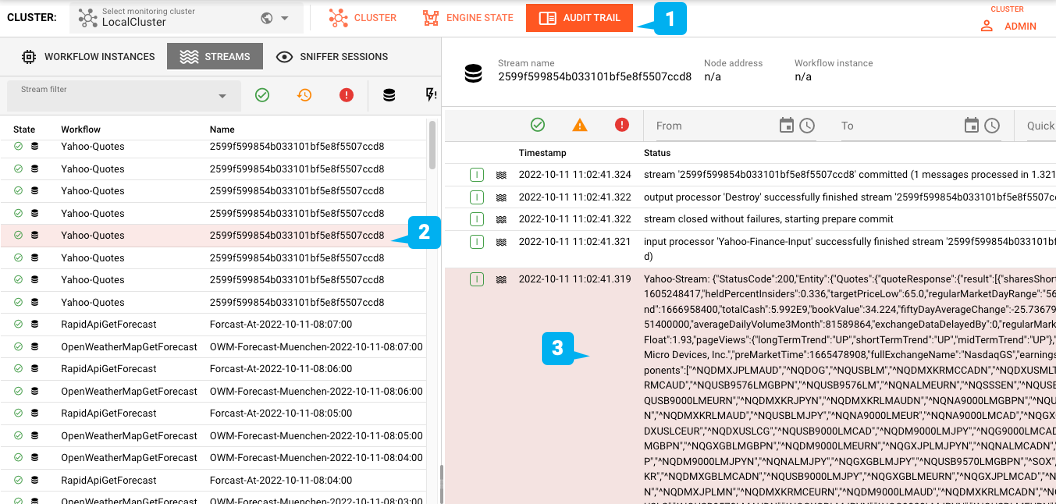
Natürlich ist diese Ausgabe nur für Demozwecke gedacht. In einer realen Arbeitsumgebung würden Sie diese Daten nachgelagert im Workflow verarbeiten.
Zusammenfassung
Dieser Showcase zeigt, wie Sie ohne großen Aufwand einen Http-Client-Workflow on-the-fly erstellen können. Und das ist noch lange nicht alles, was Sie damit erhalten: Reaktiv - Umfasst das Paradigma der reaktiven Verarbeitung. Vollständig auf reaktiver Stream-Verwaltung aufbauend
- Hohe Skalierbarkeit - Skaliert innerhalb einer Engine-Instanz und darüber hinaus über mehrere Engines und verteilte Knoten Ausfallsicherheit - Ausfallsicherheit in verteilten Umgebungen. Vollständiger 24/7-Betrieb und Upgrademöglichkeit Automatische Bereitstellung - Stellen Sie geänderte Konfigurationen mit einem Klick bereit
- Echtzeit und Batch** - Führen Sie sowohl Echtzeit- als auch Batch-Datenintegrationen über dieselbe Plattform aus
- Metriken - Automatische Generierung von Metriken zur Verwendung in Ihrem bevorzugten Überwachungs- und Alarmierungs-Toolkit (z.B. Prometheus) Es gibt zu viele Funktionen, um sie hier zu erklären. Weitere Informationen finden Sie in der Dokumentation oder kontaktieren Sie uns einfach unter hello@layline.io . Vielen Dank für die Lektüre!
Ressourcen
| # | Projektdateien |
|---|---|
| 1 | Github: Beispiel-Http-Client für Yahoo Finance (Eingabe-Testdateien im Verzeichnis _test_files des Projekts) |
| # | Dokumentation |
|---|---|
| 1 | Dokumentation:Erste Schritte |
| 2 | Dokumentation:Generic Format Asset? |
- Erfahren Sie hier mehr über layline.io.
- Kontaktieren Sie uns hello@layline.io.