layline.io Blog
layline.io - Ein Kafka-Vergleich.
Was ist der Unterschied zwischen layline.io und Kafka? Diese Frage hören wir von Zeit zu Zeit. Wir fragen uns warum.
Reading time: 7 min.

Wie ist layline.io im Vergleich zu Kafka?
Das ist eine Frage, die wir von Zeit zu Zeit hören. Wir fragen uns warum. Um das besser zu verstehen, sollten wir uns ansehen, was Kafka ist:
Was ist Kafka?
So beschreibt es AWS:
Apache Kafka ist ein verteilter Datenspeicher, der für die Aufnahme und Verarbeitung von Streaming-Daten in Echtzeit optimiert ist. Bei Streaming-Daten handelt es sich um Daten, die kontinuierlich von Tausenden von Datenquellen erzeugt werden, die die Datensätze in der Regel gleichzeitig senden. Eine Streaming-Plattform muss diesen konstanten Zustrom von Daten verarbeiten und die Daten sequentiell und inkrementell bearbeiten.
Kafka bietet seinen Nutzern drei Hauptfunktionen:
- Veröffentlichen und Abonnieren von Datensatzströmen.
- Ströme von Datensätzen in der Reihenfolge speichern, in der die Datensätze erzeugt wurden. Verarbeiten von Datensatzströmen in Echtzeit.
Kafka wird in erster Linie zum Aufbau von Echtzeit-Pipelines für Datenströme und Anwendungen verwendet, die sich an die Datenströme anpassen. Es kombiniert Messaging, Speicherung und Stream-Verarbeitung, um die Speicherung und Analyse sowohl von historischen als auch von Echtzeitdaten zu erleichtern.
Unsere Sicht auf Kafka
Die obige Beschreibung enthält ein wenig Technobabble, auf das wir eingehen müssen. Es ist die Rede von Streaming-Verarbeitung, Echtzeit usw. Was bedeutet das alles im Zusammenhang mit Kafka?
- **Kafka ist in erster Linie eine Datenspeicherlösung. Es sollte als eine spezielle Art von Datenbank betrachtet werden, in der Daten in Warteschlangen (Topics) gespeichert werden. Es gibt verschiedene Möglichkeiten, wie in diese Warteschlangen geschrieben (publish) und aus ihnen gelesen (subscribe) werden kann. Die Warteschlangen folgen dem FIFO-Prinzip (first-in-first-out). Es gibt das Argument, dass Kafka kein Speicher ist, sondern ein Streaming-Event-Prozessor, aber das ist unserer Meinung nach irreführend. Kafka wurde entwickelt, um Daten zu speichern und dann von Verbrauchern schnell gelesen zu werden. Es ist so konzipiert, dass es gespeicherte Daten nach einer vorkonfigurierten Aufbewahrungsfrist löscht, unabhängig davon, ob die Daten konsumiert wurden oder nicht. In diesem Sinne ist es ein temporärer Datenspeicher mit ein paar sehr speziellen, wenn auch nützlichen Funktionen.
- Einzelne Prozesse können in Warteschlangen veröffentlichen (Produzenten) oder Warteschlangen abonnieren (Konsumenten). Wenn keiner der vorgefertigten Konnektoren (siehe unten) als Producer/Consumer für Ihren Zweck ausreicht (was wahrscheinlich ist), dann müssen Sie selbst einen programmieren (die meisten verwenden Java, aber es gibt auch andere Optionen).
- Kafka kann in einer nativen, verteilten Cloud-Umgebung ausgeführt werden, die Ausfallsicherheit und Skalierbarkeit bietet.
Confluent (das Unternehmen) hat Kafka einige weitere Funktionen hinzugefügt, wie z. B. vorgefertigte "Connectors". Connectors sind spezielle Arten von Producern und Consumern, die spezielle Arten von Datenquellen/Senken von/zu Kafka-Themen lesen/schreiben können. Sie sind in ihren Möglichkeiten ziemlich eingeschränkt und spezialisiert.
Darüber hinaus wurde die Möglichkeit geschaffen, Daten mithilfe von "ksql" zu filtern, zu routen, zu aggregieren und zusammenzuführen. Das bedeutet, dass Sie Informationen aus Kafka-Themen in Echtzeit filtern und weiterleiten können. Klingt großartig. Es handelt sich jedoch nur um eine weitere Art von Verbraucher, der Daten aus einem Kafka-Topic liest, dann filtert, aggregiert, zusammenführt und die Ergebnisse an ein anderes Topic weiterleitet, das ein anderer Verbraucher lesen kann. Der beste Weg, dies logisch zu vergleichen, ist die Analogie zu einer tabellengesteuerten Datenbank (z. B. Oracle), in der Sie Daten mit SQL von einer Tabelle in eine andere kopieren; Bei Kafka ist es jedoch viel komplizierter.
Kafka verfügt über einige, aber keine sinnvollen Fähigkeiten zur Datentransformation. Eines der größten Hindernisse ist, dass Kafka keine inhärente Fähigkeit hat, Daten zu parsen und damit zu bearbeiten. Es unterstützt nur sehr wenige begrenzte Datenformate. Für alles, was aus dem Rahmen fällt, müssen (wahrscheinlich) eigene Producer und Consumers programmiert werden, um die Aufgabe zu erfüllen. Dies ist wiederum wie bei jeder anderen Datenbank, die sich hauptsächlich um Interna und nicht um Externa kümmert. Insgesamt kann man sagen, dass Kafka eigentlich keine Daten verarbeitet. Es speichert lediglich Daten. Jedes andere Szenario impliziert die Verkettung von atomaren Themen mit Producern und Consumern.
Kafka ist auch dafür bekannt, dass es ziemlich schwer zu bedienen ist. Es gibt keine umfassende Benutzeroberfläche. So gut wie alles wird in Konfigurationsdateien konfiguriert und über die Befehlszeile bedient.
Zusammenfassung
Die Hauptanwendung von Kafka ist für
- Schnelle Datenspeicherung
- Für große Mengen
- die sowohl schnell produziert als auch konsumiert werden
**Wir lieben Kafka für diesen Zweck. Es ist großartig, und wir nutzen es häufig in Implementierungen, obwohl es mehrere andere Lösungen gibt, um dies ebenfalls zu erreichen.
Was ist layline.io?
Layline.io ist ein schneller, skalierbarer, belastbarer Ereignisdaten Prozessor. Er kann Daten in Echtzeit einlesen, verarbeiten und ausgeben. Verarbeiten bedeutet, etwas mit den Daten zu "machen", im Gegensatz zu dem, was Kafka tut (speichern). Ein wesentlicher Unterschied zu Kafka ist, dass sich bei layline.io alles um das Konzept der "Workflows" dreht. Workflows spiegeln eine datengesteuerte Logik wider, die häufig einer komplexen Datenorchestrierung ähnelt.
Dies bedeutet
- die Interpretation der Daten,
- Analysieren der Daten,
- Entscheidungen zu treffen und sie möglicherweise durch das Hinzuziehen anderer Quellen in Echtzeit anzureichern
- Statistiken erstellen
- Filtern der Daten,
- sie weiterleiten,
- Integration von ansonsten disparaten Datenquellen und Senken.
und all dies in
- Echtzeit,
- transaktionssicher (Option),
- ohne Speicher-Overhead,
- konfigurierbar,
- UI-gesteuert
- und vieles mehr
Beispiel-Workflow:
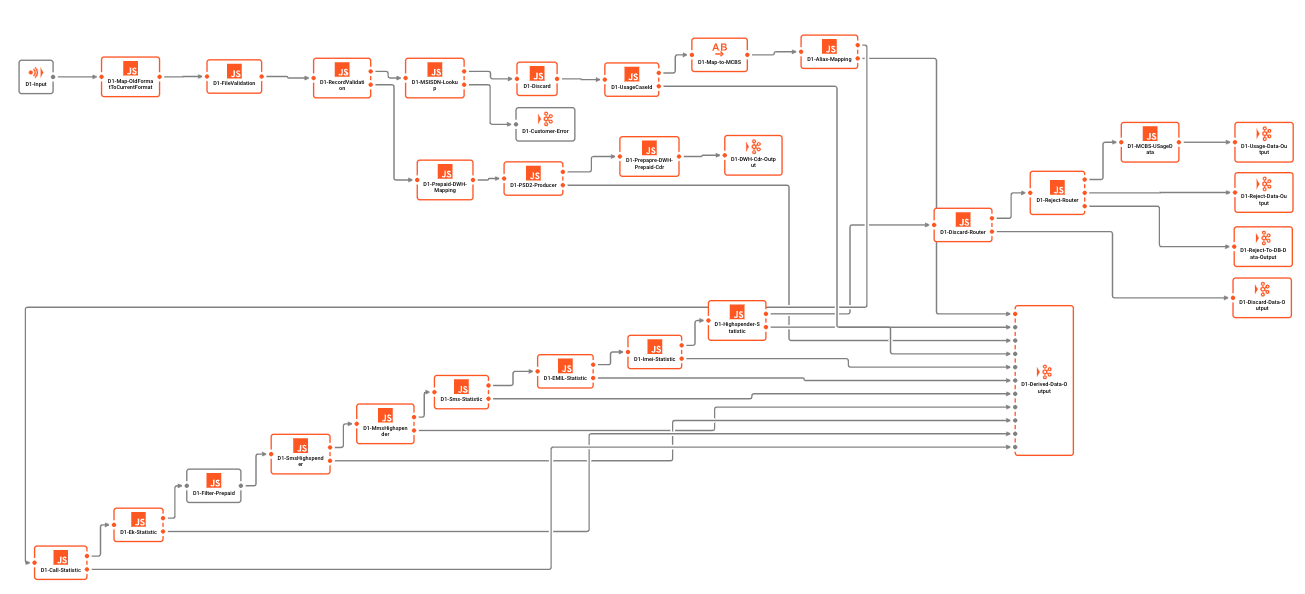
Kafka unterstützt keine Workflows von Haus aus. Alles, was in Kafka als Workflow interpretiert werden kann, ist eher ein Versuch, eine Verkettung von Kafka-Warteschlangen und Consumern/Producern als Workflow zu "verkaufen". Es ist jedoch zu beachten, dass es sich dabei um individuelle Einheiten handelt, die sich gegenseitig nicht kennen. Es gibt weder eine übergreifende (Transaktions-)Steuerung noch eine tatsächliche Unterstützung für Workflows in Kafka.
Kombination von Kafka und layline.io
Aus Sicht von Kafka bedeutet dies, dass layline.io als Producer (Schreiben) oder Consumer (Lesen) gesehen wird. Aus Sicht von layline.io wird Kafka als Event-Datenspeicher gesehen, vergleichbar mit anderen Datenspeichern wie SQL-DBs, NOSQL-DBs oder auch dem Dateisystem. Das ist eine gute Kombination, je nach Anwendungsfall. layline.io fungiert in diesem Kontext als Daten-Orchestrierungselement zwischen einer theoretisch unbegrenzten Anzahl von Kafka-Themen und anderen Quellen und Senken außerhalb der Kafka-Sphäre
Aus diesem Blickwinkel betrachtet sind Kafka und layline.io extrem komplementär, nicht konkurrierend. Die Überschneidungen sind minimal. Wir sehen kein sinnvolles Szenario, in dem sich ein potentieller Kunde für das eine oder das andere entscheiden würde, sondern eher für das eine und das andere.
Wie kommen Kafka-Benutzer heute zurecht?
Der typische Kafka-Benutzer von heute verwendet Kafka als das, was es ist: Eine spezielle Art von Ereignisdatenspeicher. Um Daten in/aus ihm zu schreiben und zu lesen. Meistens codiert er Konsumenten und Produzenten. Diese benutzerdefinierten Teile müssen dann die Punkte 1 bis 6 von oben enthalten (Hinweis: sie werden es nicht). Außerdem gewährleisten sie nicht die Ausfallsicherheit, Skalierbarkeit, Berichterstattung, Überwachung und alles andere, was man von solchen Komponenten erwarten müsste. Sie werden oft mit einfachen Skripting-Tools wie Python bis hin zu ausgefeilten Microservice-Frameworks wie Spring Boot und anderen erstellt.
Stattdessen könnten sie einfach layline.io verwenden und bekämen all das oben genannte.
Reales Einsatzbeispiel
Dieser Kunde nutzt layline.io, um alle Nutzungsdaten (Kommunikations-Metadaten) zu verarbeiten.
Vor der Implementierung von layline.io befand sich das Unternehmen in einer Situation, die dem im vorherigen Abschnitt beschriebenen Szenario sehr ähnlich war. Mehrere Kafka-Warteschlangen wurden von einzelnen Prozessen gefüttert, die individuell programmiert waren. Andere Prozesse lasen aus diesen Warteschlangen und schrieben Daten in anderen Formaten und mit einer gewissen Logik an andere Ziele. Eine chaotische und fehleranfällige Architektur, die kostspielig in der Wartung und fast unmöglich zu verwalten war.
Nach der layline.io-Implementierung, bei der die bisherige Geschäftslogik und die Prozessoren ersetzt wurden, sah die Architektur wie folgt aus:
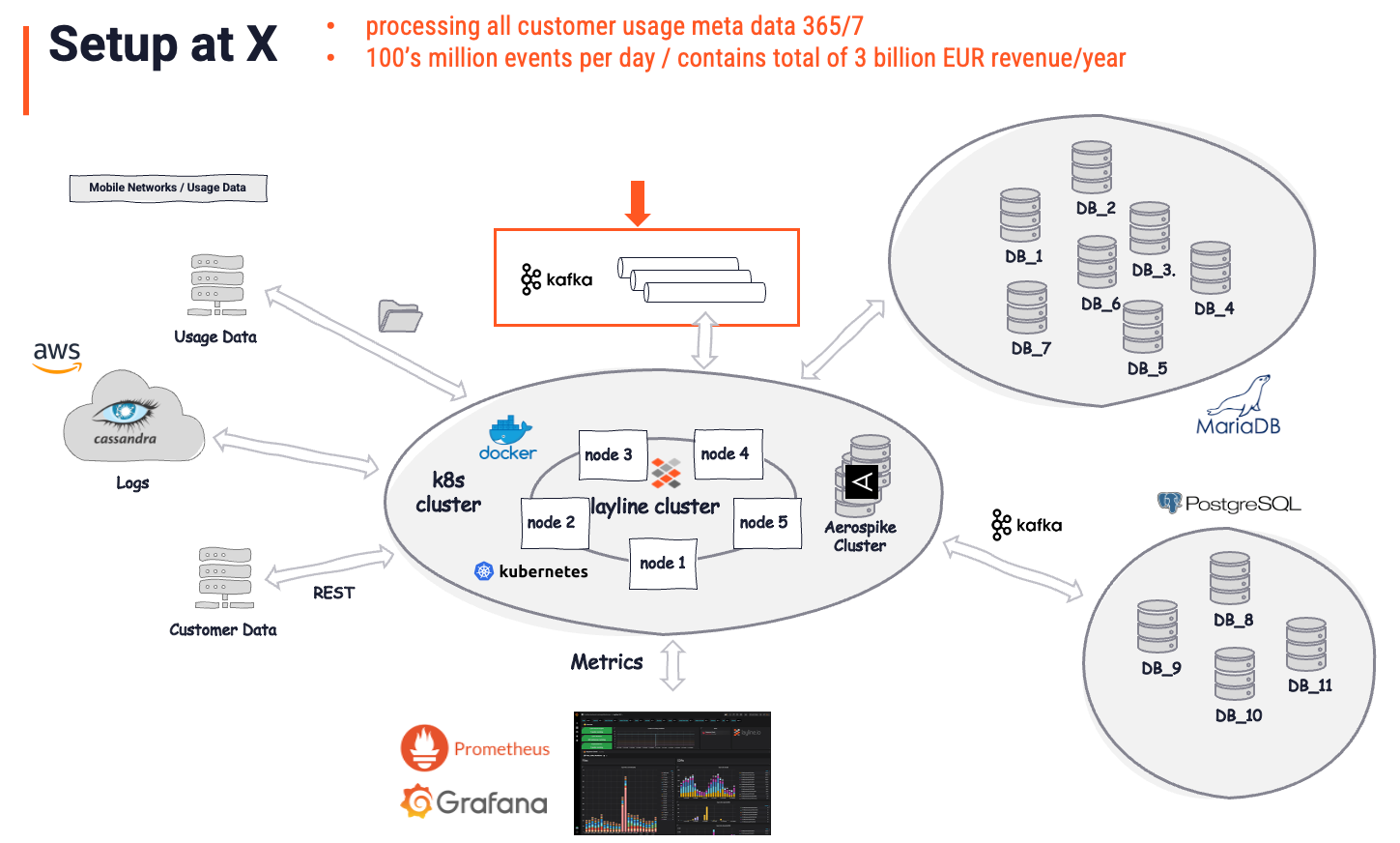
Das Gesamtbild wird als die "Lösung" betrachtet. Es ist wichtig zu verstehen, dass layline.io als die eigentliche Lösung anerkannt wird, während Kafka nur ein weiterer (wichtiger) Speicher ist. Kafka gab es schon vor layline.io. Es spielt aber eine vergleichsweise kleine Rolle (roter Pfeil und Kasten) in der Gesamtlösung. Es dient als intermittierender Datenspeicher, was es per Definition auch ist. Die intelligente Datenanalyse, -anreicherung, -filterung, -transformation, das Routing, die komplexe Geschäftslogik und vieles mehr wird von layline.io übernommen. Eine Aufgabe auf einem Niveau, das mit Kafka unmöglich zu bewältigen wäre. Auf die Frage, welcher Anteil davon auf Kafka zurückzuführen ist, würde der Kunde wahrscheinlich antworten: "5% der Gesamtlösung".
Fazit
Kafka wird weithin als Nachrichtenbus angesehen, aber in Wirklichkeit geht es um Daten im Ruhezustand, die es anderen Anwendungen ermöglichen, Daten in Bewegung zu setzen. In diesem Zusammenhang ist die eigentliche Anwendung aus Sicht eines Nutzers etwas, das über eine Client-API mit Daten aus Kafka gefüttert wird. layline.io hingegen ist ein integraler Bestandteil der Logik Ihrer Anwendung, wenn es nicht die Anwendung selbst ist (siehe Beispiel). Sie können sich layline.io wie das Herz-Kreislauf-System plus Logik vorstellen, während Kafka nur ein externes, gut organisiertes Reservoir ist. Die Überschneidung zwischen Kafka und layline.io ist daher minimal.
Ein Kunde, der Kafka einsetzt, wird nicht in Frage stellen, ob layline.io "zusätzlich zu Kafka" sinnvoll sein könnte. Genauso wenig würden wir den Einsatz von Kafka als Datenspeicher in Frage stellen, sondern nur, ob dies der richtige Datenspeicher für den Zweck wäre. Die Kunden würden sich eher fragen, wie sie mit layline.io Probleme lösen (die Kafka nicht adressiert). Vielleicht machen sie etwas Neues, oder sie ersetzen bestehende Prozesse (z.B. Microservices), die in der Vergangenheit zum Teil kundenspezifisch programmiert wurden.
Appendix: Kurzvergleich layline.io <> Kafka
Kein vollständiger Vergleich, aber es hilft:
| Was | Kafka | layline.io |
|---|---|---|
| Typ | Nachrichtenwarteschlange | Gleichzeitigkeitsplattform |
| Workflow-Unterstützung | Nicht wirklich. Nur ein Speicher. | Inhärenter Teil der Lösung |
| Datenspeicher | Ja | Nein |
| Unterstützung von Datenformaten | Kein Verständnis von Datenformaten out-of-the-box. | Vollständiges Verständnis des Dateninhalts. Starke Typisierung. |
| Nur im Zusammenhang mit ksql begrenzte Unterstützung für Formate wie CSV, JSON, Avro, ProtoBuf. Prüfen Sie hier | Kafka kann hier nicht mithalten, da es nicht darauf ausgelegt ist, Daten zu verstehen, sondern sie nur zu speichern und zu transportieren. | Unterstützung für extrem komplexe Datenformate wie ASCII und binär, hierarchische Strukturen, ASN.1 usw. |
| Datentypunterstützung | Extrem eingeschränkt und nur im Zusammenhang mit ksql. Otherwise, data agnostic. | Full support for important data types. |
| Data enrichment | Nicht unterstützt. Es können keine externen Quellen zur Datenanreicherung herangezogen werden. | Volle Unterstützung. |
| Real-time | Kafka ist ein Speicher. Dieser kann nur so echtzeitfähig sein wie das System, das die Daten aus dem Speicher (Puffer) liest. | Vollständig. Mehr Echtzeit geht nicht. Keine Zwischenspeicherung. Die Daten werden sofort verarbeitet und ausgegeben. |
| Custom metrics | Keine benutzerdefinierten Metriken speziell für Ihren Anwendungsfall | Jede Art von benutzerdefinierter Metrik (z. B. "4711 Kunden haben sich im letzten Zeitintervall für den Dienst y angemeldet") |
| Performance | Hoch | High |
| Scalable | Ja | Ja |
| Resilient / HA | Ja | Ja |
| Persistent | Ja, das ist der Zweck von Kafka. | Nein. Das ist nicht der Zweck von layline.io, aber es funktioniert hervorragend mit Persistenzschichten wie Kafka. |
| Speicherintensität | Hoch | Niedrig |
| Hardware-Footprint | Hoch | Niedrig |
| Open Source | Ja, für Community-Edition. Nein für konfluente Lösungen (z.B. ksql) | Noch nicht. |
| Bereites Cloud-Angebot | Ja, für confluent | Noch nicht. |
- Erfahren Sie hier mehr über layline.io.
- Kontaktieren Sie uns hello@layline.io.