layline.io Blog
Damn that Data Format Hell
Dealing with complex data formats and changes can be daunting. Learn how layline.io tackles this challenge using a configurable grammar language.
Reading time: 10 min.
Setting
You're the gal/guy who is tasked with taking care of and running the data processing infrastructure at ACME Corp. That's the complex and sensitive machinery that does all the heavy data lifting in your company, yet never reaps any rewards for it. It's the pump which may not stop pumping, it's the juice which keeps things going.
Yet when your parents, friends, even colleagues ask you what it is that you do at ACME, they're just dozing off in the middle of your enthusiastic explanation.
Let’s face it: You don’t get enough credit for what it is that you do for the world 🙃
Challenges
The job you are doing doesn't require you to run around in a mechanic's outfit, but it sure feels like you have to constantly observe, mend, correct, and simply inject new mojo into that data crunching infrastructure.
While there are many day-to-day challenges, one of them is about CHANGE. Yes, never change a running system, they say, but that’s not how the world turns. One of the more frequent changes is …
Data Format Change
AAHHHH! Red alert … sirens sounding …! When it comes to data format change you often see a number of challenges coming together at the same time:
- Data interfaces are often hard coded in some source code. You can’t just “change” them (as the boss suggests), or at least it’s not that simple.
- During migration, data is received in both old and new format. Even with a small change, that’s still two different formats which need to be processed in parallel.
- It’s not just about another field. Sometimes it’s a whole added data structure and a bunch of other things all at the same time.
- Changed data may require internal handling of additional information etc. Again, stuff may be hard coded and therefore code needs to change to accommodate.
- You ran out of coffee. That’s no help.
We have two major problems here which are
- Change of code and
- handling of format migration.
This can turn out to be quite headache and require long cycles of planning, development, release, testing and finally deployment.
If there only was a better way to get this done quickly and in an easy way ...
Generic Data Formats to the Rescue
Of course this is a blog about layline.io and how great it is, in case you didn’t know (see full disclosure below). So let’s take a look at how layline.io approaches this challenge:
layline.io features Generic Data Formats which can’t solve all of the above challenges, but most of them, most of the time.
What are Generic Data Formats?
As the name implies, this concept allows to define data formats in a generic fashion. To do so, it provides
- a language to define the structure (grammar) of the format you are trying to wrestle.
- This language is making use of regular expressions to define and identify individual elements of a structure, and then
- sub-elements of that structure, etc..
- It is object-oriented in that you can define and reuse element-structures throughout.
What does that language look like?
Let’s have a look. For this purpose we will work with a super simple data format, which has comma separated, must have one Header record, 1..n detail records and a trailer records. A format we have all come across in one way or another.
Example data of a simple Bank Transaction log:
H;Sample Bank Transactions
D;20-Aug-2021;NEFT;23237.00;00.00;37243.31
D;21-Aug-2021;NEFT;00.00;3724.33;33518.98
T;100
And here is how this format defined within layline.io using the generic grammar language:
format {
name = "Bank Transactions"
description = "Random bank transactions"
start-element = "File"
target-namespace = "BankIn"
elements = [
// #####################################################################
// ### File sequence
// #####################################################################
{
name = "File"
type = "Sequence"
references = [
{
name = "Header"
referenced-element = "Header"
},
{
name = "Details"
max-occurs = "unlimited"
referenced-element = "Detail"
},
{
name = "Trailer"
referenced-element = "Trailer"
}
]
},
// #####################################################################
// ### Header record
// #####################################################################
{
name = "Header"
type = "Separated"
regular-expression = "H"
separator-regular-expression = ";"
separator = ";"
terminator-regular-expression = "\n"
terminator = "\n"
mapping = {
message = "Header"
element = "BT_IN"
}
parts = [
{
name = "RECORD_TYPE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
},
{
name = "FILENAME"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
}
]
},
// #####################################################################
// ### Detail record
// #####################################################################
{
name = "Detail"
type = "Separated"
regular-expression = "D"
separator-regular-expression = ";"
separator = ";"
terminator-regular-expression = "\n"
terminator = "\n"
mapping = {
message = "Detail"
element = "BT_IN"
}
parts = [
{
name = "RECORD_TYPE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
},
{
name = "DATE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value = {
type = "Text.DateTime"
format = "dd-MMM-uuuu"
}
},
{
name = "DESCRIPTION"
type = "RegExpr"
regular-expression = "[^;\n]*"
value = {
type = "Text.String"
}
},
{
name = "DEPOSITS"
type = "RegExpr"
regular-expression = "[^;\n]*"
value = {
type = "Text.Decimal"
}
},
{
name = "WITHDRAWALS"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.Decimal"
},
{
name = "BALANCE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value = {
type = "Text.Decimal"
}
}
]
},
// #####################################################################
// # Trailer record
// #####################################################################
{
name = "Trailer"
type = "Separated"
regular-expression = "T"
separator-regular-expression = ";"
separator = ";"
terminator-regular-expression = "\r?\n"
terminator = "\n"
mapping = {
message = "Trailer"
element = "BT_IN"
}
parts = [
{
name = "RECORD_TYPE"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
},
{
name = "RECORD_COUNT"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.Integer"
}
]
}
]
}
It’s fairly self-explanatory, and looks a lot like a JSON formatted file. But on second-look it’s not JSON. Let’s look at some details.
The format element
Everything starts with the top-level format element:
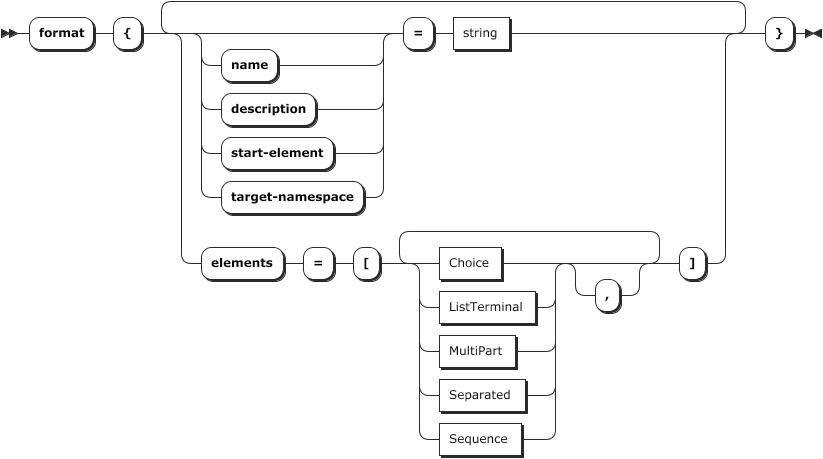
Besides a name and description, it also has an array of elements. These elements define a number of sub-elements (classes), which can be of different types, which then make up the whole format. In our example this is just one element by the name of “File” and type Sequence.
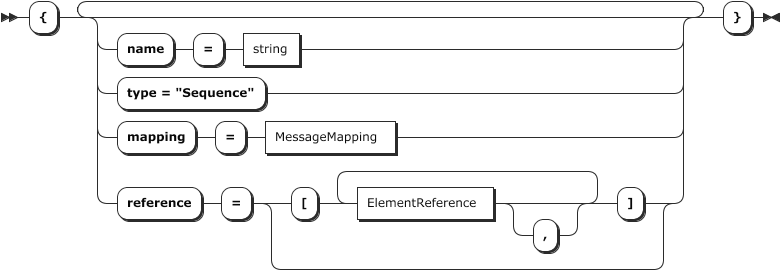
The File element of type Sequence
This element defines a logical structure of sub-elements in its references structure by the names of “Header”, “Detail”, and “Trailer”.
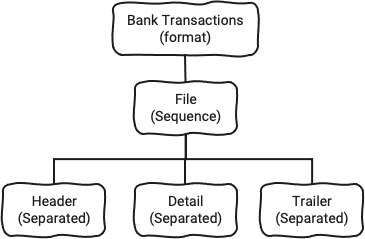
You may be able to tell that we are building a tree here:
The Header element of type Separated
So far we have only had logical elements which define structure. The element Header of type Separated now for the first time defines a how data can actually be identified in the file.
...
// #####################################################################
// ### Header record
// #####################################################################
{
name = "Header"
type = "Separated"
regular-expression = "H"
separator-regular-expression = ";"
separator = ";"
terminator-regular-expression = "\n"
terminator = "\n"
mapping = {
message = "Header"
element = "BT_IN"
}
...
An element of type Separated has a property regular-expression which is used to provide a regular expression (tataa!) to identify the element in the data stream. In our case this is simply “H” to identify a Header record. See the sample file above. It also has a terminator-regular-expression which is set to “\n” to mark the end of the element. In our case the resulting element is then a whole line from “H” to the line-feed at the end of the first line.
H;Sample Bank Transactions
...
You get the idea.
The mapping part tells layline.io how this element can be referenced throughout a layline.io Workflow, once the data is parsed. We will get to that a little later.
Also, in the Header declaration we find:
...
parts = [
{
name = "RECORD_TYPE" // name of the element
type = "RegExpr" // pick a type
regular-expression = "[^;\n]*" // this is how we identify the first field (element)
value.type = "Text.String" // this is the field type
},
{
name = "FILENAME"
type = "RegExpr"
regular-expression = "[^;\n]*"
value.type = "Text.String"
}
]
...
Now this is where individual parts (again elements) of the Header are defined. In the case of the Header it’s two elements RECORD_TYPE and FILENAME. They both are of type RegExpr, meaning that they again can be identified by way of a regular expression within the Header record. There are two more types Calculated and Fixed to choose from.
The Detail and Trailer elements of type Separated
Like we did with the Header, we simply continue to define the structure with the Detail and Trailer elements which we have referenced within the File-Sequence above.
We end up with a completed structure like this:
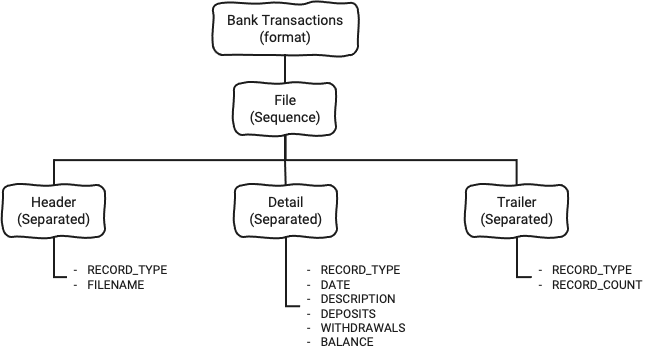
Preliminary conclusion
We have learned that the way the grammar language works, is as follows:
- A grammar consists of a number of elements,
- These elements come in different types which serve distinct purposes,
- The initial element is
formatwhich points to a starting element which you also define, - You can define any number of additional elements,
- Some elements can then reference other elements. Elements can be viewed as reusable classes.
That provides A LOT of possibilities in how a grammar can map to real-world data formats
How about other, more complex formats?
We of course know, that in YOUR world data formats are not as simple as the one we picked in our example. Here is what else works:
- Very complex ASCII/Unicode formats, e.g. all sorts of different record types, hierarchical structures.
- Conditional data parsing through managing conditional parser state, e.g. “record type B may only come directly after A”.
- Binary structures.
- A mix of ASCII and binary formats.
We believe this covers more than 80% of all data interchange formats. There are - of course - always others like for example ASN.1-based formats et al. layline.io features other, better parsers for these types, too.
Multiple Format Support
You can define as many formats as you like. layline.io compiles all of them into a "super-format" at runtime. This allows you to
- reference all formats from anywhere,
- map data from one format to another,
- create new message instances based on a specific format,
- create or destroy individual element structures within a message, and
- ingest or output data in any of the defined formats.
Where do I actually configure all of this?
To not add to your misery, we have provided a nice user interface to help you get all the configuration done and cheer you up. You can find it in the layline.io web-based Configuration Center under Project --> Formats --> Generic Format:
It is here that you enter all the grammar:
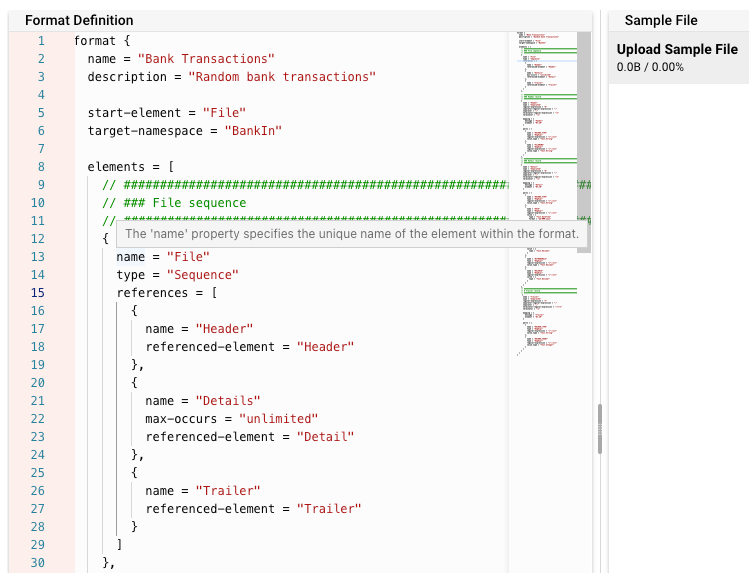
And it does not stop there. While you are defining your grammar, you can upload a sample data file, and see side-by-side whether your grammar matches the data file structure:
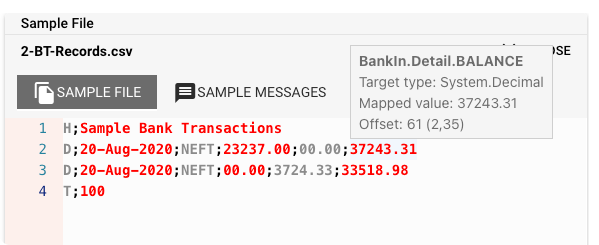
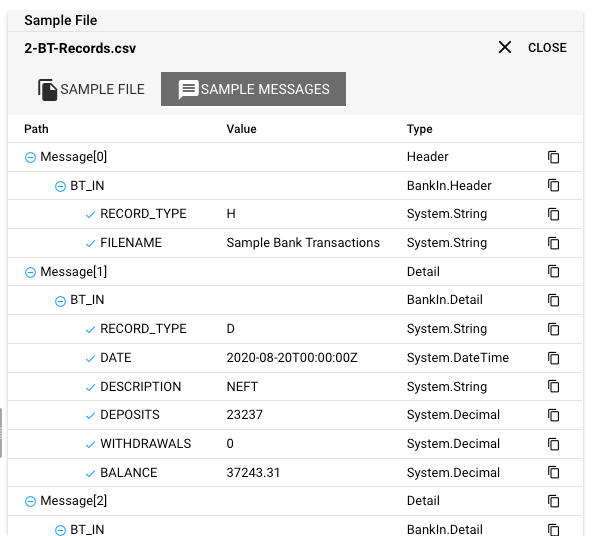
Pretty cool, eh?
Referencing Data within Logic
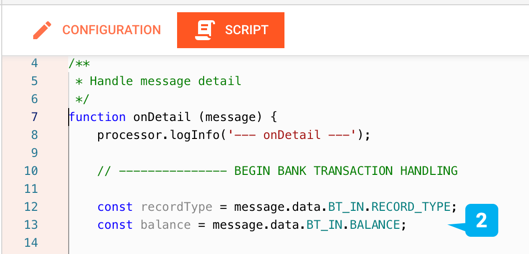
There is no point in defining grammars, if you don't plan to reference and potentially manipulate data within your processing chain. Once you have defined one or more grammars within layline.io, you can then acess individual elements and structures within it like so:
Example: Data Access within Mapping Asset
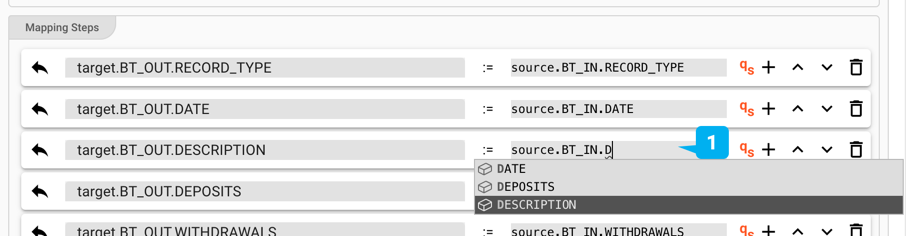
Example: Data Access within Javascript Asset
Dealing with Format Changes
Looking back at the challenges which we talked about at the beginning, it should now be clearer how easy it is to adapt to format changes.
- Need another field? Just add it to the grammar.
- Need another whole record structure? Again, just add it to the grammar.
- Need to accommodate an old and a new version of a Detail record both at the same time? Easy: You can insert a
Choiceelement to allow for either aDetail-OldorDetail-Newversion of a record, as long as they can be identified by different regular expressions. - Need to calculate content based on other content. Just add formulas.
It’s all taken care of.
And then what?
Data format configurations are an important part in defining data processing within layline.io. They are usually part of a
- layline.io Project which consists of
- a number of Workflows which all may work with
- many different formats, or even the same.
All of this is then deployable to the highly resilient and scalable layline.io Reactive Cluster via the layline.io Configuration Center. And that’s where the magic executes.
More …
There is a lot more to tell here. For example what the hell is layline.io anyway? In the links below you can learn about layline.io and also dive deeper into the documentation of how this specific grammar works in layline.io.
You can also grab your free copy of layline.io from our website and work with a sample Project which you can also download.
For more information please check the documentation or simply contact us at hello@layline.io.
Thanks for reading!
Resources
| # | Resource |
|---|---|
| 1 | Documentation: Getting Started |
| 2 | Documentation: Generic Format Asset? |
| 3 | Sample Project: Output to Kafka |
- Read more about layline.io here.
- Contact us at hello@layline.io.