Path to ExecutionCreating and Deploying Workflows
When you start working with layline.io, you will quickly learn that everything revolves around Workflows. A Workflow defines a logical chain of processing steps between one data-source and a number of data-sinks.
What does a Workflow provide?
A Workflow first and foremost describes a number of steps of what to do with data. For example analyse its contents, enrich them, filter information, etc. etc. Workflows can be very simple, or extremely complex. It’s really only limited by your imagination.
But there is more in that it also defines WHAT to read, where to read it FROM, where to write TO and HOW the data looks like when it’s read and written.
In addition to this a Workflow is the smallest denominator in terms of what you can run. You run at least one Workflow, but you can run many, DIFFERENT ones at the same time, too. You can also run the SAME Workflow many times in order to scale processing power and provide the resilience which you require for your specific use case.
To get a better understanding how Workflows are being used within layline.io let’s walk through a brief explanation and example:
Workflow Configuration
As said, everything revolves around Workflows. The complete lifecycle of a Workflow from creation, deployment, change, test, etc. is managed from within the web-based Configuration Center.
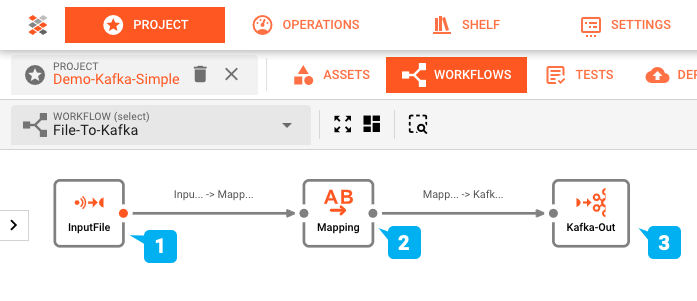
In the example above we have a very simple Workflow which reads from a file (1), maps data from the input data format to another format (2), and then outputs the data to a Kafka topic (3).
Workflows can take on almost any complexity in order to reflect specific business requirements.
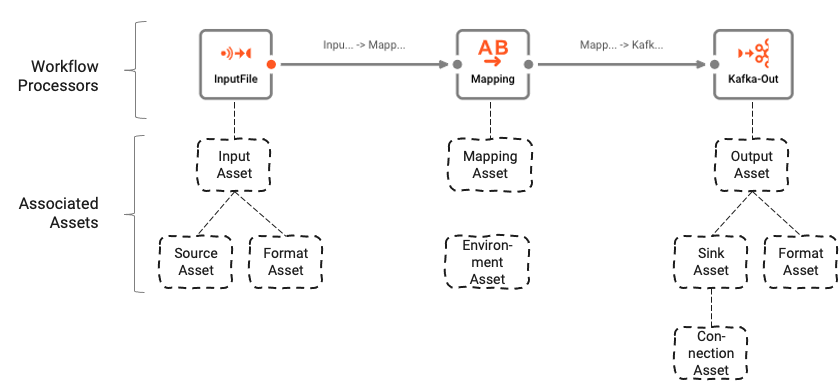
The individual “boxes” in the Workflow are called “Processors”. Processors are either configured individually, or based on so-called “Assets”.
Assets are best understood as basic function blocks. Let’s look at some examples to get a better idea:
- S3 Source Asset: An Asset which knows how to read from an AWS S3 store.
- Javascript Flow Processor Asset: An Asset which can be /programmed/ to fulfill tasks in very individual business logic.
- Kafka Output Processor Asset: An asset with the capability to output data to Kafka.
and so on.
Assets can serve as templates for Processors, thus allowing to reuse configured functionality either within the same Workflow, or in other Workflows which require parts of the same functionality. Assets can rely on other Assets, e.g. a Kafka Source Asset relies on a Kafka Connection Asset.
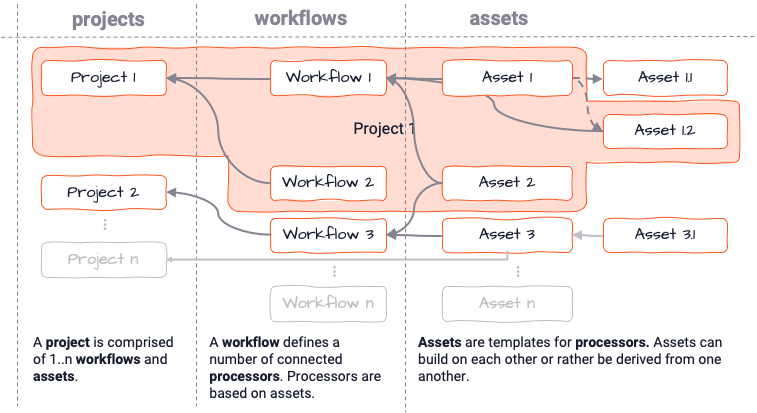
The broader configuration context in which a Workflow lives, is called “Project”. There is no limit to how many Workflows, Processors and Assets can live within a Project:
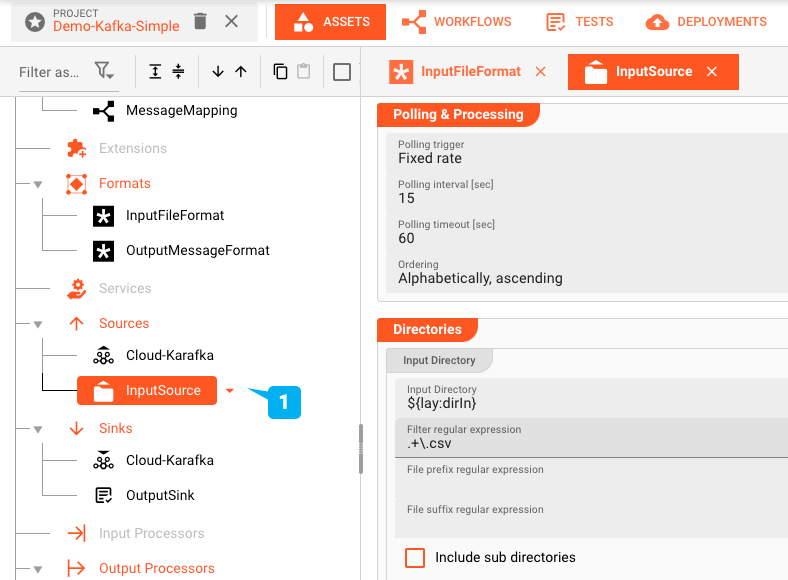
All configuration takes place in the Configuration Center which is part of layline.io. In there Workflows are configured using the built-in Workflow Editor (see image "Workflow Editor and Setup"). Assets in turn are configured using respective Asset Editors:
Using the Configuration Center, it is fairly simple to put together a number of Workflows which serve the purpose of attending to various different data sources, treat and analyse information, and then output results to data sinks.
The Configuration Center also provides various mechanisms to test connections and configured functions within Workflow, without having to deploy them to a Cluster.
Workflow Deployment
Once Workflows have been configured, the next step would be to deploy them to a
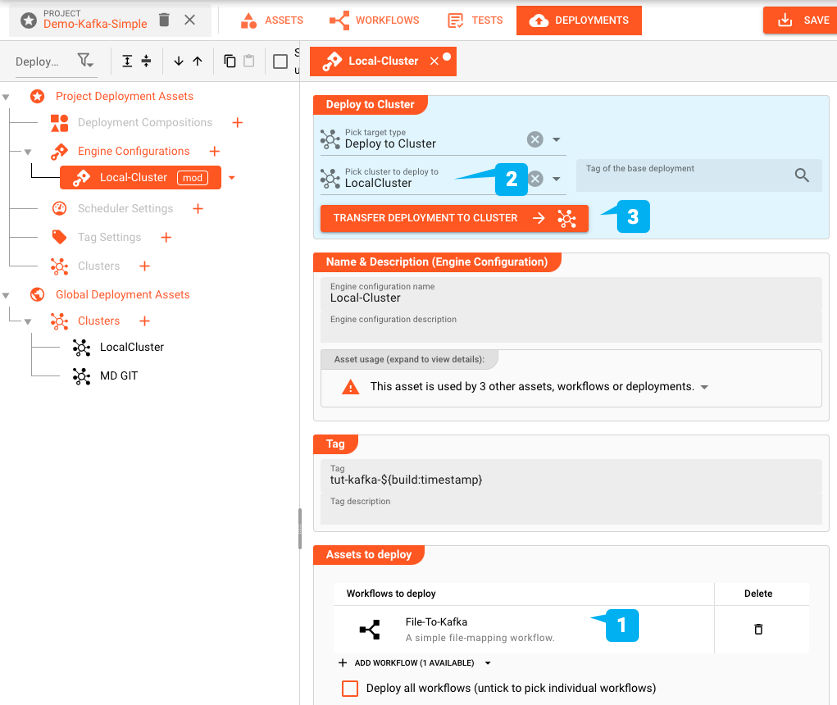
You can pick one or more Workflows to deploy (1) to a Reactive Cluster of your choice (2) and then execute the deployment (3). This will transfer the Workflows you selected for deployment, and all related assets and config data to the target Reactive Cluster, where it can then be activated for execution.
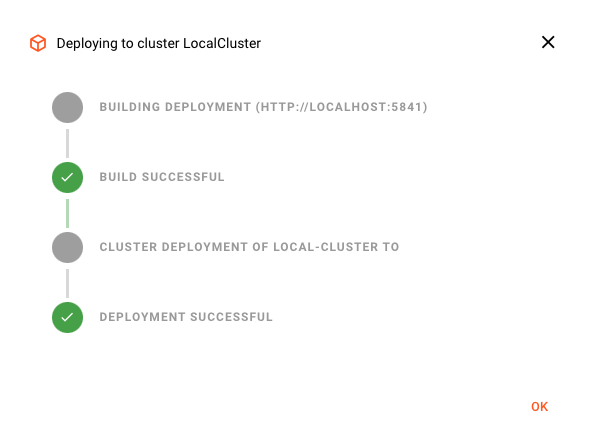
Once activated, Workflows will instantly process data available to them. Processing can be monitored either via the Configuration Center, or through 3rd party tools like Grafana. The following image shows a fraction of the monitoring options you have from within the Configuration Center:
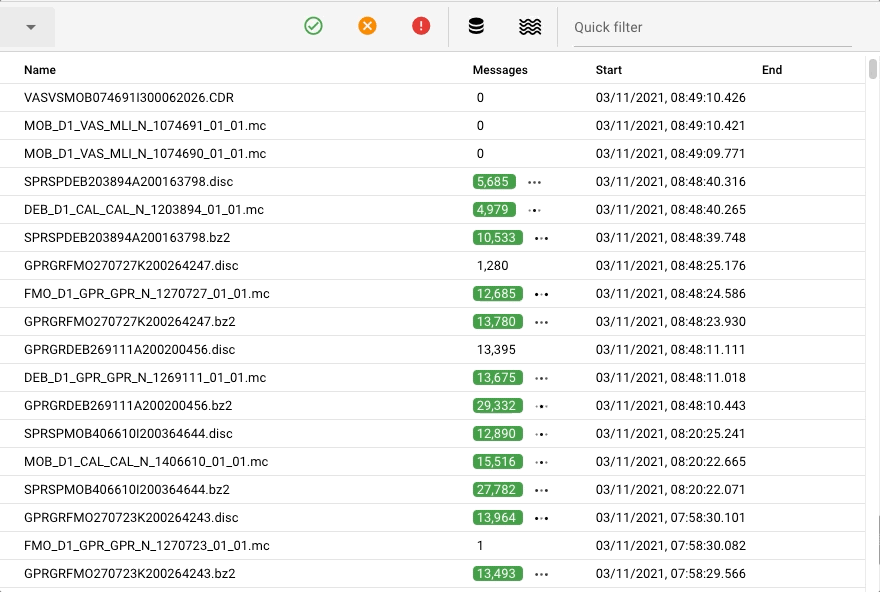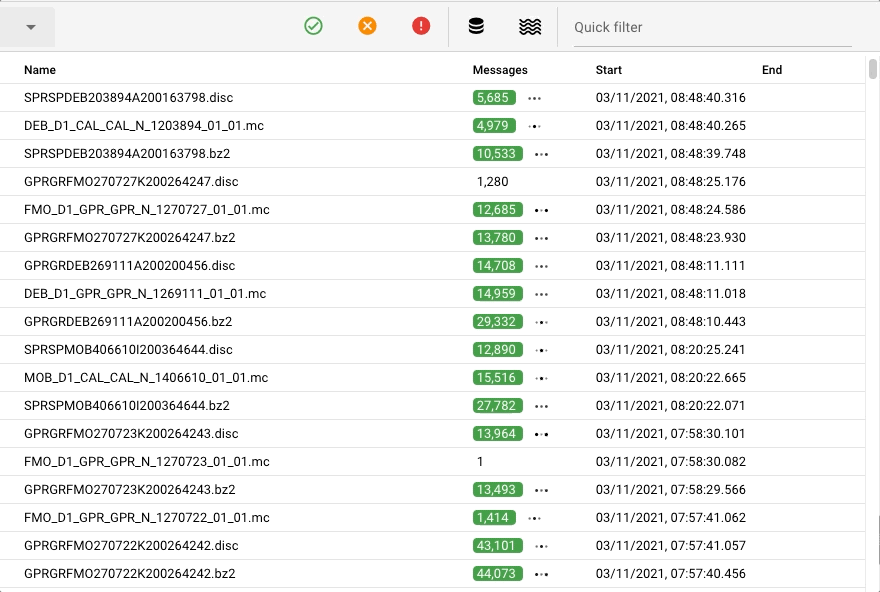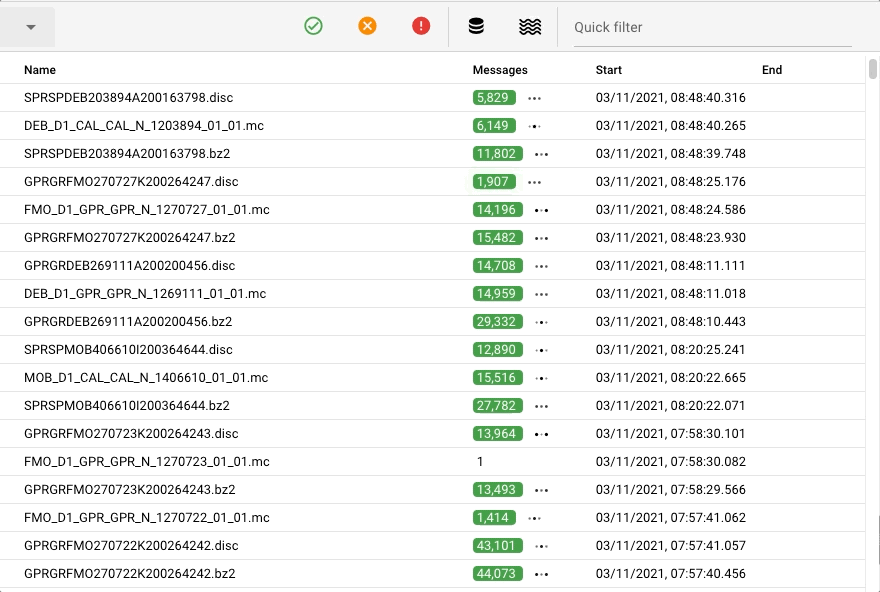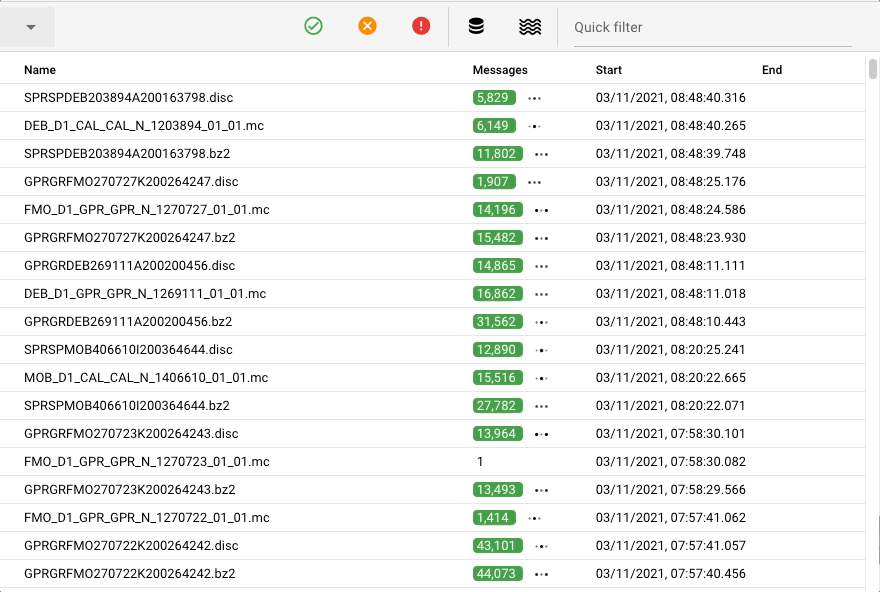
Summary
layline.io out-of-the-box provides everything required to create, deploy, run and monitor complex event-data processing scenarios (aka Workflows). The architecture allows for tiny deployments as well as XXL distributed local and cloud deployments.
What is layline.io?
A Scalable Platform for Fast Data
Select section for more info: