Scalability, Resilience, and DistributionReactive Cluster Concept
layline.io is designed to provide utmost scalability and resilience. To achieve this, layline.io uses a number of mechanisms, among them reactive stream management.
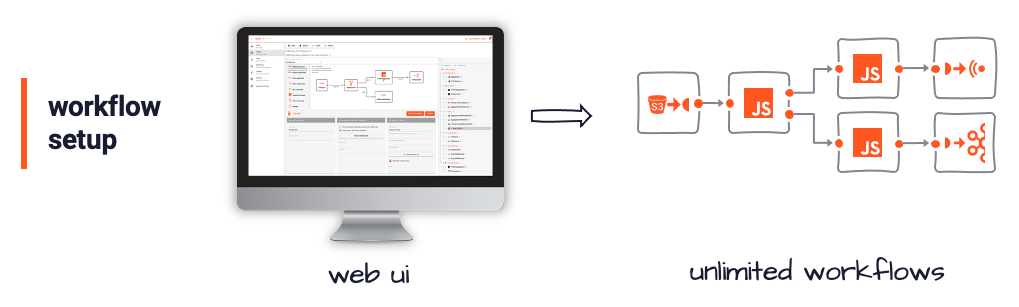
Workflows
Workflows are at the heart of any configuration within layline.io. They define an end-to-end processing chain for specific event-types. Configuration of Workflows is performed via the web-based Configuration Center, which will also help you with the logic.
Reactive Engine
Workflows configurations are then executed by one (or many) Reactive Engines (RE). Reactive Engines represent the physical processes and provide the actual execution context for Workflows.
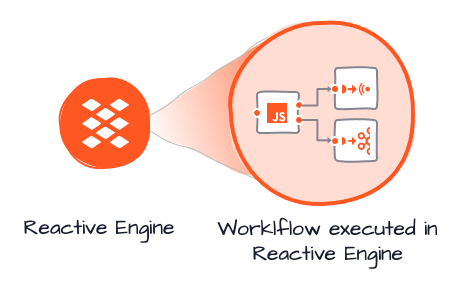
Each RE can run not just one Workflow, but many different ones, and then on top of this many instances of each Workflow. How many depends on how your specific deployment is set up and how many resources are available to an RE.
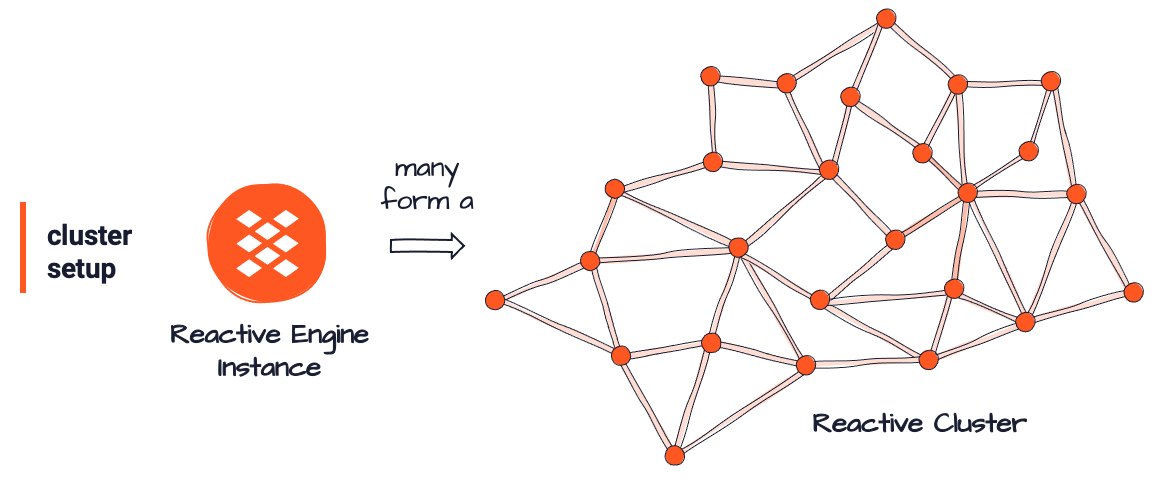
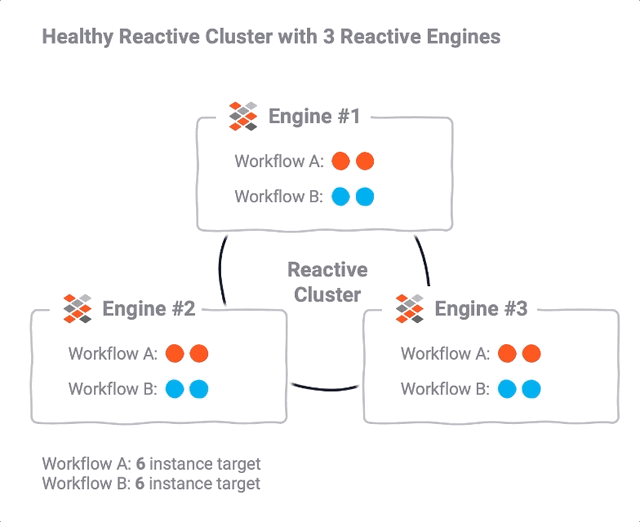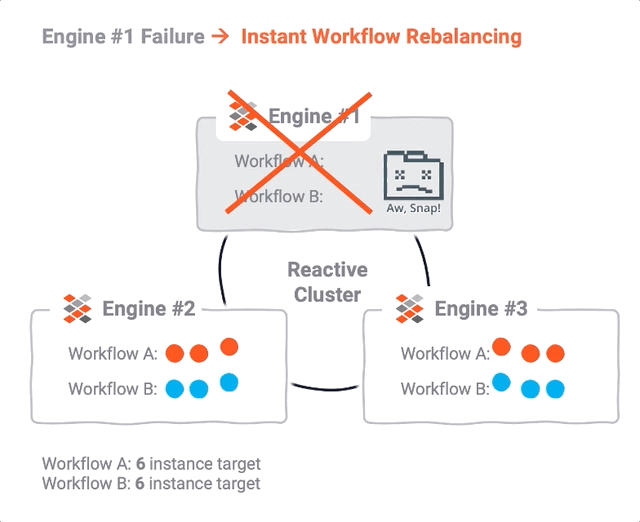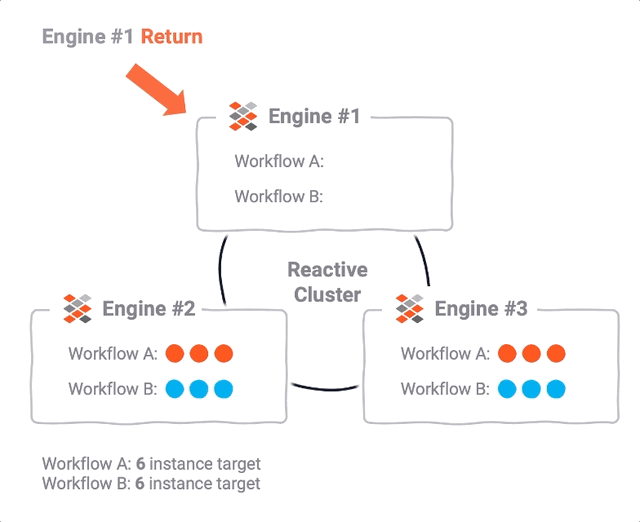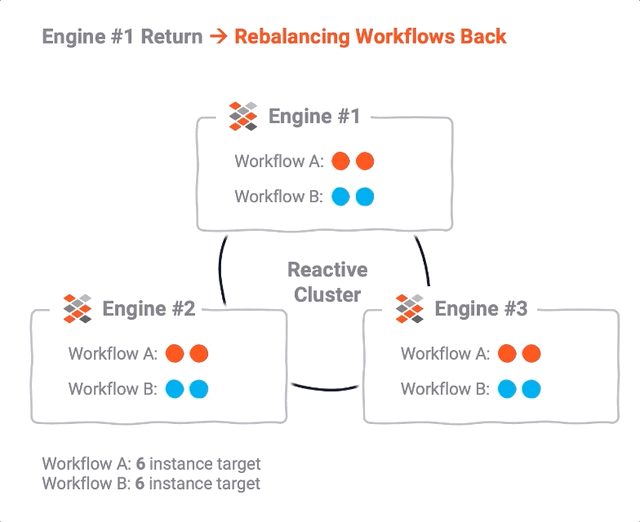
Reactive Cluster
You can run one Reactive Engine on its own, or run many of them in concert. Together they form what we call a Reactive Cluster (RC). An out-of-the-box standard installation of layline.io will run one Reactive Engine, but that of course does not provide the desired scalability and resilience. One engine is also not distributable.
In mission critical production environments you will therefore instantiate multiple REs to form a Reactive Cluster.
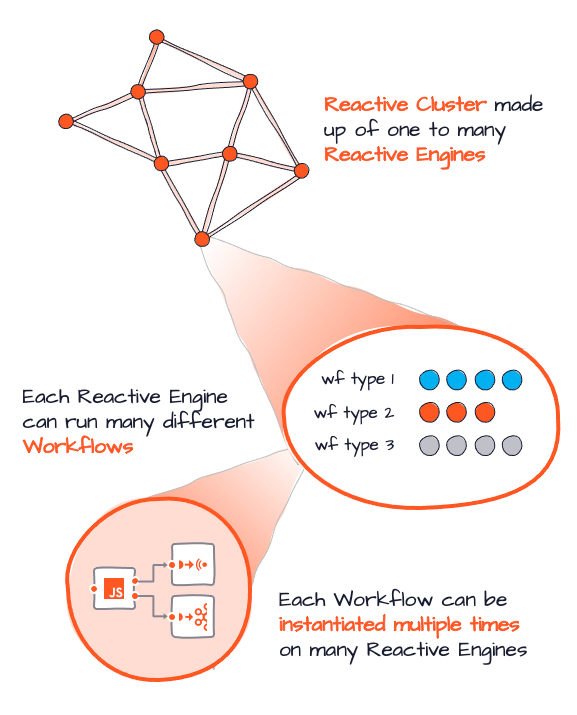
The combination of Reactive Engines and the Reactive Cluster then provide three important features:
- Scalability
- Resilience and Balancing
- Distributability
Scalability
You can scale processing by adding Reactive Engine instances to the Reactive Cluster. In addition to this - and as explained - each RE can run one or more configured different Workflows. Each Workflow can then be instantiated multiple times on one or multiple REs. So there are two scalability vectors:
- Number of Reactive Engines
- Number of Workflow instances running on each RE
All of this can happen dynamically. layline.io supports to automatically (or manually)
- add or remove REs to the Cluster at runtime, thus allowing the Cluster to breathe depending on load, much like a server-less solution,
- schedule the number of total workflow instances up or down depending on requirements.
The boundaries of doing so are really just limited by available resources, whether locally or in the cloud.
Resilience and Balancing
Resilience refers to uninterrupted availability, even in the case of selective outages (failures).
In line with the Reactive Manifesto, and based on reactive stream management, layline.io was designed from the outset with a “let it crash” mindset. This does not only require unaffected parts of a system to survive a crash of affected parts, but to rather make sure that failed functions are re-spawned and re-balanced across still available resources in a Reactive Cluster.
These are essentially the same techniques used in the context of scaling up and down at runtime, but taking into account heartbeat and failure information from all participants across the cluster.
Distribution
The way layline.io forms the Reactive Cluster - including adding reactive stream management - the Cluster is that of equals, rather than that of a cluster of centralized coordinators with dependent satellites.
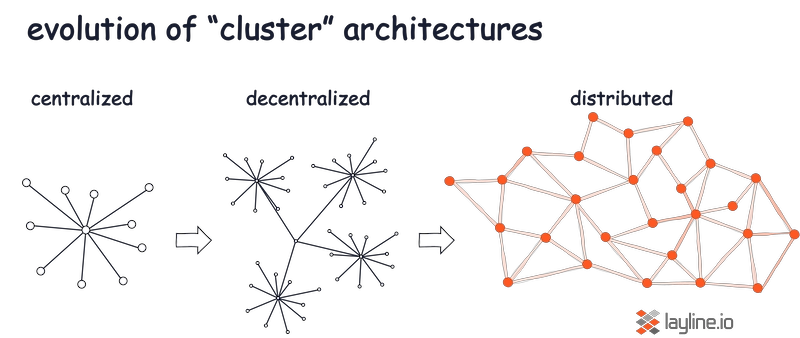
The layline.io Reactive Cluster creates a mesh of Reactive Engines which coordinate amongst themselves in real-time, exchanging administrative information about the state of the Cluster and its members. This allows to form a Cluster which does not only extend a physical rack of hardware, but span geographies while maintaining one coherent Cluster across all Engines.
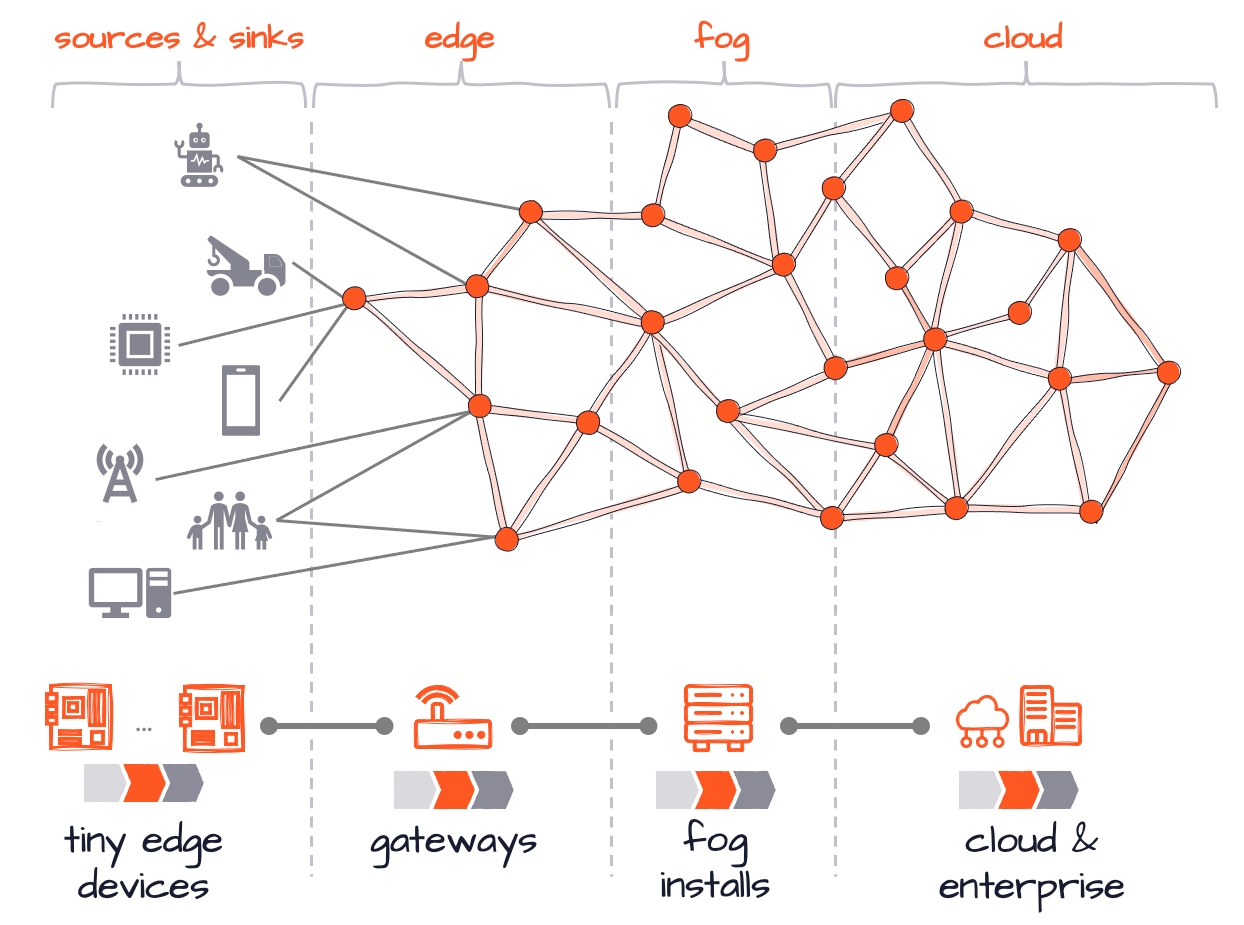
The following image shows an example of what this could look like in which one Cluster spans from cloud to edge, while the contained Reactive Engines take on different specific tasks depending on where they reside in the Reactive Cluster:
Summary
layline.io is created with safety in mind. This is true for scaling with your needs as well as ensuring non-stop operations. The unique architecture allows to cover even future distribution scenarios as depicted above. At the same time the small footprint of layline.io enables you to run on small devices like Raspberry Pi’s or simply your laptop, providing exactly the same mechanisms as in a XXL execution context.
What is layline.io?
A Scalable Platform for Fast Data
Select section for more info: