MotivationWhat is layline.io?
layline.io is an opinionated event-data-processor. It wraps the power of reactive stream management in a framework which makes setup, deployment and monitoring of large scale event data processing requirements easy and straightforward. It provides everything you would expect from a product-based solution including upgradability, cloud-native-grade resilience and scalability, among other features.
It features a sophisticated reactive real-time event-data-processing framework under the hood. layline.io integrates it into an easy to use platform, which abstracts the complexity away, while providing its functionality and more. It adds many important features such as generic format data definition, workflow definition, deployment techniques, monitoring and many, many more.
There are a few other good message and event-processing-frameworks in the wild. The best of which come in the form of programming libraries. Using them, commonly entails a huge learning curve, before developing everything from scratch. Like with everything that is custom-made from scratch, 80% of the effort and money spend does not flow into solving the actual problem, but are spent on creating ancillary functionality like error-handling, monitoring, operations, and so forth. And no matter how hard you try, you end up with hard-coded functionality geared towards the specific business problem you are solving.
While there may be reasons you want to trod down that path, it is highly inefficient. This conduct is simply unaffordable to many, and an unnecessary effort to most.
layline.io overcomes this by providing the power of reactive stream management with out-of-the-box core functionality so that you do not have to re-create it, leading to huge time- and budget-savings and avoidance of unforced errors.
Business Drivers
The world is transitioning from analog to digital at an ever faster pace. These transformation processes lead to ever-increasing requirements towards data gathering, data analysis, and data exchange. Mainly in real-time. While there are ways to manage, these are - in many ways - exclusive to large corporations with respective IT-muscle and budgets.
The volume of information is bound to grow at a rate of 50% each year, and may likely exceed this expectation. To stay competitive and ahead businesses need to be able to "play" but at the same time focus on their core-competence (mostly not IT).
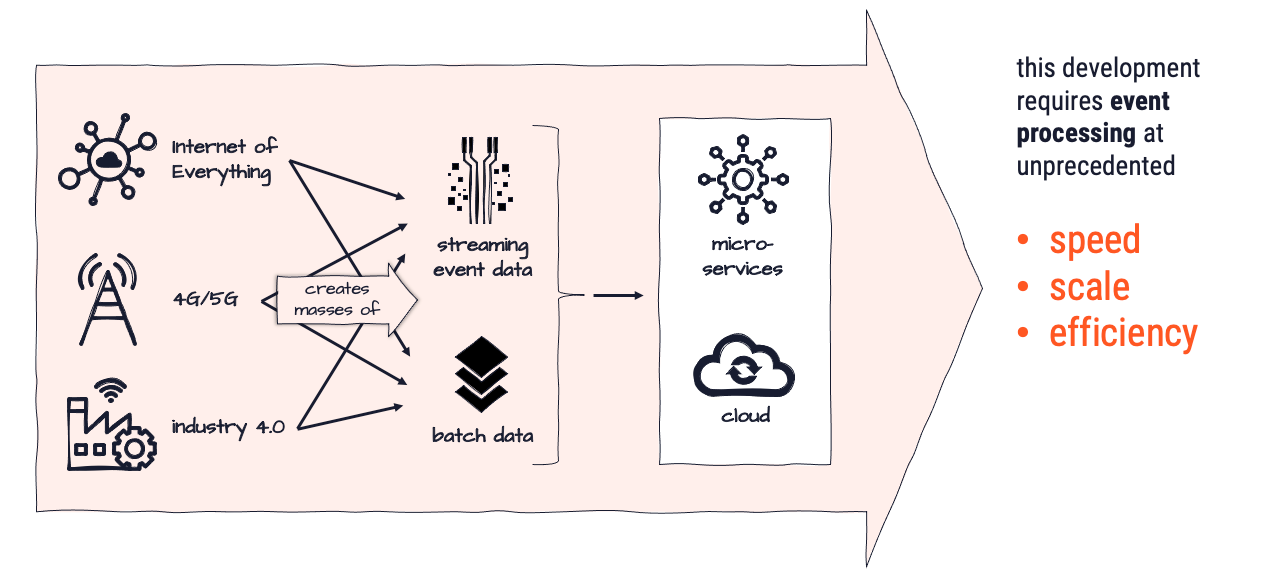
What motivated us to create layline.io were a number of real-life problems in the area of event-processing, which were largely unaddressed by existing solutions. We deemed these issues so important, that we thought it is worthwhile addressing them with a new product.
- Real-time volume to increase tenfold in the next few years.
- Companies struggling to reap transactional value of real-time data (do something useful with it in the first 0- 3 seconds).
- Companies‘ system architectures solidly migrating to cloud architectures, without proper solutions to support this in all aspects.
- Lack of actual products to support distributed real-time event processing, instead of having to create custom programmed solution based on development toolkits.
- Availability of awesome streaming technology like akka and flink, which unfortunately have a steep learning curve and do not allow for complete setup and operations by configuration.
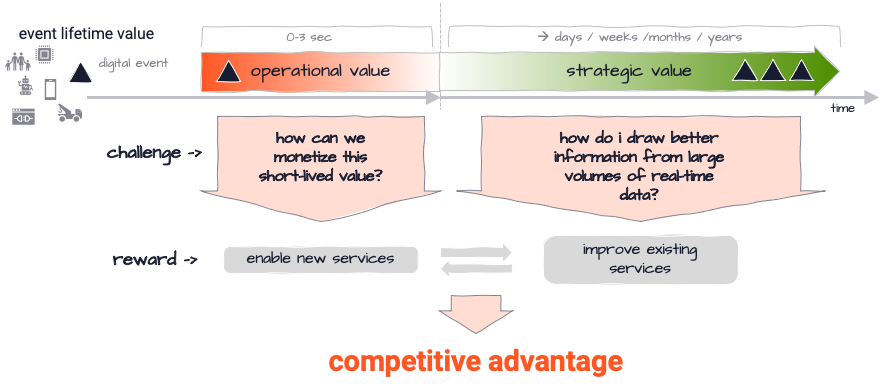
Can’t I solve these problems by other means?
Yes, but it’s tough, lengthy and will cost you dearly. In the past years, and in the context of the Big Data evolution we have witnessed a myriad of new concepts and truly awesome technologies emerge. Cloud, process distribution, asynchronous processing and many more, just to name a few.
You have seen many cool examples and show cases, for sure. None of them, however, were simple to create and required lots of time and specialized staff and resources.
Solution
layline.io wants to make this easy by enabling users to
- create individual event workflow processing logic
- which can be deployed across a distributed processing network (physically, logically and geographically)
- which asks to configure and deploy everything without custom coding, and
- supports any event-processing scenario from small to super extra large in a highly scalable and resilient environment (or simply on your laptop!)
layline.io provides a solution to integrate real-time and non-real-time event/message-exchange in a relatively easy and configurable way. Time and cost to production are exceptionally low compared to other solutions.
Now on to the show ...
How it works
The story in a nutshell
1. Creation
Using the web-based Configuration Center, you create a new Project. Within the Project you create 1..n Workflows. Each Workflow represents one event data flow which can range from very simple to very complex. The Project itself merely acts as an organizational container. The Workflow in turn is assembled out of a number of Processors which can be pre-configured in Assets. Assets can be reused in Processors throughout the Project. Assets can also inherit configurations from other Assets of the same kind. Much like class inheritance does.
Projects, together with its Workflows, Assets and other parts, are stored by the Configuration Server. The Configuration Server also provides the web-based Configuration Center.
2. Deployment
Once your configuration is ready, you deploy all or a selection of the Workflows to a Reactive Engine. A Reactive Engine runs on a Node. A Node can be either your laptop or a Docker container et al running in a remote Kubernetes cluster. The Reactive Engine can be part of a Logical Cluster of many Reactive Engines running in concert. We call this the "Reactive Cluster" (In fact, a single Reactive Engine could be considered a logical Cluster already). Once the Project is deployed, you can activate it. The Reactive Cluster then takes the designated Workflows into operation. If you have deployed to a Reactive Engine which is part of a cluster of Reactive Engines, then the Workflows are automatically propagated to all the Reactive Engines running within the same logical Cluster.
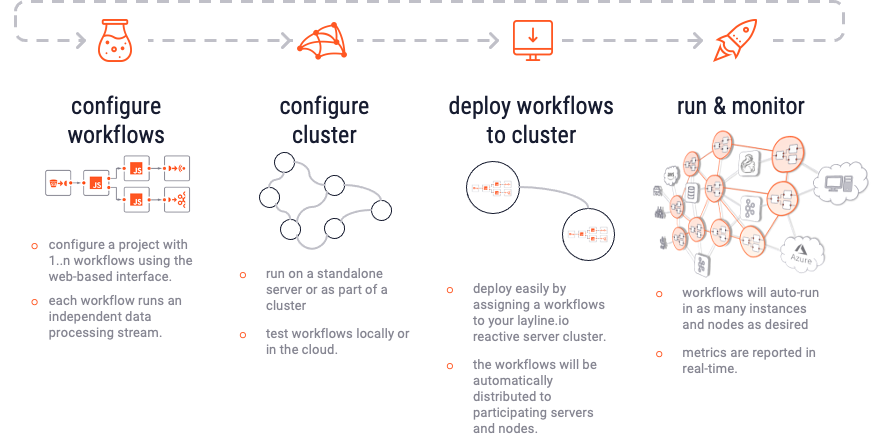
3. Monitoring
You can monitor execution on the Reactive Engine or Reactive Engine Cluster through the web-based Configuration Center. It is possible to tweak operating parameters during runtime, for example how many Workflows should be running in parallel and more. If you need to stop parts of the processing (e.g. for maintenance) you can do so using the Operations part of Configuration Center. You can change how the workload is balanced among Nodes and Workflows.
4. Repeat
To change any of the configuration you can simply repeat the process. layline.io allows to inject new and changed Workflows while everything is running to eliminate potential downtime.
What is layline.io?
A Scalable Platform for Fast Data
Select section for more info: