
Lo que estamos demostrando
Estamos mostrando un Proyecto simple de layline.io que lee datos de un archivo y envía su contenido a un tema de Kafka.
Para seguir la demostración en una configuración real, puedes descargar los recursos de este Proyecto desde la sección de Recursos al final. Lee esto para aprender cómo importar el proyecto a tu entorno.
Configuración
El Workflow
Resumen
La configuración del Workflow de esta demostración se realizó utilizando el Workflow Editor de layline.io y se ve así:
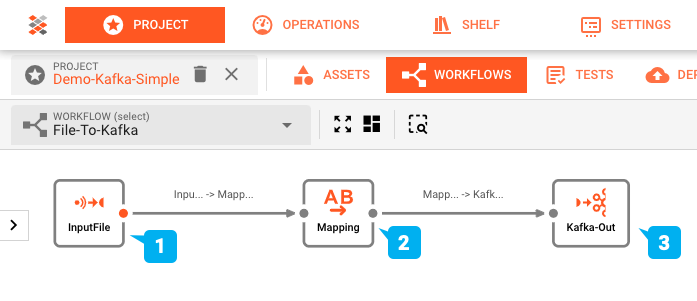
- (1) Input Processor: lee un archivo de entrada con una estructura de encabezado/detalle/tráiler, luego
- (2) Flow Processor: mapea esto a un formato de salida, que posteriormente es
- (3) Output Processor: escrito en un tema de Kafka.
Para los fines de esta demostración, estamos utilizando un tema de Kafka alojado por Cloud Karafka. Por lo tanto, si ejecutas la demostración tú mismo, no necesitas tu propia instalación de Kafka.
Configuración de los Assets subyacentes
El Workflow se basa en una serie de Assets subyacentes que se configuran utilizando el Asset Editor. La asociación lógica entre el Workflow y los Assets se puede entender así:
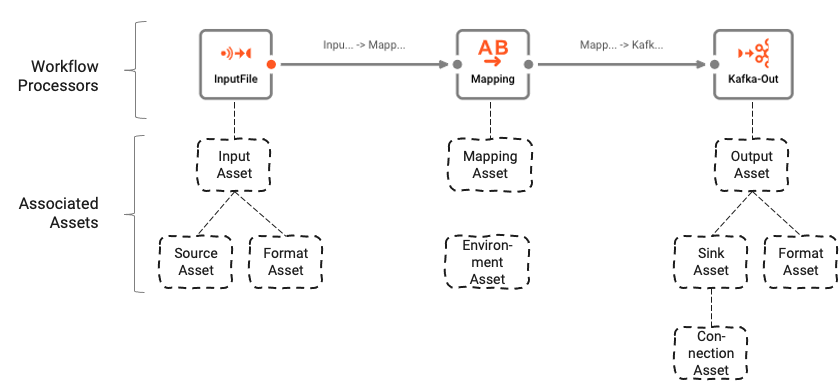
Los Workflows están compuestos por una serie de Processors que están conectados por Links.
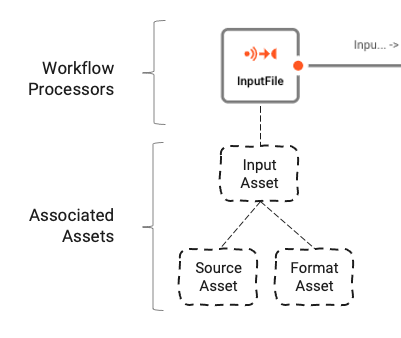
Los Processors se basan en Assets. Los Assets son entidades de configuración que pertenecen a una clase y tipo específicos. En la imagen anterior, podemos ver un Processor llamado "InputFile", que pertenece a la clase Input Processor y al tipo Stream Input Processor. A su vez, depende de otros dos assets, "Source Asset" y "Format Asset", que son de tipo File System Source y Generic Format respectivamente.
En resumen:
- Un Workflow está compuesto por Processors interconectados.
- Los Processors dependen de Assets que los definen.
- Los Assets pueden depender de otros Assets.
Asset de Entorno: "My-Environment"
Primero: layline.io puede ayudar a gestionar múltiples entornos diferentes utilizando Environment Assets. Esto es de gran ayuda al usar el mismo Proyecto en entornos de prueba, staging y producción, que pueden requerir diferentes directorios, conexiones, contraseñas, etc. Estamos utilizando un Environment Asset (2) en este Proyecto.
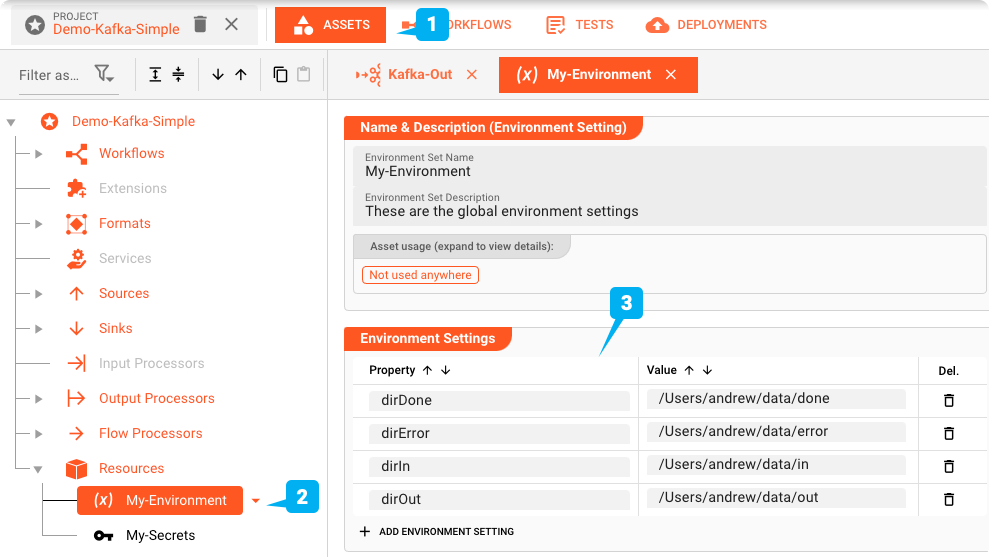
Variables como estas se pueden usar en todo el proyecto utilizando un macro como ${lay:dirIn}. Las variables de entorno del sistema operativo o de Java se prefijan con env: o sys: respectivamente, en lugar de lay:.
Stream Input Processor: "InputFile"
El Input Processor (nombre: InputFile / tipo: Stream Input Processor) se encarga de leer los archivos de entrada y reenviar los datos aguas abajo dentro del Workflow.
Generic Format Asset: "InputFileFormat"
layline.io proporciona los medios para definir estructuras de datos complejas con su propio lenguaje de gramática. El archivo en nuestro ejemplo es una muestra de transacción bancaria. Tiene un registro de encabezado con dos campos, varios registros de detalles que contienen los detalles de las transacciones, y finalmente un registro de tráiler.
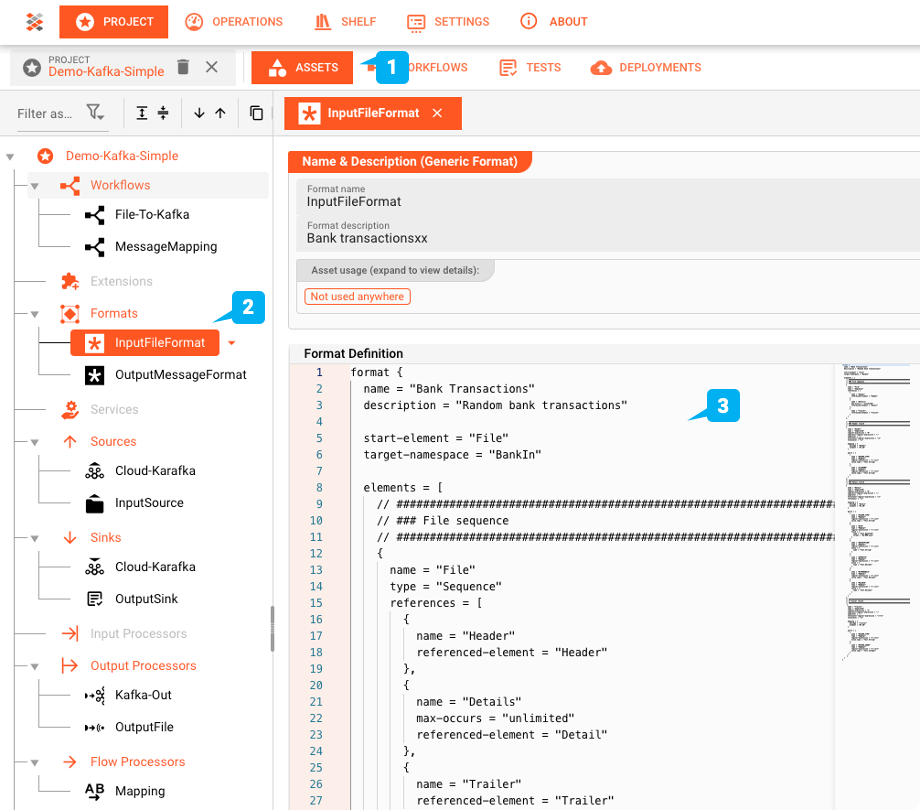
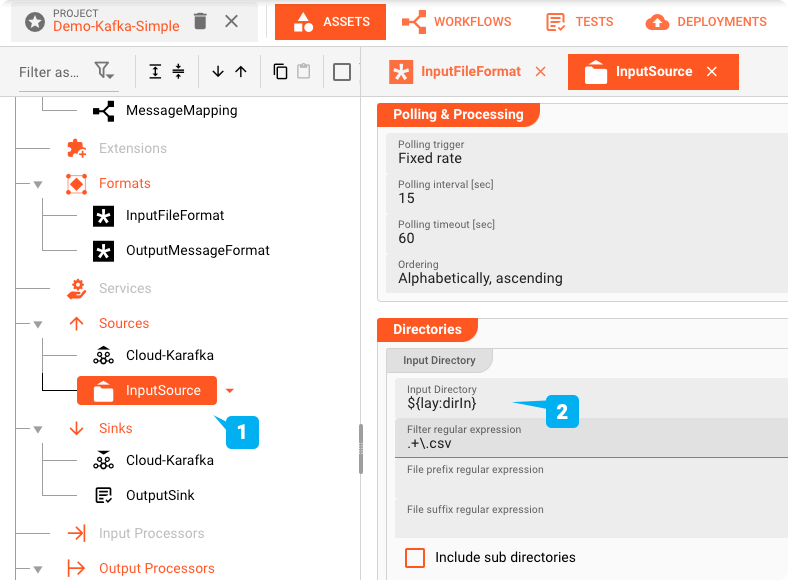
File-System-Source Asset: "InputSource"
El "InputSource" es un Asset de tipo File System Source que se utiliza para definir desde dónde se lee el archivo.
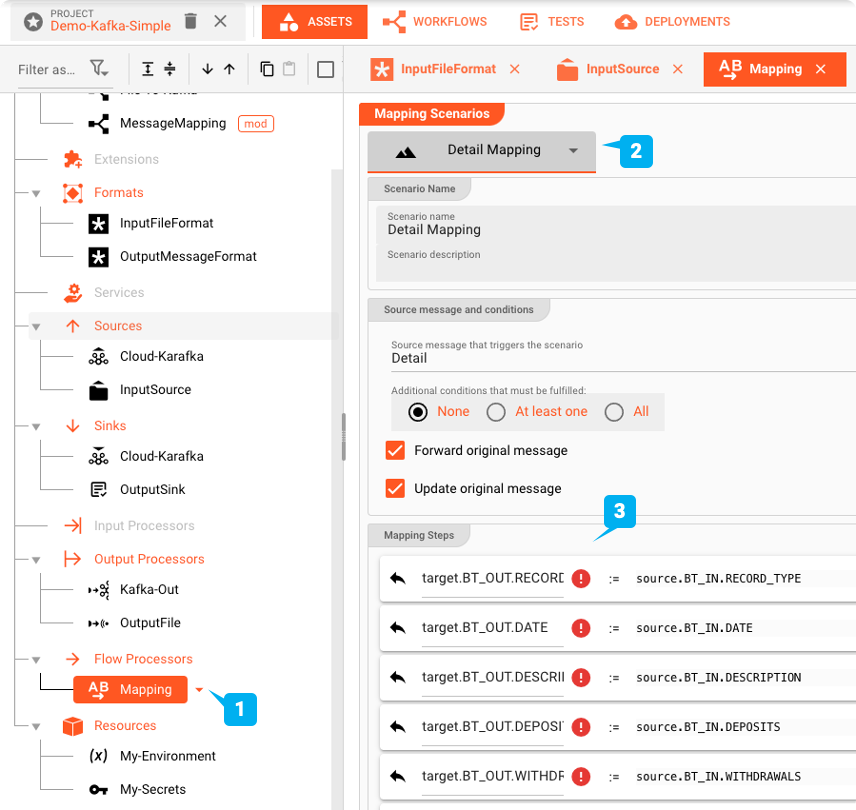
Flow Processor: Map
El Mapping Asset te permite mapear valores del formato de entrada al formato de salida.
Stream Output Processor: Kafka
El último Processor en el Workflow es el Output Processor "Kafka-Out".
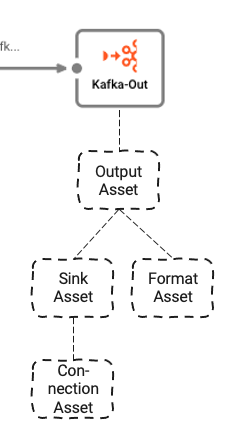
Depende de tres Assets subyacentes:
- Output Asset: Define los temas y particiones de Kafka a los que estamos escribiendo.
- Kafka Sink Asset: El Sink que el Output Asset puede usar para enviar datos.
- Generic Format Asset: Define en qué formato escribir los datos en Kafka.
- Kafka Connection Asset: Define los parámetros físicos de conexión a Kafka.
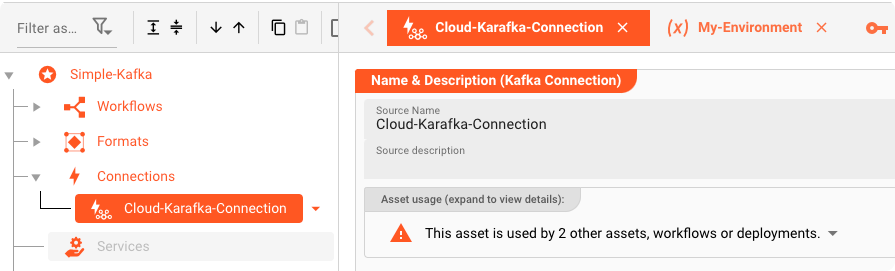
Kafka Connection Asset: "Cloud-Karafka-Connection"
Para enviar datos a Kafka, primero debemos definir un Kafka Connection Asset.
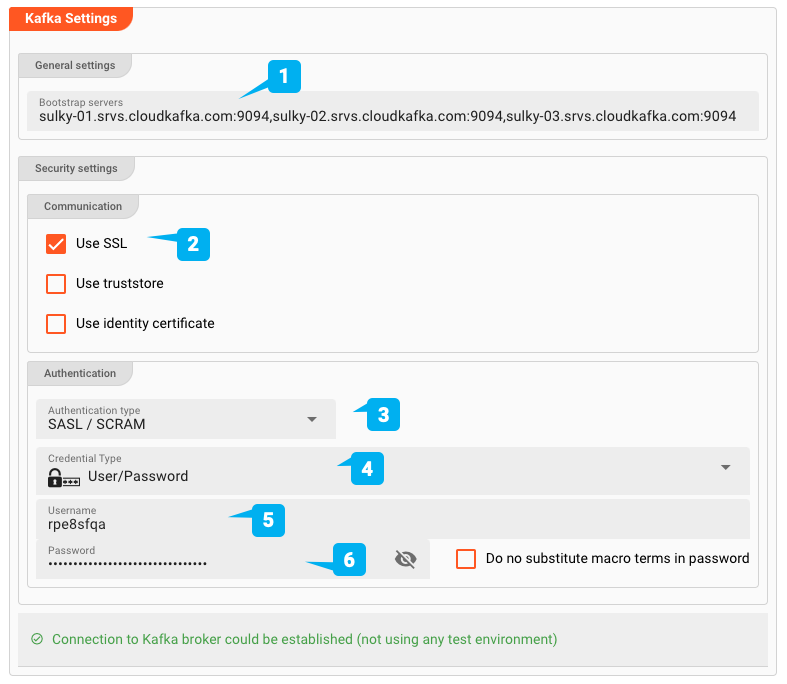
- (1) Bootstrap servers: Las direcciones de uno o más servidores Bootstrap.
- (2) Use SSL: Define si esta es una conexión SSL.
- (3) Authentication type: SASL / Plaintext, o SASL / SCRAM.
- (4/5/6) Credentials: Nombre de usuario/Contraseña.
Implementar y Ejecutar
Transferencia de la Implementación
Para implementar, cambiamos a la pestaña DEPLOYMENT del Proyecto:
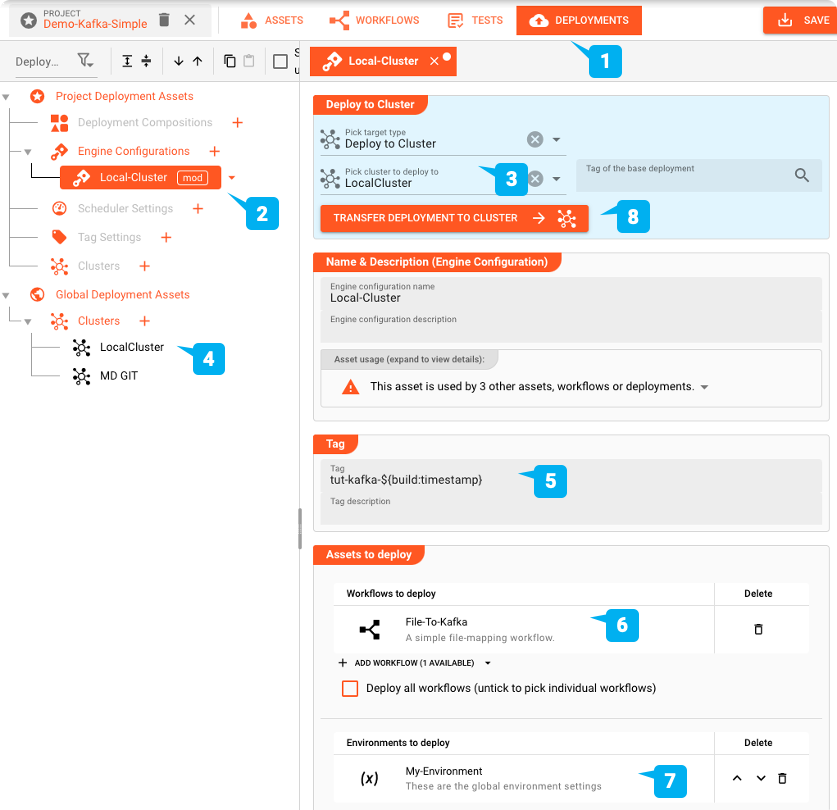
Creamos una Engine Configuration para implementar el Proyecto. Esto define las partes del Proyecto que deseamos implementar.
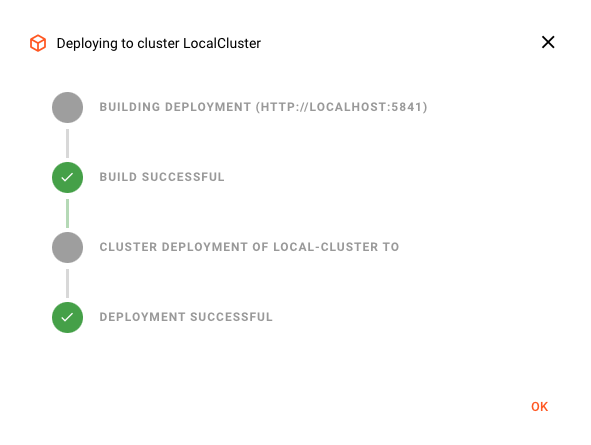
Activación de la Implementación
Cambiamos a la pestaña "CLUSTER":
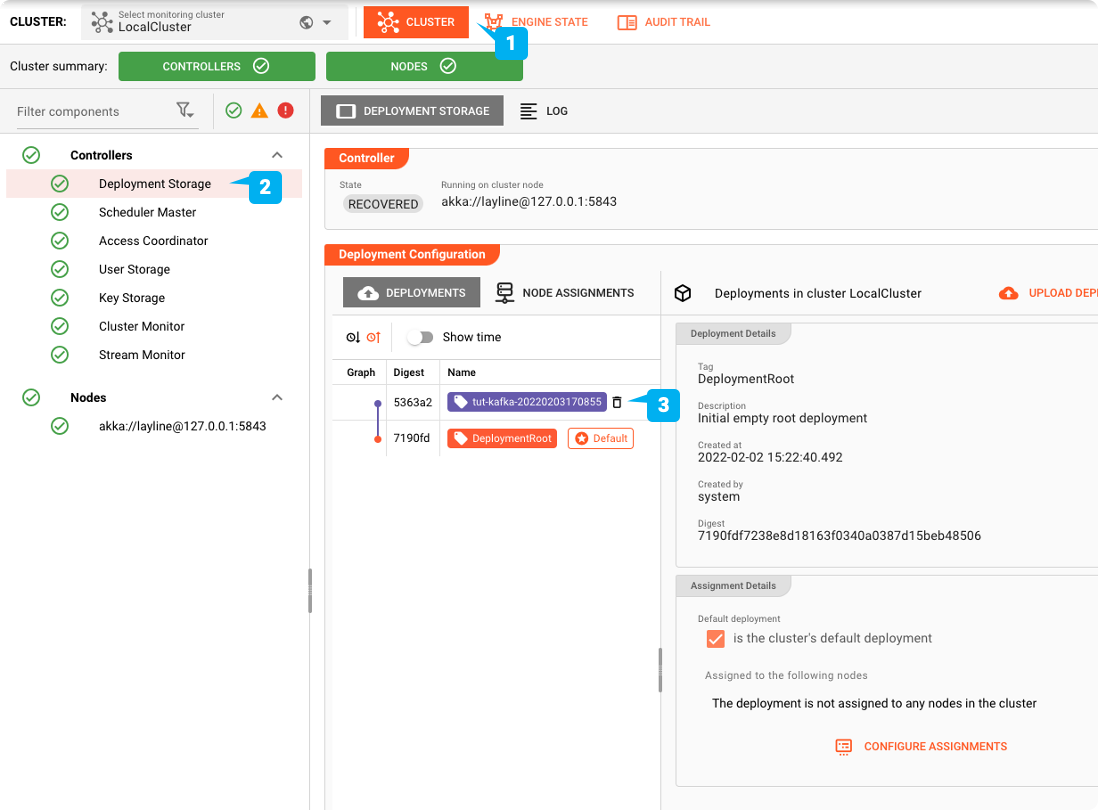
Convertirlo en la Implementación predeterminada
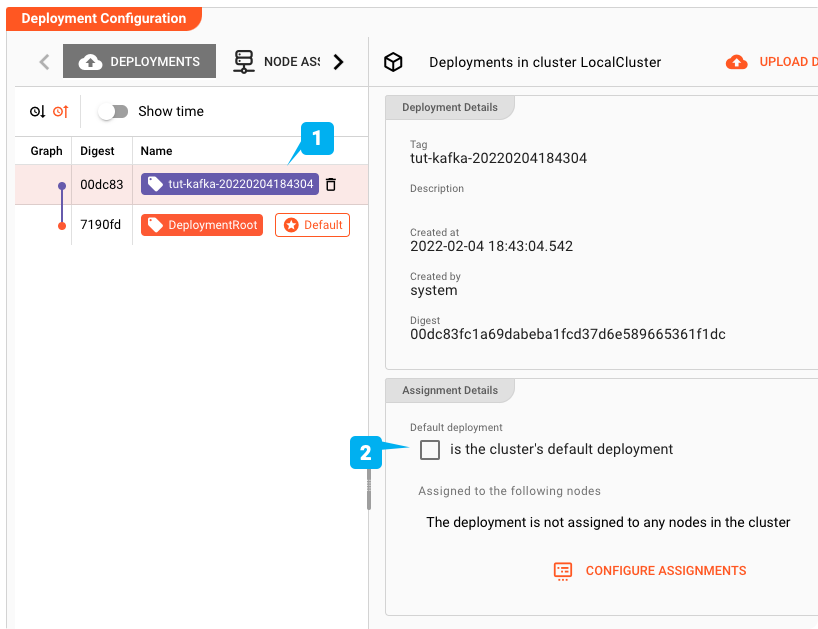
Programar
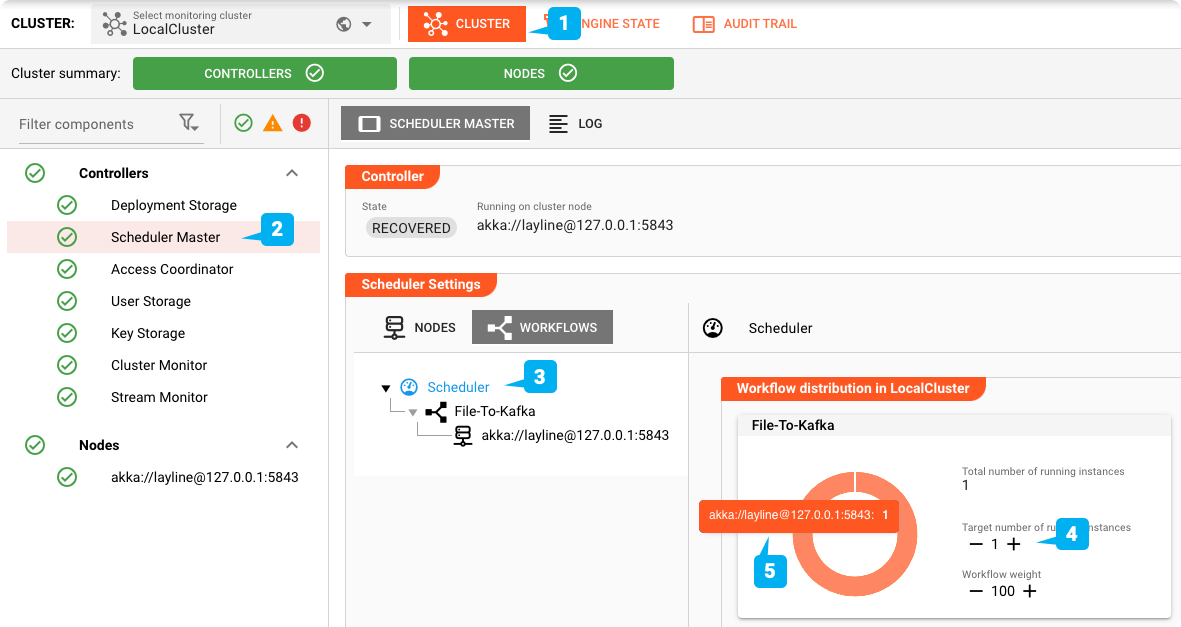
Estado del Engine
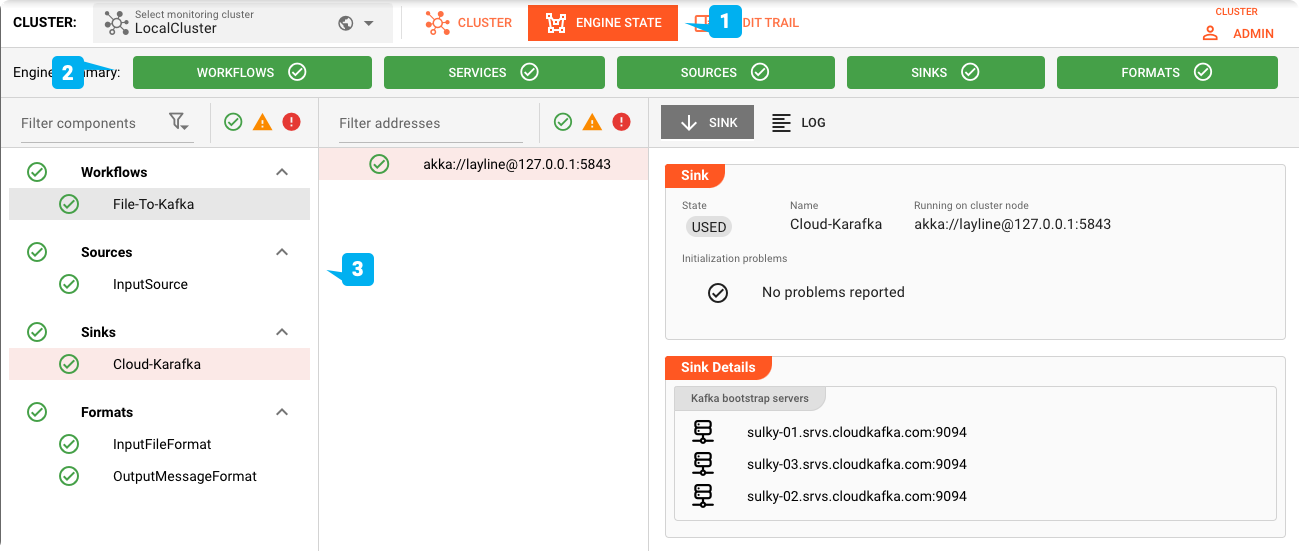
Alimentar el archivo de prueba
Para probar, colocamos nuestro archivo de prueba en el directorio de entrada que hemos configurado.
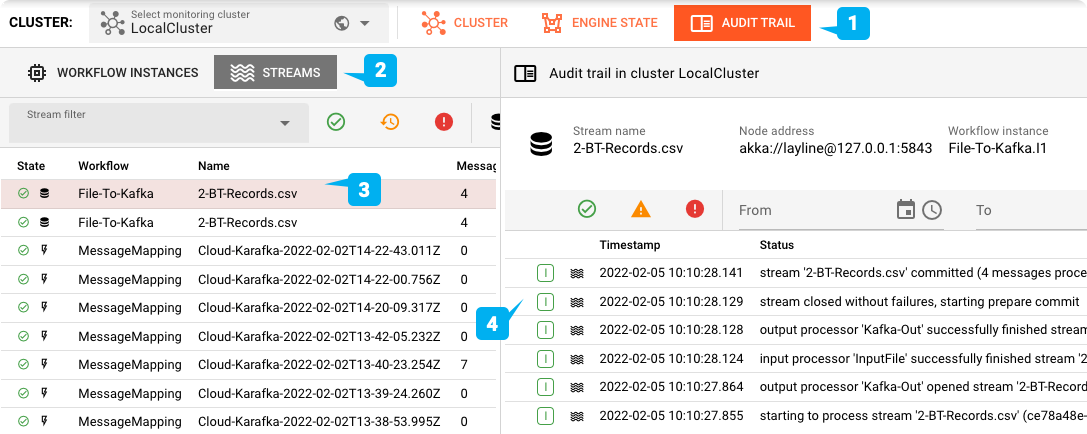
Puedes verificar el tema de Cloud Karafka utilizando una herramienta de tu elección:

Resumen
Esta demostración destaca cómo puedes crear un Workflow de File-to-Kafka de manera rápida y sencilla. Y obtienes mucho más de forma predeterminada:
- Reactive — Adopta el paradigma de procesamiento reactivo.
- High scalability — Escala dentro de una instancia del motor y más allá.
- Resilience — Tolerante a fallos en entornos distribuidos.
- Automatic deployment — Implementa configuraciones cambiadas con un solo clic.
- Real-time and batch — Ejecuta ambos utilizando la misma plataforma.
- Metrics — Generación automática de métricas para monitoreo (por ejemplo, Prometheus).
Recursos
| # | Descripción |
|---|---|
| 1 | Github: Simple Kafka Project |
| 2 | Archivos de prueba de entrada en el directorio _test_files del Proyecto |
| 3 | Credenciales de Cloud Karafka encontradas en el archivo cloud-karafka-credentials.txt |
| # | Documentación |
|---|---|
| 1 | Getting Started |
| 2 | Importing a Project |
| 3 | What are Assets, etc? |
- Lee más sobre layline.io aquí.
- Contáctanos en hello@layline.io.

