
What is data-pressure?
You hear a lot about data-pressure when it comes to non-stop systems. What is it and why is it so important?
Pressure in the physical sense describes an imbalance between gas or fluid between two confined compartments. It goes both ways until an equilibrium is reached. If you want to manage it, you usually put a valve between the two.
In data processing systems data-pressure, or upstream-pressure describes the amount of data which is ready for processing. For file based (batch) solutions this simply describes the amount of files which are waiting to be processed (asynchronous). Processing speed is purely based on the processing power of the downstream actors and is demand based. Data-pressure in batch usually is no threat to system overload because it is implicit. The batch processing system will always only process as much as it can.
It's a very different story in modern, message-driven, real-time processing environments, however, where data-pressure is explicit because data needs to be processed as it arrives.
Importance of back-pressure in non-stop real-time systems
Message-driven use-cases usually require that data should be handled in real-time, at all times. Therefore, systems have to be able to scale elastically in order to handle peak loads, or free up unneeded resources during low data-pressure windows.
There are countless examples of architectures which clog-up when dealing with large data loads. This often results in a vicious-cycle which typically leads to cardiac-arrest of such an architecture. The main conundrum is a missing negative demand-signal (or high data back-pressure-signal) to upstream actors upon which they can react. If there were such a signal, appropriate actions could be taken.
Such actions could be:
- slowing processing down overall up the data stream, or
- spawning more processing power to handle the added pressure
Once upstream data-pressure decreases, the counter-measures can be reversed. More data can again be delivered, or previously activated processing power can be decommissioned.
So to summarize, we have:
- a data-signal or upstream-pressure which signals that data is available for processing, and we have
- a demand-signal or back-pressure which signals how loaded the downstream actors are, and whether pressure from upstream actors can be relieved on to downstream actors.
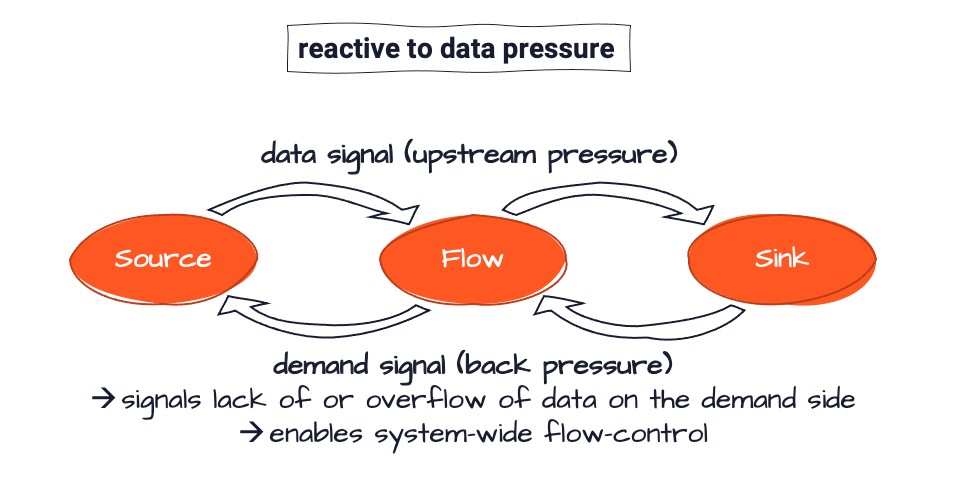
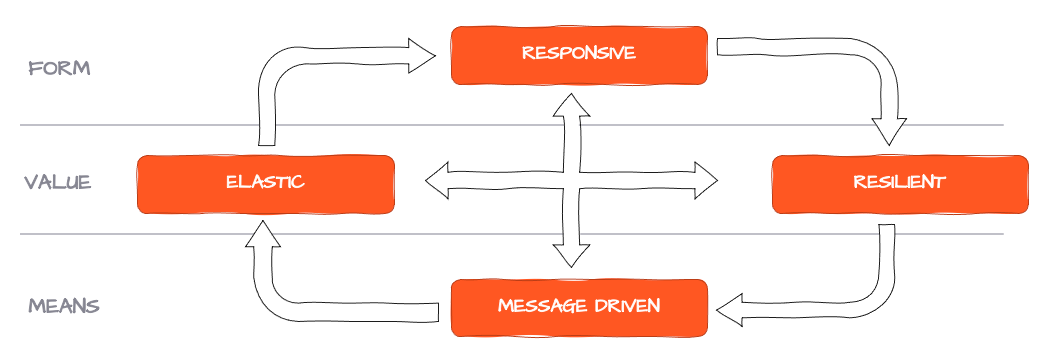
Using these signals, the system is able to negotiate an equilibrium between all participants which ensures that processing never stops, but rather slows down (or additional capacity is automatically made available). This problem is well recognized and defined in the Reactive Manifesto which requires systems to be message-driven, elastic and resilient, and therefore responsive to load. Systems which cater to these requirements are called "Reactive".
How layline.io handles it
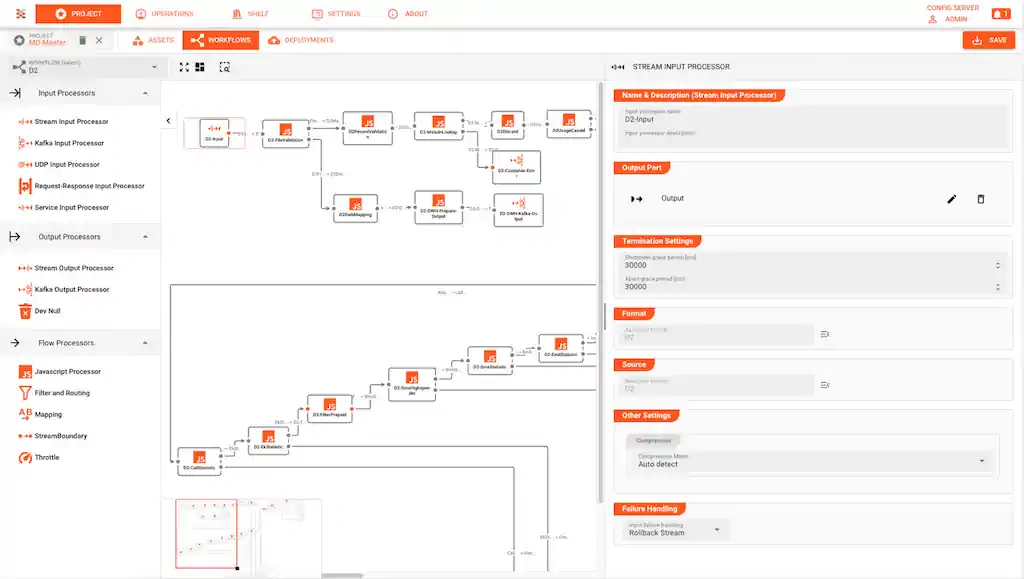
It sounds like the solution to the back-pressure challenge is simple. But it's actually hard to solve since all participants in this dance need to be data-pressure aware, both ways. Reactive stream management has solved this problem which is why layline.io takes full advantage it under the hood. It's not for the faint-of-heart, however, and comes with a steep learning and experience curve attached. layline.io shields its users from this complexity in an easy-to-use platform, which provides all production necessary features like UI-driven low-code configurability, one-click deployment, monitoring and much more.
Resources
- Reactive Manifesto
- Read more about layline.io here.
- Contact us at hello@layline.io.


