For some years now Microservices and Service-oriented architectures have been all the rage. Shortly after that containerization helped to abstract installed platform from deployed platform by packaging OS and dependent libs up with the actual application.
But where there is light, there is shadow. Working with and using Microservices comes with its own set of challenges. We found a pretty comprehensive list here. Let's look at some of main pros and cons:
Main challenges of Microservice development, deployment and operation
The Good
- Atomicity: Autonomous services can be treated individually in terms of development and execution (apart from interfaces).
- Resilience: Individual services are usually not compromised when it comes to failures in other services which leads to better resilience.
- Scalability: Individual services can be scaled elastically on-demand.
The Bad
- Loose coupling: Microservices usually do not know about each other and their broader execution context. They are atomic in nature. Communication between them comes with an overhead and is not standardized.
- Monitoring: Comprehensive monitoring of a variety of Microservices is extremely hard and almost impossible to do. Clearly uncovering individual problems across different services can be extremely hard due to different types of logs spread all over the place, unclear interdependencies between services and transaction spanning of services etc.
- Debugging: Errors which are occurring in a complex distributed Microservices architecture can be extremely time-consuming and expensive to trace. There is no overarching monitoring system, but rather individual logs and stack traces which need to be investigated in order to safely conclude what the cause of the error was.
- Security: An integral characteristic of Microservices are their interfaces/APIs. Especially in distributed environments each of them requires special care in regard to security. It's easy to lose oversight and control in such complex framework environments.
- Resilience: With lots of different types of Microservices, which may be developed by different teams, it becomes exponentially harder to ensure proper failover mechanisms, so that the whole system can act accordingly when one or more the Microservices fail.
- Deployment: Deployment of individual Microservices in a complex setup without downtime is hard to orchestrate and at times impossible to accomplish without restarting everything.
- Communication: There has to be some form of standardization of communication between Microservices in terms of serialization, security, request options, error handling and the list of expected responses. Some form of top-level design orchestration is very necessary or else will result in failed communication and latency issues.
This is just to name a few of the challenges. There are many more challenges when it comes maintenance, networking, team management etc. as you can imagine.
Solution: MicroConfigurations instead of MicroServices
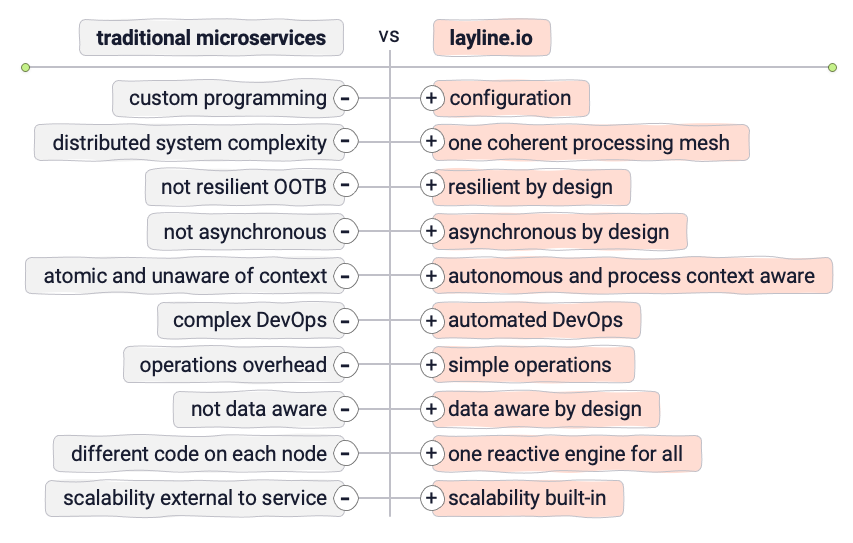
While the idea of Microservices is great, it can get very nasty very fast. Naturally the question is whether there is a way to keep the good parts of a Microservices setup and avoid the bad parts.
Micro-Configurations may be able to help here. We define Micro-Configuration (or MicroConfig) as a separation between actual service logic (the Configuration) and service execution (the Engine).
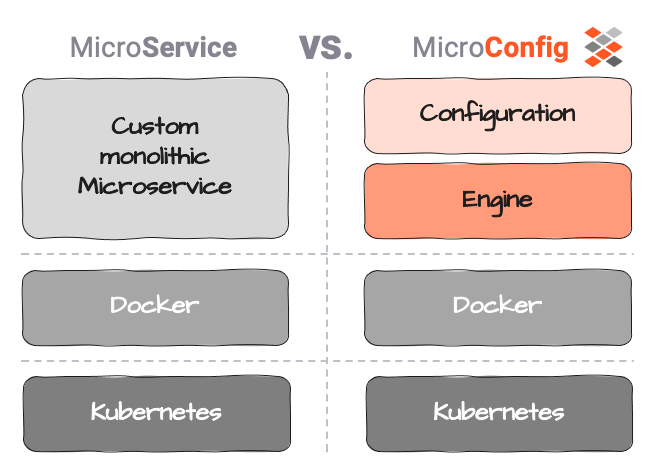
Configuration in this context shall be purely limited to the business logic, i.e. what to do with the data, what action to trigger, etc.
Execution is everything that makes execution of the Configuration possible:
- execution of the logic (configuration),
- centralized and standardized logging of activity and problems,
- orchestration of execution across services
- metrics reporting for monitoring
- debugging support
- standardised communication across service boundaries
- and much more.
This generally isn't a new concept in the world of tech.
Example: A typical database distinguishes between database structure (tables, indexes, constraints, etc.) and database engine (interpretation, storing, serving). While the engine is the same for every user, the structure is unique. Yet nobody would entertain the idea to hard code tables right into the engine. Separation of config and engine is what makes the database generic in the first place, each of them having a special purpose and power.
layline.io is similar in that Services are implemented as so-called Workflow Configurations not as monolithic executables. An unlimited number of different Workflows can be defined. Workflows are run by Reactive Engines which in turn run on Nodes. A Kubernetes Pod or a Raspberry Pi for example would be a Node. Two or more Engines form a logical Reactive Cluster. The setup solely depends on your requirements and environment. A theoretically indefinite number of Engines (on Nodes) can be spawned and run in a geographically distributed logical cluster. Edge-computing is one of the interesting use-cases here. Because everything runs on the same type of Reactive Engine you don't have to think about what to deploy on a physical level.
Deployment of Workflow Configurations happens automatically in that a configuration is published to a Node in the Reactive Cluster, and the Cluster then automatically propagates the configuration throughout the Cluster. This avoids having to worry about low-level physical deployment of Microservices to Pods or actual physical Nodes. New nodes being added to the Cluster also automatically receive the configuration data and can commence processing immediately.
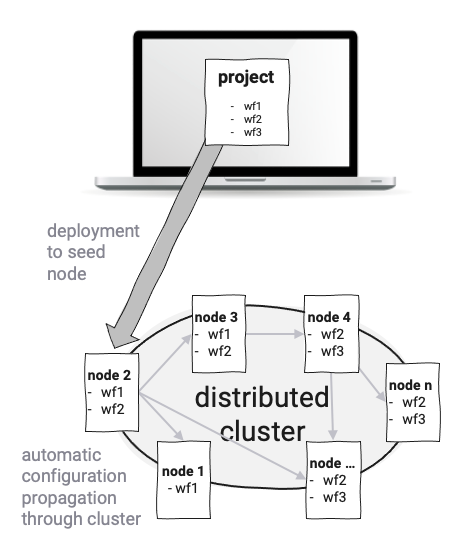
Resilience, Scalability and Failover is built-in to layline.io. Constant Cluster monitoring ensures compliance with configured scales of Workflows instances, and automatically rebalances the workload of Workflows in case of Node-failure.
Central monitoring and logging ensures that problems within the Reactive Cluster are immediately spotted. Remedy can be commonly provided through the UI without interference on physical level.
Everything within the layline.io platform is standardized on execution level, but open on configuration level. This allows you to set up what you need, without having to worry about the hard parts on how the infrastructure actually runs.
While the concept of a framework may not be what the hard-core "low-level-only" developer likes to embrace, it does make a lot of sense technically and business-wise. You wouldn't program your own database either, or would you?
Resources
- Top 10 Challenges of Using Microservices for Managing Distributed Systems
- Here's Why Microservices Desperately Need Service Mesh Anomaly Detection
- Read more about layline.io here.
- Contact us at hello@layline.io.


