
How does layline.io compare to Kafka?
This is a question which we hear from time to time. We wonder why. To better understand, let's look at what Kafka is:
What is Kafka?
This is how AWS describes it:
"Apache Kafka is a distributed data store optimized for ingesting and processing streaming data in real-time. Streaming data is data that is continuously generated by thousands of data sources, which typically send the data records in simultaneously. A streaming platform needs to handle this constant influx of data, and process the data sequentially and incrementally.
Kafka provides three main functions to its users:
- Publish and subscribe to streams of records.
- Effectively store streams of records in the order in which records were generated.
- Process streams of records in real time.
Kafka is primarily used to build real-time streaming data pipelines and applications that adapt to the data streams. It combines messaging, storage, and stream processing to allow storage and analysis of both historical and real-time data."
Our take on Kafka
There is a bit of technobabble in the above description which we need to address. It talks about streaming processing, real-time etc. What does this all mean in the context of Kafka?
- Kafka is a data storage solution first. It should be viewed as a special type of database in which data is stored in queues (topics). There are various ways on how these queues can be written to (publish) and then read from (subscribe). Queues follow the FIFO principle (first-in-first-out). There is an argument that Kafka is not a store but a streaming event processor, but this is misleading in our view. Kafka is designed to store data and then for Consumers to read that data quickly. It is designed to get rid of stored data after a pre-configured retention period regardless of whether the data was consumed, or not. In that sense it is a temporary data store with a few very special, albeit useful, features.
- Individual Processes can publish to queues (Producers) or subscribe to queues (Consumers). If none of the out-of-the-box connectors (see below) suffices as a producer/consumer for your purpose (likely), then you need to custom code one yourself (most use Java, but there are other options).
- Kafka can run in a cloud native, distributed environment, providing resilience and scalability.
Confluent (the company) has added some more features to Kafka such as pre-made "Connectors". Connectors are special types of Producers and Consumers which can read/write special types of data sources/sinks from/to Kafka topics. They are quite limited and specialized in what they can do.
In addition to this they created the capability to "filter, route, aggregate, and merge" data using "ksql". It suggests that you can filter and route information in real-time from Kafka topics. Sounds great. It is, however, just another type of Consumer which reads data from a Kafka topic, then filter, aggregate, merge and route results to another topic for some other Consumer to read. The best way to compare this logically, is to use the analogy of a table-driven database (e.g. Oracle) in which you copy data from one table to another, using SQL; except with Kafka it is a lot more complicated.
Kafka has some, but no meaningful capabilities to transform data. One of the big obstacles here is that Kafka has no inherent capability to parse data, and thus be able to work on it. It only supports very few limited data formats. Anything out of the ordinary (likely) requires custom coding Producers and Consumers to do the job. This again is like any other database which cares mostly about internals, not externals. Overall, it is fair to say, that Kafka does not actually process data. It merely stores data. Any other scenario implies chaining up atomic topics with Producers and Consumers.
Kafka is also known to be rather hard to operate. There is no comprehensive user interface. Pretty everything is configured in config files and operated from the command line.
Summary
The main use of Kafka is for:
- Fast data storage
- For large volumes
- Which are both produced and consumed quickly
We love Kafka for this purpose. It is great, and we frequently make use of it in implementations, even though there are several other solutions to achieve this as well.
What is layline.io?
layline.io is a fast, scalable, resilient event data processor. It can ingest, process and output data in real-time. Processing means "doing" something with the data, as opposed to what Kafka does (store). A major difference to Kafka for example is that in layline.io everything revolves around the notion of "Workflows". Workflows reflect data-driven logic which commonly resemble complex data orchestration.
This translates to:
- interpreting the data,
- analyzing it,
- deciding and potentially enriching it by consulting other sources in real-time
- create stats
- filter it,
- route it,
- integrating otherwise disparate data sources and sink.
and do all of this in:
- real-time,
- transactionally secure (option),
- without storage overhead,
- configurable,
- UI-driven
- and much more
Example Workflow:
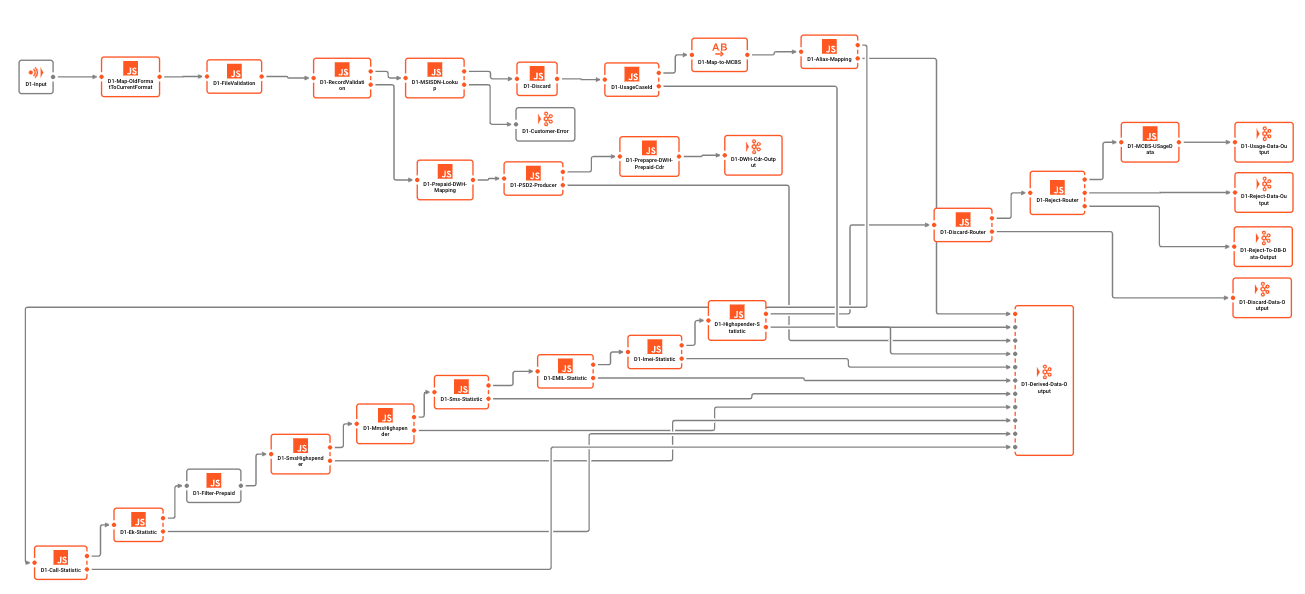
Kafka does not support Workflows by design. Anything which may be interpreted as a Workflow in Kafka is rather an attempt to "sell" a chaining of Kafka queues and Consumers / Producers as a Workflow. Note, however, that each of these are individual entities which are not aware of each other. There is no overarching (transaction) control, nor is there actual support for Workflows within Kafka.
Combining Kafka and layline.io
From the viewpoint of Kafka, this means that layline.io is seen as a Producer (write) or Consumer (read). From the viewpoint of layline.io, Kafka is seen as an event data store, comparable to other data stores like SQL DBs, NOSQL DBs, or even the file system. That's a great combination, depending on the use case. layline.io in this context acts as the data orchestration element between a theoretical unlimited number of Kafka topics, and other sources and sinks outside the Kafka sphere.
From that angle, Kafka and layline.io are extremely complementary, not competitive. The overlap is minimal. We do not see a meaningful scenario where a potential customer would decide between one or the other, but rather for one and the other.
How do Kafka users cope today?
Today's typical Kafka user uses Kafka as what it is: A special kind of event data store. To write and read data to/from it. He mostly custom codes consumers and producers. These custom coded parts then must contain points 1 through 6 from above (hint: they will not). They furthermore do not warrant resilience, scalability, reporting, monitoring and everything else which would have to be expected from such components. They are often built using simple scripting tools like Python up to using more sophisticated microservice frameworks like Spring Boot et al.
Instead of this, they could just be using layline.io and get all the above.
Real Deployment Example
This actual customer uses layline.io to take care of processing all customer usage data (communication meta data).
Before the implementation of layline.io, they were in a situation which very much resembled the scenario described in the previous paragraph. Several Kafka queues were fed by singular custom coded processes. Other such processes read from those queues and wrote data to other targets in other formats and with some logic applied. A messy and error-prone architecture, which was costly to maintain, and almost impossible to manage.
After the layline.io implementation, in which the previous business logic and processors was replaced, the architecture looked as follows:
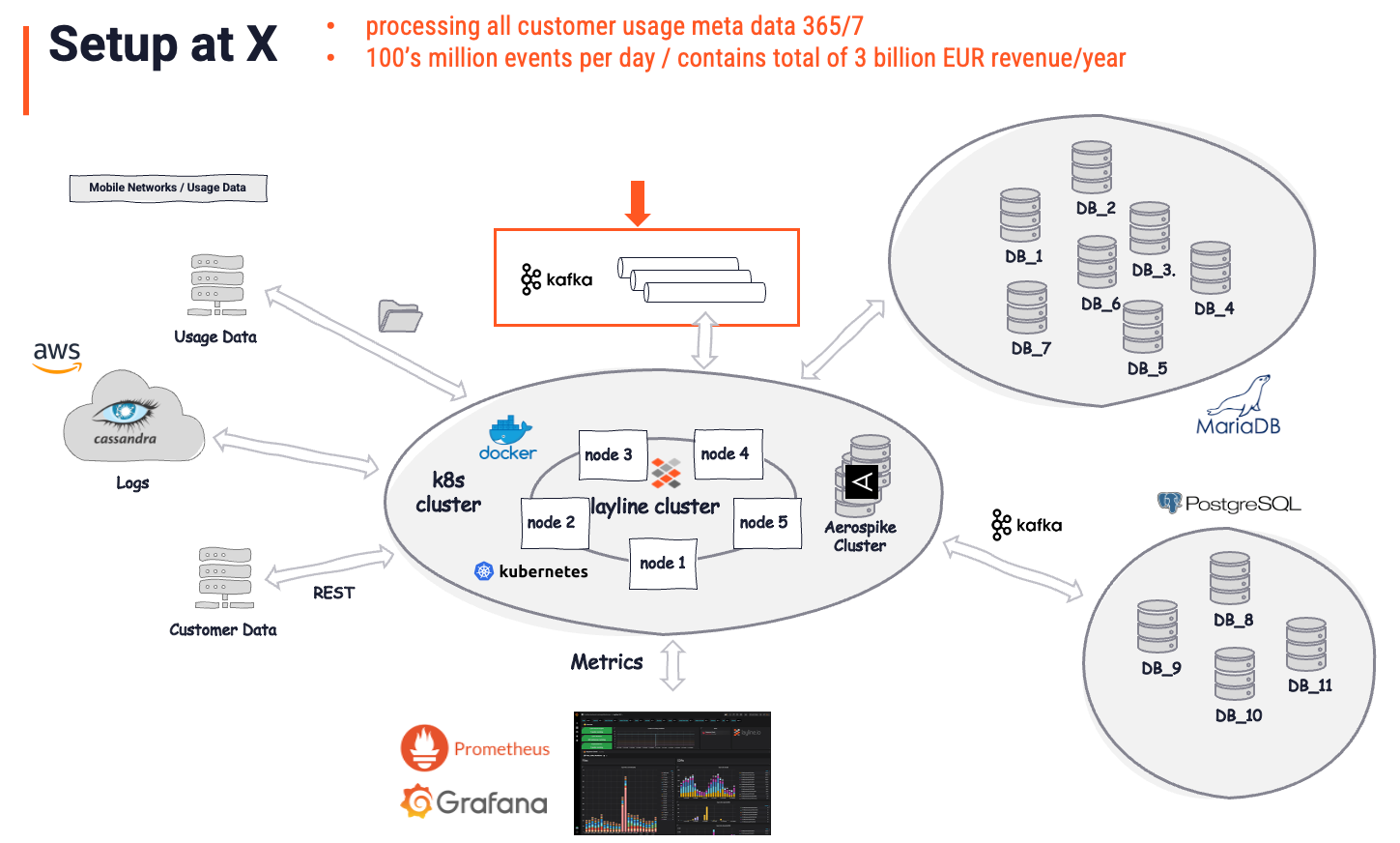
The overall picture is considered the "Solution". It is important to understand, that layline.io is recognized as the actual solution, whereas Kafka is just another (important) store. Kafka was there before layline.io. It plays a comparatively small role (red arrow and box) in the overall solution, however. It serves as an intermittent data store, which is exactly what it is by definition. All intelligent data analysis, enrichment, filtering, transformation, routing, complex business logic, and much more is handled by layline.io. A task at a level which would be impossible to accomplish using Kafka. Asking what part of this is owed to Kafka, the customer's answer would likely be: "5% of the overall solution".
Conclusion
Kafka is widely considered a message bus, but it is really about data-at-rest facilitating other applications to put data-in-motion. In this context actual application from the viewpoint of a user is something which is fed with data from Kafka using a client API. layline.io on the contrary forms an integral part of your application's logic, if it is not the application itself (see example). You can imagine layline.io like the circulatory system plus logic, whereas Kafka is just an external well-organized reservoir. The overlap between Kafka and layline.io is therefore minimal.
A customer who is running Kafka, will not question whether layline.io could make sense "in addition to Kafka". Likewise, we would not question the use of Kafka as a data store, only whether this would be the right data store for the purpose. Customers would rather question how they solve issues (which Kafka does not address) using layline.io. They may be doing something new, or replace existing processes (e.g. microservices) which were custom coded to some extent in the past.
Appendix: Quick Comparison layline.io <> Kafka
Not a full comparison, but it helps:
| Aspect | Kafka | layline.io |
|---|---|---|
| Type | Message Queue | Concurrency Platform |
| Workflow support | Not really. Just a store. | Inherent part of the solution |
| Data store | Yes | No |
| Data format support | No understanding of data formats out-of-the-box. Only in context with ksql some limited support for formats such as CSV, JSON, Avro, ProtoBuf. | Complete understanding of data content. Strongly typed. Support for extremely complex data formats, such as ASCII and binary, hierarchical structures, ASN.1 etc. |
| Business Logic | No support | Full support. This is a major difference between a store and a data processing solution. |
| Data enrichment | Not supported. No 3rd parties can be consulted for data enrichment. | Full support. |
| Real-time | Kafka is a store. This can only be as real-time as whatever reads the data from the store (buffer). | Full. As real-time as it gets. No intermittent storage. Data is processed and output instantly. |
| Custom metrics | No custom metrics specific to your use case | Any type of custom metric (e.g. "4711 customers have signed up for service y in last time interval") |
| Performance | High | High |
| Scalable | Yes | Yes |
| Resilient / HA | Yes | Yes |
| Persistent | Yes. That's the purpose of Kafka. | No. Not the purpose of layline.io, but works great with persistence layers, such as Kafka. |
| UI-driven configuration | No | Yes |
| Memory intensity | High | Low |
| Hardware footprint | High | Low |
| Open Source | Yes, for community edition. No for confluent solution (e.g. ksql) | Not yet. |
| Ready cloud offer | Yes, for confluent | Not yet. |
- Read more about layline.io here.
- Contact us at hello@layline.io.


