
Come si confronta layline.io con Kafka?
Questa è una domanda che sentiamo di tanto in tanto. Ci chiediamo perché. Per capire meglio, diamo un'occhiata a cosa sia Kafka:
Cos'è Kafka?
Ecco come AWS lo descrive:
"Apache Kafka è un archivio di dati distribuito ottimizzato per l'acquisizione e l'elaborazione di dati in streaming in tempo reale. I dati in streaming sono dati generati continuamente da migliaia di fonti di dati, che tipicamente inviano i record di dati simultaneamente. Una piattaforma di streaming deve gestire questo flusso costante di dati ed elaborare i dati in modo sequenziale e incrementale.
Kafka fornisce tre funzioni principali ai suoi utenti:
- Pubblicare e sottoscrivere flussi di record.
- Memorizzare efficacemente flussi di record nell'ordine in cui i record sono stati generati.
- Elaborare flussi di record in tempo reale.
Kafka è utilizzato principalmente per costruire pipeline di dati in streaming in tempo reale e applicazioni che si adattano ai flussi di dati. Combina messaggistica, archiviazione ed elaborazione di flussi per consentire l'archiviazione e l'analisi di dati sia storici che in tempo reale."
La nostra opinione su Kafka
C'è un po' di gergo tecnico nella descrizione sopra che dobbiamo affrontare. Si parla di elaborazione in streaming, tempo reale ecc. Cosa significa tutto questo nel contesto di Kafka?
- Kafka è innanzitutto una soluzione di archiviazione dati. Dovrebbe essere visto come un tipo speciale di database in cui i dati sono memorizzati in code (argomenti). Ci sono vari modi in cui queste code possono essere scritte (pubblicate) e poi lette (sottoscritte). Le code seguono il principio FIFO (first-in-first-out). C'è un argomento secondo cui Kafka non è un archivio ma un elaboratore di eventi in streaming, ma questo è fuorviante a nostro avviso. Kafka è progettato per memorizzare dati e poi per i Consumer per leggere rapidamente quei dati. È progettato per eliminare i dati memorizzati dopo un periodo di conservazione preconfigurato, indipendentemente dal fatto che i dati siano stati consumati o meno. In questo senso è un archivio dati temporaneo con alcune caratteristiche molto speciali, sebbene utili.
- I singoli processi possono pubblicare su code (Producer) o sottoscrivere code (Consumer). Se nessuno dei connettori predefiniti (vedi sotto) è sufficiente come producer/consumer per il tuo scopo (probabile), allora devi codificare uno personalizzato da solo (la maggior parte usa Java, ma ci sono altre opzioni).
- Kafka può funzionare in un ambiente distribuito nativo del cloud, fornendo resilienza e scalabilità.
Confluent (l'azienda) ha aggiunto alcune funzionalità a Kafka come i "Connettori" predefiniti. I connettori sono tipi speciali di Producer e Consumer che possono leggere/scrivere tipi speciali di fonti/sink di dati da/a argomenti Kafka. Sono piuttosto limitati e specializzati in ciò che possono fare.
In aggiunta a questo hanno creato la capacità di "filtrare, instradare, aggregare e unire" i dati usando "ksql". Suggerisce che puoi filtrare e instradare informazioni in tempo reale dagli argomenti Kafka. Sembra fantastico. Tuttavia, è solo un altro tipo di Consumer che legge dati da un argomento Kafka, poi filtra, aggrega, unisce e instrada i risultati a un altro argomento per un altro Consumer da leggere. Il modo migliore per confrontarlo logicamente è usare l'analogia di un database basato su tabelle (ad es. Oracle) in cui copi dati da una tabella a un'altra, usando SQL; tranne che con Kafka è molto più complicato.
Kafka ha alcune, ma nessuna capacità significativa di trasformare i dati. Uno dei grandi ostacoli qui è che Kafka non ha la capacità intrinseca di analizzare i dati e quindi essere in grado di lavorarci. Supporta solo pochissimi formati di dati limitati. Qualsiasi cosa fuori dall'ordinario (probabile) richiede la codifica personalizzata di Producer e Consumer per fare il lavoro. Questo è di nuovo come qualsiasi altro database che si preoccupa principalmente degli interni, non degli esterni. In generale, è giusto dire che Kafka non elabora effettivamente i dati. Si limita a memorizzare i dati. Qualsiasi altro scenario implica concatenare argomenti atomici con Producer e Consumer.
Kafka è anche noto per essere piuttosto difficile da operare. Non c'è un'interfaccia utente completa. Praticamente tutto è configurato nei file di configurazione e operato dalla riga di comando.
Sommario
L'uso principale di Kafka è per:
- Archiviazione rapida dei dati
- Per grandi volumi
- Che sono sia prodotti che consumati rapidamente
Amiamo Kafka per questo scopo. È fantastico e lo utilizziamo frequentemente nelle implementazioni, anche se ci sono diverse altre soluzioni per ottenere questo risultato.
Cos'è layline.io?
layline.io è un processore di dati evento veloce, scalabile e resiliente. Può acquisire, elaborare e produrre dati in tempo reale. Elaborare significa "fare" qualcosa con i dati, a differenza di ciò che fa Kafka (memorizzare). Una differenza fondamentale rispetto a Kafka, ad esempio, è che in layline.io tutto ruota attorno alla nozione di "Workflows". I Workflows riflettono la logica guidata dai dati che comunemente assomiglia a un'orchestrazione complessa dei dati.
Questo si traduce in:
- interpretare i dati,
- analizzarli,
- decidere e potenzialmente arricchirli consultando altre fonti in tempo reale
- creare statistiche
- filtrarli,
- instradarli,
- integrare fonti e sink di dati altrimenti disparati.
e fare tutto questo in:
- tempo reale,
- transazionalmente sicuro (opzione),
- senza sovraccarico di archiviazione,
- configurabile,
- guidato da interfaccia utente
- e molto altro
Esempio di Workflow:
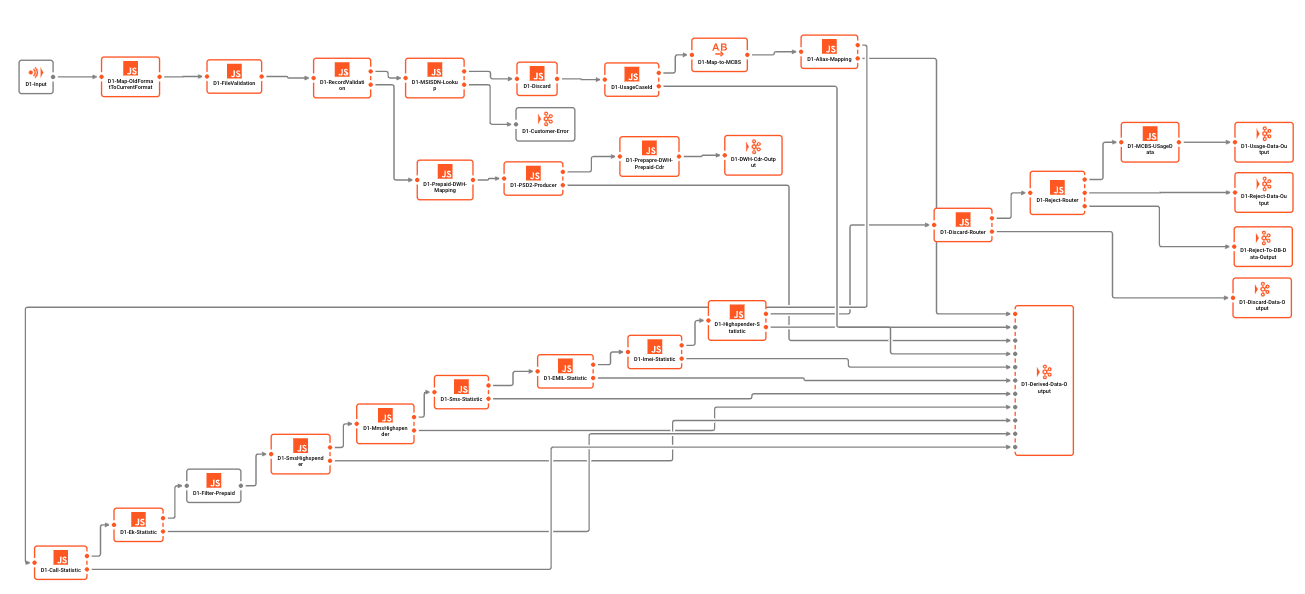
Kafka non supporta i Workflows per design. Qualsiasi cosa che possa essere interpretata come un Workflow in Kafka è piuttosto un tentativo di "vendere" una concatenazione di code Kafka e Consumer / Producer come un Workflow. Nota, tuttavia, che ciascuno di questi sono entità individuali che non sono consapevoli l'una dell'altra. Non c'è un controllo (transazionale) generale, né c'è un supporto effettivo per i Workflows all'interno di Kafka.
Combinare Kafka e layline.io
Dal punto di vista di Kafka, questo significa che layline.io è visto come un Producer (scrittura) o un Consumer (lettura). Dal punto di vista di layline.io, Kafka è visto come un archivio di dati evento, paragonabile ad altri archivi di dati come SQL DB, NoSQL DB, o anche il file system. È una grande combinazione, a seconda del caso d'uso. layline.io in questo contesto agisce come l'elemento di orchestrazione dei dati tra un numero teoricamente illimitato di argomenti Kafka e altre fonti e sink al di fuori della sfera di Kafka.
Da questo punto di vista, Kafka e layline.io sono estremamente complementari, non competitivi. La sovrapposizione è minima. Non vediamo uno scenario significativo in cui un potenziale cliente deciderebbe tra l'uno o l'altro, ma piuttosto per l'uno e l'altro.
Come fanno gli utenti di Kafka oggi?
L'utente tipico di Kafka oggi usa Kafka per quello che è: Un tipo speciale di archivio di dati evento. Per scrivere e leggere dati da/a esso. Codifica principalmente consumer e producer personalizzati. Queste parti codificate personalizzate devono quindi contenere i punti da 1 a 6 sopra (suggerimento: non lo faranno). Inoltre, non garantiscono resilienza, scalabilità, reporting, monitoraggio e tutto il resto che ci si aspetterebbe da tali componenti. Sono spesso costruiti utilizzando semplici strumenti di scripting come Python fino a utilizzare framework di microservizi più sofisticati come Spring Boot e altri.
Invece di questo, potrebbero semplicemente usare layline.io e ottenere tutto quanto sopra.
Esempio di Implementazione Reale
Questo cliente effettivo utilizza layline.io per gestire l'elaborazione di tutti i dati di utilizzo del cliente (meta dati di comunicazione).
Prima dell'implementazione di layline.io, si trovavano in una situazione che assomigliava molto allo scenario descritto nel paragrafo precedente. Diverse code Kafka erano alimentate da singoli processi codificati su misura. Altri processi simili leggevano da quelle code e scrivevano dati ad altri obiettivi in altri formati e con una certa logica applicata. Un'architettura disordinata e soggetta a errori, che era costosa da mantenere e quasi impossibile da gestire.
Dopo l'implementazione di layline.io, in cui la precedente logica di business e i processori sono stati sostituiti, l'architettura appariva come segue:
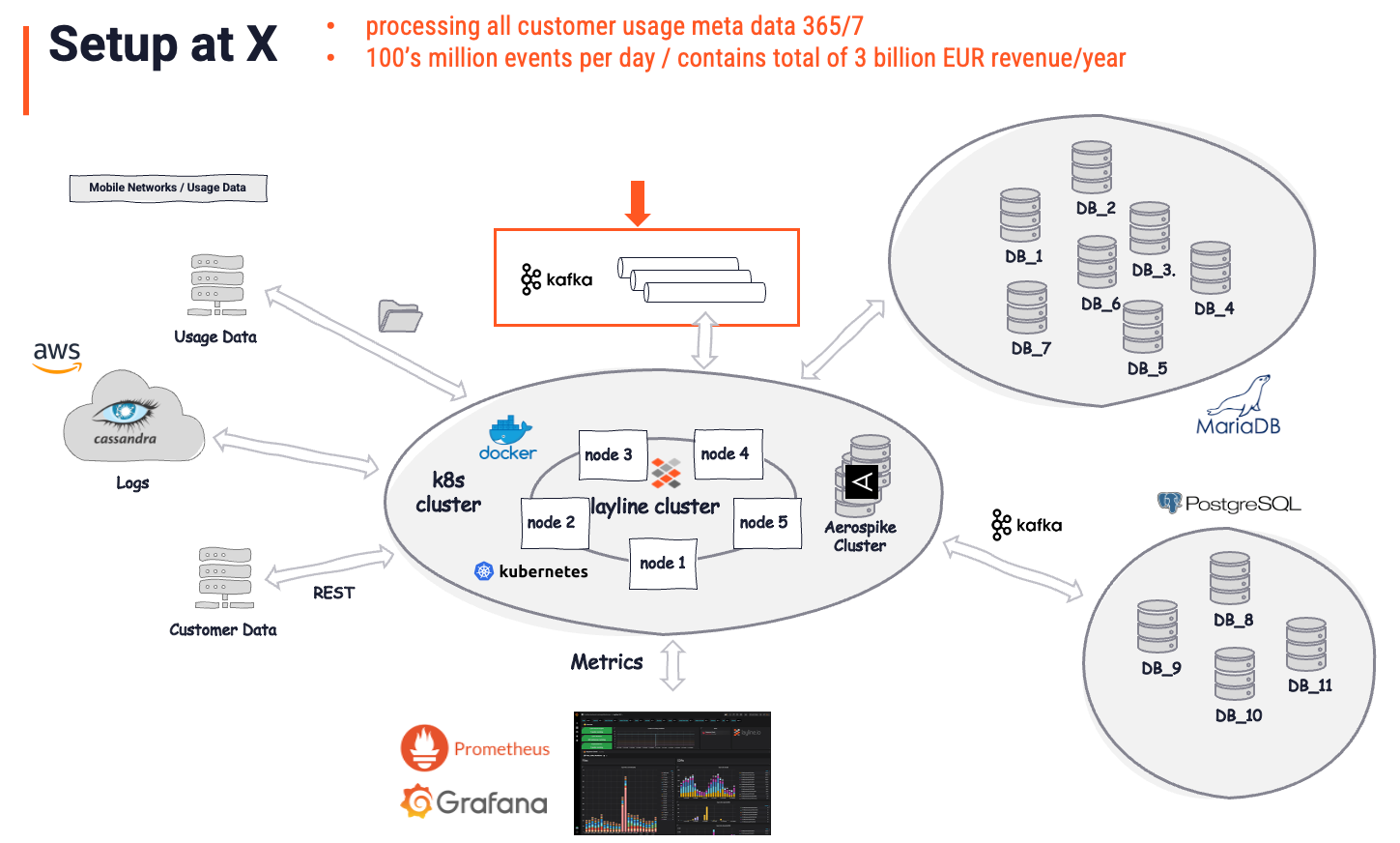
L'immagine complessiva è considerata la "Soluzione". È importante capire che layline.io è riconosciuto come la vera soluzione, mentre Kafka è solo un altro (importante) archivio. Kafka era presente prima di layline.io. Tuttavia, gioca un ruolo relativamente piccolo (freccia e riquadro rosso) nella soluzione complessiva. Serve come un archivio dati intermedio, che è esattamente ciò che è per definizione. Tutta l'analisi intelligente dei dati, l'arricchimento, il filtraggio, la trasformazione, l'instradamento, la logica di business complessa e molto altro è gestito da layline.io. Un compito a un livello che sarebbe impossibile da realizzare usando Kafka. Chiedendo quale parte di questo sia dovuta a Kafka, la risposta del cliente sarebbe probabilmente: "5% della soluzione complessiva".
Conclusione
Kafka è ampiamente considerato un bus di messaggi, ma riguarda davvero i dati a riposo che facilitano ad altre applicazioni di mettere i dati in movimento. In questo contesto, l'applicazione effettiva dal punto di vista di un utente è qualcosa che viene alimentato con dati da Kafka utilizzando un'API client. layline.io, al contrario, forma una parte integrante della logica della tua applicazione, se non è l'applicazione stessa (vedi esempio). Puoi immaginare layline.io come il sistema circolatorio più la logica, mentre Kafka è solo un serbatoio esterno ben organizzato. La sovrapposizione tra Kafka e layline.io è quindi minima.
Un cliente che utilizza Kafka non si chiederà se layline.io potrebbe avere senso "in aggiunta a Kafka". Allo stesso modo, non metteremmo in discussione l'uso di Kafka come archivio di dati, solo se questo sarebbe l'archivio di dati giusto per lo scopo. I clienti piuttosto si chiederanno come risolvere i problemi (che Kafka non affronta) utilizzando layline.io. Potrebbero fare qualcosa di nuovo o sostituire processi esistenti (ad esempio microservizi) che sono stati codificati su misura in una certa misura in passato.
Appendice: Confronto rapido layline.io <> Kafka
Non un confronto completo, ma aiuta:
| Aspetto | Kafka | layline.io |
|---|---|---|
| Tipo | Coda di Messaggi | Piattaforma di Concorrenza |
| Supporto Workflow | Non proprio. Solo un archivio. | Parte integrante della soluzione |
| Archivio dati | Sì | No |
| Supporto formati dati | Nessuna comprensione dei formati di dati di default. Solo nel contesto con ksql un supporto limitato per formati come CSV, JSON, Avro, ProtoBuf. | Comprensione completa del contenuto dei dati. Fortemente tipizzato. Supporto per formati di dati estremamente complessi, come ASCII e binari, strutture gerarchiche, ASN.1 ecc. |
| Logica di Business | Nessun supporto | Supporto completo. Questa è una differenza fondamentale tra un archivio e una soluzione di elaborazione dati. |
| Arricchimento dei dati | Non supportato. Nessun terzo può essere consultato per l'arricchimento dei dati. | Supporto completo. |
| Real-time | Kafka è un archivio. Questo può essere solo tanto in tempo reale quanto qualsiasi cosa legga i dati dall'archivio (buffer). | Completo. Il più in tempo reale possibile. Nessuna archiviazione intermedia. I dati sono elaborati e prodotti istantaneamente. |
| Metriche personalizzate | Nessuna metrica personalizzata specifica per il tuo caso d'uso | Qualsiasi tipo di metrica personalizzata (es. "4711 clienti si sono iscritti al servizio y nell'ultimo intervallo di tempo") |
| Prestazioni | Alte | Alte |
| Scalabile | Sì | Sì |
| Resiliente / HA | Sì | Sì |
| Persistente | Sì. Questo è lo scopo di Kafka. | No. Non è lo scopo di layline.io, ma funziona bene con i livelli di persistenza, come Kafka. |
| Configurazione guidata da UI | No | Sì |
| Intensità di memoria | Alta | Bassa |
| Impronta hardware | Alta | Bassa |
| Open Source | Sì, per la community edition. No per la soluzione confluent (es. ksql) | Non ancora. |
| Offerta cloud pronta | Sì, per confluent | Non ancora. |
- Leggi di più su layline.io qui.
- Contattaci a hello@layline.io.


