Dal caos dei dati
a insight in tempo reale
Crea pipeline dati reattive con un progettista visuale di flussi. Nessun codice infrastrutturale, nessuna dipendenza dal fornitore, solo elaborazione dati veloce e affidabile su larga scala.
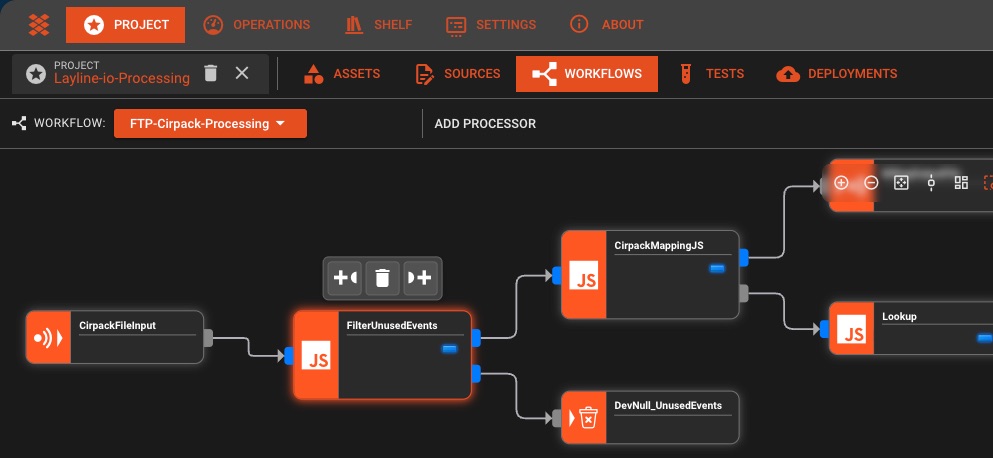
La realtà del data engineering
Costruire pipeline dati non dovrebbe richiedere un dottorato in sistemi distribuiti. Eppure la maggior parte dei data engineer passa l'80% del tempo a lottare con l'infrastruttura invece di risolvere problemi di business.
Complessità infrastrutturale
Gestione di cluster Kafka, distribuzione Kubernetes e monitoraggio personalizzato su piu ambienti. Il tuo team ha bisogno di un ingegnere DevOps solo per tenere tutto operativo.
Incubi di dipendenza dal fornitore
Servizi specifici del cloud che funzionano benissimo nelle demo ma ti intrappolano in ecosistemi proprietari. Migrare diventa un progetto a sei cifre.
Tempo per andare in produzione
Settimane o mesi per distribuire una semplice pipeline di trasformazione. Quando finalmente è live, i requisiti di business sono già cambiati due volte.
Debug di scatole nere
Quando le pipeline falliscono alle 3 del mattino, ti ritrovi dentro sistemi di aggregazione dei log distribuiti tra più servizi. Trovare la root cause sembra archeologia digitale.
Collo di bottiglia della scalabilità
Ciò che gestisce 1 M di eventi si comporta in modo molto diverso con 10 M di eventi. Riscrivi l'intera architettura della pipeline ogni volta che cresci.
Come i picchi di carico hanno causato il 24% degli incidenti su larga scala ->
Collaborazione del team
Gli analisti di business non capiscono le tue configurazioni Kafka. I data scientist non riescono a distribuire i loro modelli. Tutti lavorano in silos.
Ti suona familiare?
Sei diventato un ingegnere dei dati per portare intelligenza nei processi aziendali, non per fare l'ingegnere di affidabilità dei sistemi a tempo pieno. Esiste un modo migliore.
Scopri la soluzioneFlussi visuali.
Risultati reali.
Crea pipeline dati collegando blocchi invece di scrivere YAML. Osserva il flusso dei dati in tempo reale con monitoraggio e gestione degli errori integrati.
Progettista drag-and-drop
Creazione visuale di pipeline con processori configurabili. Nessun codice necessario, basta collegare i blocchi.
Monitoraggio in tempo reale
Metriche live, tracciamento errori e insight sulle prestazioni. Vedi esattamente cosa sta succedendo nella tua pipeline.
Zero gestione dell'infrastruttura
Funziona sulla tua infrastruttura o sulla nostra. Auto-scaling, alta disponibilità e operatività senza manutenzione.
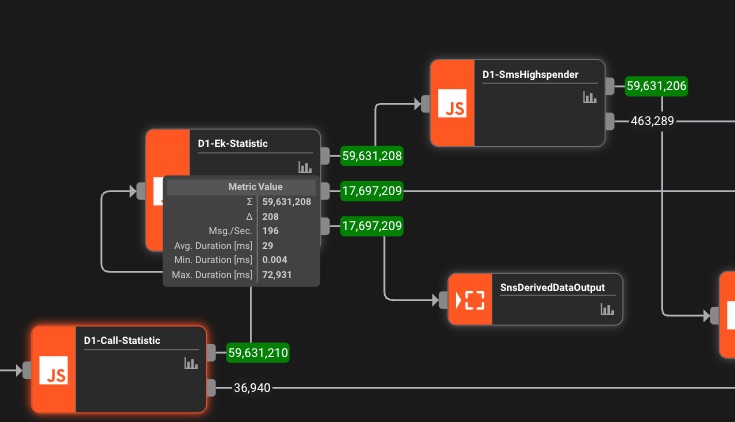
La rivoluzione del
data engineering
Smetti di combattere l'infrastruttura. Inizia a costruire soluzioni che contano davvero.
Distribuisci in pochi minuti
Evita mesi di setup infrastrutturale. Il nostro designer visuale ti permette di creare pipeline di produzione più velocemente di quanto richieda scrivere un consumer Kafka.
Dormi sonni tranquilli
Monitoraggio integrato, retry automatici e gestione dei dead letter. Le tue pipeline si autoriparano mentre tu ti concentri sulla logica di business.
Scala senza sforzo
Dal prototipo alla scala di produzione. Gestisci i picchi di traffico senza riscrivere codice né provisionare server.
Il punto chiave
Basta lottare con l'infrastruttura. Concentrati su ciò che fa davvero avanzare il tuo business.
"Finalmente, una piattaforma dati che funziona davvero."

Guarda layline.io
in azione
Soluzioni reali di veri team di data engineering in diversi settori
Dashboard analytics in tempo reale
Un'azienda e-commerce elabora oltre 50.000 eventi al secondo da clic web, acquisti e variazioni di inventario per alimentare dashboard live e motori di personalizzazione.

Domande dei ingegneri dei dati
Domande frequenti sull'implementazione dell'elaborazione dati in tempo reale con layline.io.
La maggior parte degli ingegneri dei dati fa elaborare a layline.io i primi flussi di dati entro 10 minuti. Il nostro costruttore visuale per pipeline e i connettori predefiniti eliminano settimane di sviluppo personalizzato.
layline.io si connette a database, API REST, code di messaggi, file system, piattaforme di flusso e protocolli personalizzati. Gestisce JSON, XML, ASCII, binario, ASN.1, HTTP e altro tramite configurazione visuale.
layline.io è progettato per la scala aziendale e gestisce milioni di eventi al secondo con scaling orizzontale. La nostra architettura distribuita garantisce prestazioni costanti anche durante i picchi di traffico, con gestione integrata della retropressione.
Sì. Distribuiscilo nei tuoi ambienti, in qualsiasi cloud o in modalità ibrida. layline.io funziona con database, laghi di dati, data warehouse e strumenti analitici esistenti senza richiedere cambiamenti architetturali.
Offriamo supporto tecnico, documentazione, tutorial video e guida all'inserimento. Il nostro team aiuta i team di ingegneria dei dati a ottimizzare le pipeline per prestazioni e affidabilità.
I prezzi di layline.io scalano in base all'utilizzo. Paghi solo per cio che elabori, con costi prevedibili che crescono insieme al tuo business. I piani aziendali includono supporto dedicato e SLA personalizzati.
Crea la tua prima pipeline in pochi minuti
Scarica layline.io gratuitamente e inizia a creare pipeline dati reattive senza la solita complessità. Nessuna carta di credito richiesta.
Risorse per i data engineer
Casi di studio, guide tecniche e best practice per creare pipeline dati

Il divario di produttività dell'IA: Perché i numeri non tornano
Ogni dashboard aziendale afferma che l'IA sta trasformando il business. I numeri reali sulla produttività raccontano una storia molto diversa — e capire il perché è importante per ogni team che prende decisioni sugli investimenti in IA.

L'Ingegnere dei Dati AI: Cosa è Veramente Cambiato (E Cosa No)
Ogni blog concorrente sta pubblicando 'L'AI sta cambiando l'ingegneria dei dati.' È tutto enfatico e vago. Ecco l'inventario onesto — cosa gli strumenti LLM aiutano veramente, cosa ancora non possono toccare, e perché le affermazioni di '80% automazione' non sopravvivono al contatto con la produzione.

I contratti dati sono il versioning delle API di cui il tuo Data Pipeline ha bisogno
La deriva dello schema continua a rompere i pipeline perché stiamo monitorando i cambiamenti invece di imporre contratti. Ecco perché i contratti dati sono il livello mancante tra i tuoi produttori e consumatori.