Da alcuni anni, le architetture a Microservizi e orientate ai servizi sono diventate estremamente popolari. Poco dopo, la containerizzazione ha aiutato ad astrarre la piattaforma installata dalla piattaforma distribuita, impacchettando il sistema operativo e le librerie dipendenti insieme all'applicazione vera e propria.
Ma dove c'è luce, c'è anche ombra. Lavorare e utilizzare i Microservizi comporta le sue sfide. Abbiamo trovato una lista piuttosto completa qui. Esaminiamo alcuni dei principali pro e contro:
Principali sfide nello sviluppo, distribuzione e operatività dei Microservizi
I Vantaggi
- Atomicità: I servizi autonomi possono essere trattati individualmente in termini di sviluppo ed esecuzione (a parte le interfacce).
- Resilienza: I singoli servizi di solito non sono compromessi in caso di guasti in altri servizi, il che porta a una maggiore resilienza.
- Scalabilità: I singoli servizi possono essere scalati elasticamente su richiesta.
Gli Svantaggi
- Loose coupling: I Microservizi di solito non sono a conoscenza l'uno dell'altro e del loro contesto di esecuzione più ampio. Sono di natura atomica. La comunicazione tra di essi comporta un sovraccarico e non è standardizzata.
- Monitoraggio: Il monitoraggio completo di una varietà di Microservizi è estremamente difficile e quasi impossibile da realizzare. Identificare chiaramente i problemi individuali tra diversi servizi può essere estremamente difficile a causa dei diversi tipi di log sparsi ovunque, delle interdipendenze poco chiare tra i servizi e della distribuzione delle transazioni tra i servizi, ecc.
- Debugging: Gli errori che si verificano in un'architettura complessa e distribuita di Microservizi possono essere estremamente dispendiosi in termini di tempo e costosi da tracciare. Non esiste un sistema di monitoraggio generale, ma piuttosto log individuali e tracce di stack che devono essere analizzati per determinare con certezza la causa dell'errore.
- Sicurezza: Una caratteristica intrinseca dei Microservizi sono le loro interfacce/API. Soprattutto in ambienti distribuiti, ciascuna di esse richiede particolare attenzione in termini di sicurezza. È facile perdere il controllo e la supervisione in ambienti così complessi.
- Resilienza: Con molti tipi diversi di Microservizi, che possono essere sviluppati da team diversi, diventa esponenzialmente più difficile garantire meccanismi di failover adeguati, in modo che l'intero sistema possa reagire correttamente quando uno o più Microservizi falliscono.
- Distribuzione: La distribuzione di singoli Microservizi in un setup complesso senza tempi di inattività è difficile da orchestrare e talvolta impossibile da realizzare senza riavviare tutto.
- Comunicazione: Deve esserci una qualche forma di standardizzazione della comunicazione tra i Microservizi in termini di serializzazione, sicurezza, opzioni di richiesta, gestione degli errori e elenco delle risposte previste. È necessaria una qualche forma di orchestrazione del design a livello superiore, altrimenti si rischia di incorrere in problemi di comunicazione fallita e di latenza.
Questi sono solo alcuni esempi delle sfide. Ce ne sono molte altre quando si tratta di manutenzione, rete, gestione dei team, ecc., come puoi immaginare.
Soluzione: MicroConfigurations invece di MicroServices
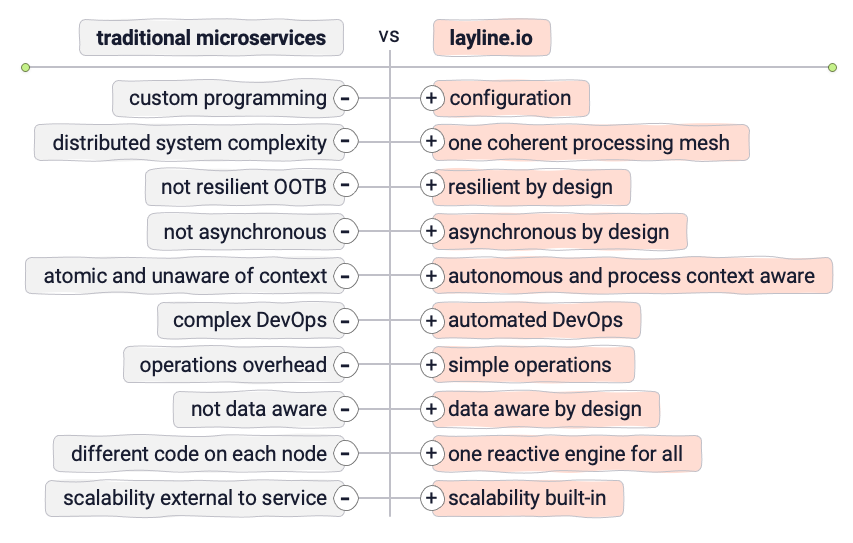
Sebbene l'idea dei Microservizi sia ottima, può diventare molto complessa molto rapidamente. Naturalmente, la domanda è se esiste un modo per mantenere gli aspetti positivi di un setup a Microservizi evitando quelli negativi.
Micro-Configurations potrebbe essere la risposta. Definiamo Micro-Configuration (o MicroConfig) come una separazione tra la logica effettiva del servizio (la Configurazione) e l'esecuzione del servizio (il Motore).
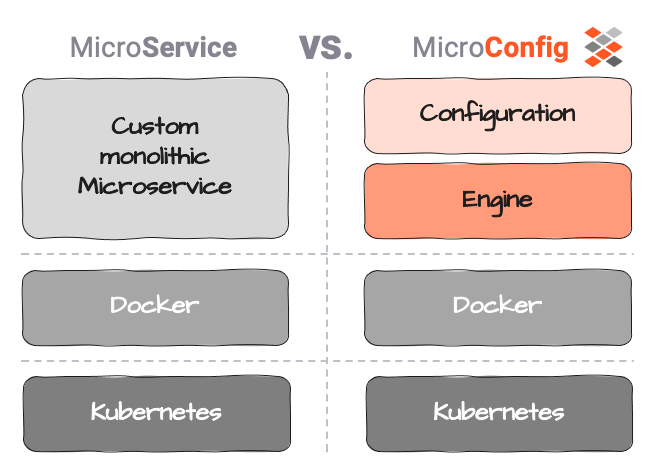
Configurazione in questo contesto deve essere limitata esclusivamente alla logica aziendale, cioè cosa fare con i dati, quale azione attivare, ecc.
Esecuzione è tutto ciò che rende possibile l'esecuzione della Configurazione:
- esecuzione della logica (configurazione),
- registrazione centralizzata e standardizzata delle attività e dei problemi,
- orchestrazione dell'esecuzione tra i servizi,
- reportistica delle metriche per il monitoraggio,
- supporto per il debugging,
- comunicazione standardizzata tra i confini dei servizi,
- e molto altro ancora.
Questo non è un concetto nuovo nel mondo della tecnologia.
Esempio: Un tipico database distingue tra la struttura del database (tabelle, indici, vincoli, ecc.) e il motore del database (interpretazione, archiviazione, servizio). Mentre il motore è lo stesso per ogni utente, la struttura è unica. Tuttavia, nessuno penserebbe di codificare direttamente le tabelle nel motore. La separazione tra configurazione e motore è ciò che rende il database generico in primo luogo, ognuno con uno scopo e un potere specifico.
layline.io è simile in quanto i Servizi sono implementati come cosiddette Workflow Configurations e non come eseguibili monolitici. È possibile definire un numero illimitato di Workflow diversi. I Workflow sono eseguiti da Reactive Engines, che a loro volta operano su Nodes. Un Kubernetes Pod o un Raspberry Pi, ad esempio, sarebbe un Node. Due o più Engines formano un Reactive Cluster logico. Il setup dipende esclusivamente dai tuoi requisiti e dall'ambiente. Un numero teoricamente indefinito di Engines (su Nodes) può essere avviato ed eseguito in un cluster logico distribuito geograficamente. L'Edge-computing è uno degli use-case interessanti in questo contesto. Poiché tutto funziona sullo stesso tipo di Reactive Engine, non devi preoccuparti di cosa distribuire a livello fisico.
La distribuzione delle Workflow Configurations avviene automaticamente: una configurazione viene pubblicata su un Node nel Reactive Cluster, e il Cluster propaga automaticamente la configurazione in tutto il Cluster. Questo evita di doversi preoccupare della distribuzione fisica a basso livello dei Microservizi su Pods o Nodes fisici reali. Anche i nuovi Nodes aggiunti al Cluster ricevono automaticamente i dati di configurazione e possono iniziare immediatamente l'elaborazione.
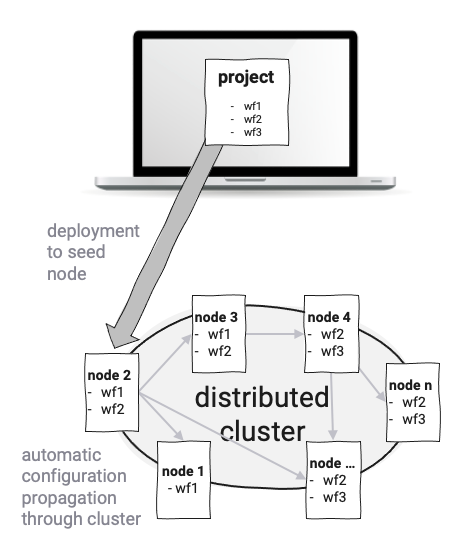
Resilienza, Scalabilità e Failover sono integrati in layline.io. Il monitoraggio costante del Cluster garantisce la conformità con le scale configurate delle istanze dei Workflow e riequilibra automaticamente il carico di lavoro dei Workflow in caso di guasto di un Node.
Il monitoraggio e la registrazione centralizzati garantiscono che i problemi all'interno del Reactive Cluster vengano individuati immediatamente. La soluzione può essere generalmente fornita tramite l'interfaccia utente senza interferire a livello fisico.
Tutto all'interno della piattaforma layline.io è standardizzato a livello di esecuzione, ma aperto a livello di configurazione. Questo ti consente di configurare ciò di cui hai bisogno, senza doverti preoccupare delle parti difficili su come l'infrastruttura funzioni effettivamente.
Sebbene il concetto di un framework possa non essere ciò che il "purista del low-level" ama abbracciare, ha molto senso sia dal punto di vista tecnico che aziendale. Non programmeresti nemmeno il tuo database, o sì?
Risorse
- Top 10 Challenges of Using Microservices for Managing Distributed Systems
- Here's Why Microservices Desperately Need Service Mesh Anomaly Detection
- Leggi di più su layline.io qui.
- Contattaci a hello@layline.io.


