Alle Funktionen, die Sie brauchen. Nichts, was Sie nicht brauchen.
Von visuellen Arbeitsabläufen über exotische Datenformate bis hin zur Bereitstellung auf Carrier-Niveau – layline.io gibt Ingenieurteams die Werkzeuge an die Hand, um Echtzeit-Datenpipelines ohne unnötigen Aufwand zu erstellen.
Gebaut für Reale Pipelines
Alles, was Sie zum Erstellen, Bereitstellen und Überwachen von Datenpipelines in Produktionsqualität benötigen
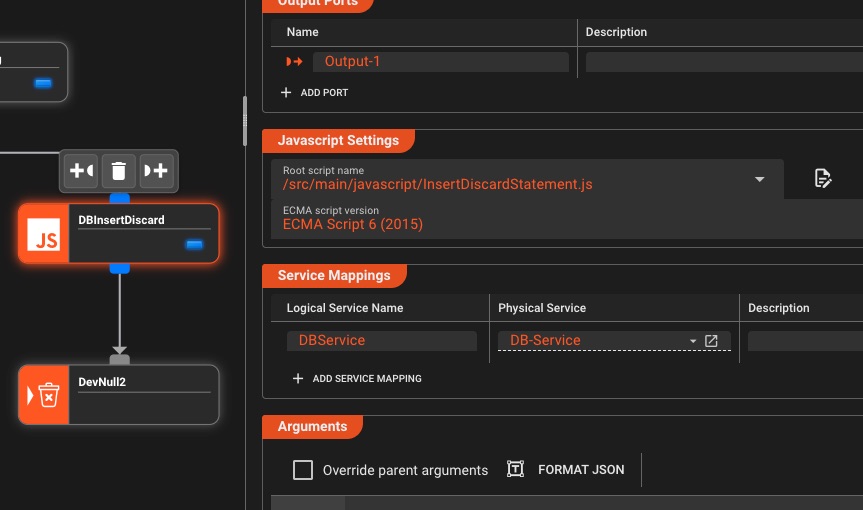
Visuelle Workflow-Entwicklung
Erstellen Sie komplexe Pipelines ganz einfach per Drag-and-Drop
Intuitive Drag-and-Drop-Leinwand
Erstellen Sie Workflows visuell durch die Verbindung von Prozessoren – beschleunigen Sie die Entwicklung mit Zero-Code-Konfiguration und nutzen Sie bei Bedarf benutzerdefinierte Skripts
Echtzeitvalidierung
Erkennen Sie Konfigurationsfehler während der Erstellung – vor der Bereitstellung
- Sofortige Syntaxprüfung
- Schemavalidierung
- Abhängigkeitserkennung
- Fehlerhervorhebung
Bereit für die Versionskontrolle
Als JSON gespeicherte Konfigurationen und Skripte – verfolgen Sie Änderungen, verzweigen Sie und führen Sie sie mit jedem Versionskontrollsystem zusammen
Wiederverwendbare Assets
Erstellen Sie modulare, wiederverwendbare Komponenten, die als Prozessoren verwendet oder von anderen Prozessoren referenziert werden können – einmal erstellen, überall verwenden
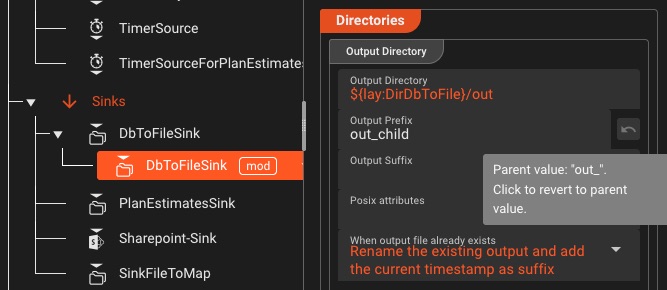
- Asset-Vererbung für einfache Wartung
- Leiten Sie Assets voneinander ab
- Wird über Workflows und Projekte hinweg geteilt
Benutzerdefinierte Vorlagen
Erstellen Sie Ihre eigenen Workflow-Vorlagen und teilen Sie sie projekt- und teamübergreifend
- Speichern Sie Workflows als wiederverwendbare Vorlagen
- Teilen Sie projekt- und teamübergreifend
- Exportieren Sie ganze Projekte oder Teile zur Wiederverwendung
Einmal erstellen, überall bereitstellen – umgebungs- und teamübergreifend
Browser-Attached-Debugging
Hängen Sie Ihren Browser-Debugger an den Code Python oder JavaScript an und nutzen Sie die volle Leistungsfähigkeit moderner Entwicklungstools
- Schrittweise Ausführung und bedingte Haltepunkte
- Beobachten Sie Ausdrücke, Bereiche und Aufrufstapel
- Nachrichtenprüfung in jeder Phase mit Live-Variablen
- Fehler-Stack-Traces mit Quellzuordnung
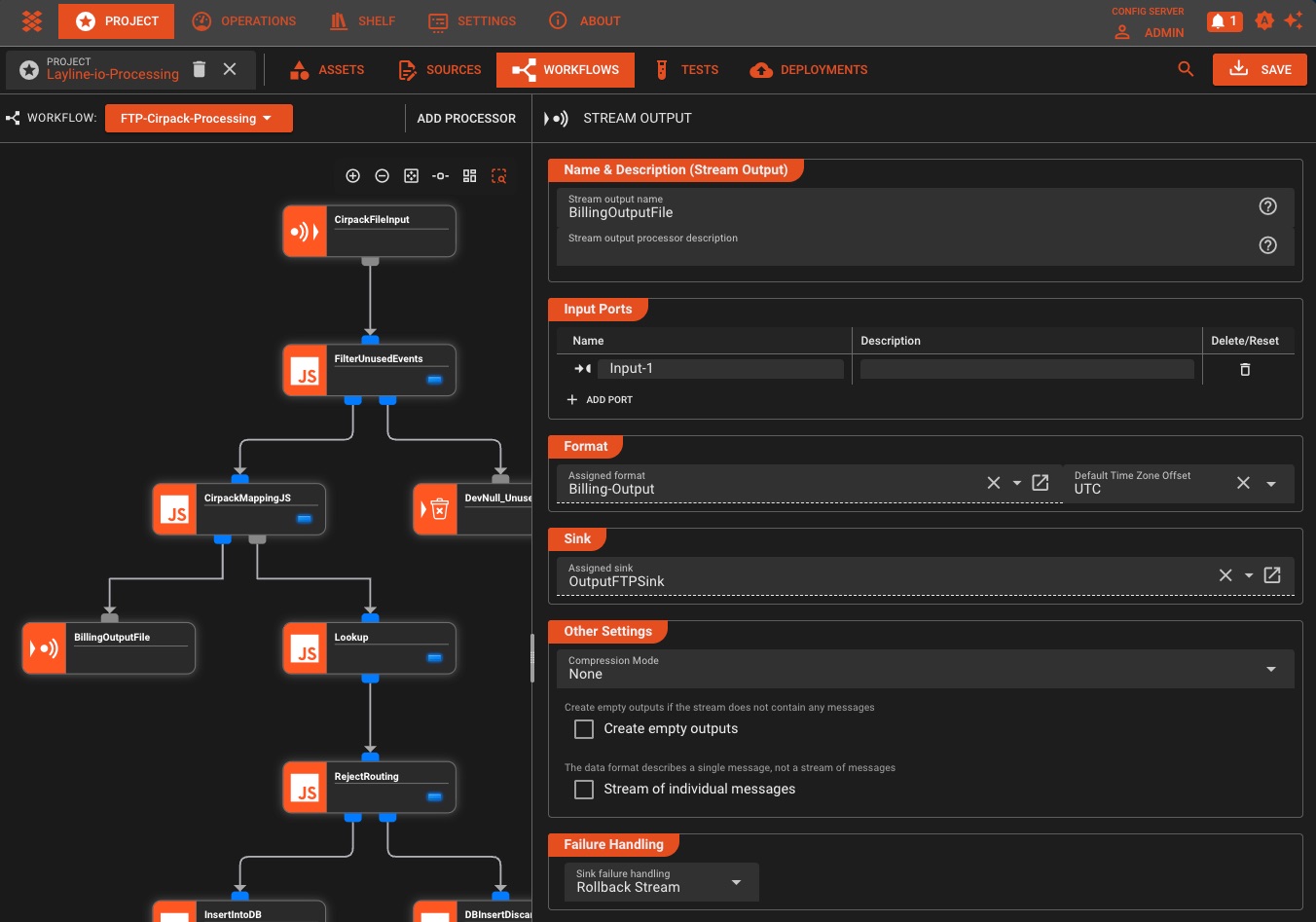
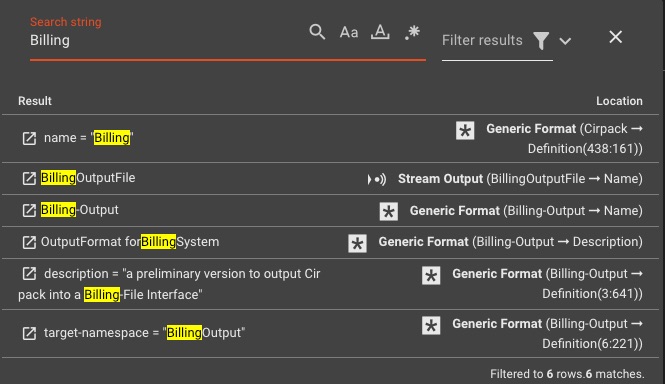
Workflow-Suche und -Navigation
Suchen und navigieren Sie schnell durch Prozessoren, Konfigurationen, Workflow-Elemente und Skripte
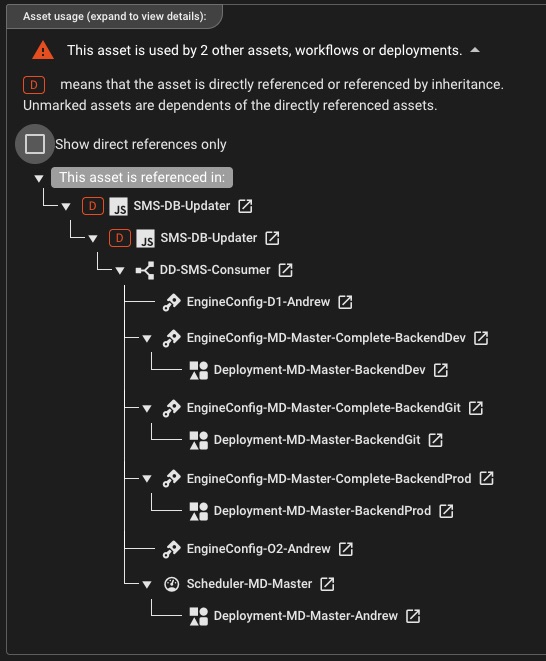
Visualisierung der Asset-Abhängigkeit
Verstehen Sie, wie Assets, Arbeitsabläufe und Bereitstellungen im gesamten Projekt miteinander verbunden sind
Teamzusammenarbeit
Teilen Sie Arbeitsabläufe und arbeiten Sie mit rollenbasierter Zugriffskontrolle zusammen
- Granulare Zugangskontrolle
- Gleichzeitige Projektbearbeitung
- Benachrichtigungen über Projektänderungen
Universelle Datenkonnektivität
Universelle Protokollunterstützung für jede Datenquelle und jedes Datenziel
Streaming-Plattformen
Kafka, AWS SQS & SNS, UDP, Azure Event Hubs und mehr – alle mit nativer Unterstützung
- • Verbrauchergruppen
- • Genau-einmal-Semantik
- • Stapelverarbeitung
- • Kinesis-Datenströme
- • SQS & SNS Nachrichten
- • S3 Ereignisbenachrichtigungen
Datenbankkonnektoren
Lesen und schreiben Sie in jede Datenbank mit Unterstützung für die Erfassung von Änderungsdaten
- PostgreSQL, MySQL, SQL Server
- MongoDB, Cassandra, Redis
- Elasticsearch, DynamoDB
- AWS Keyspaces
- Hazelcast
- GCS
- Sharepoint
- mehr...
REST APIs & Webhooks
Rufen Sie jeden HTTP-Endpunkt mit integrierter Wiederholung, Leitungsunterbrechung und Authentifizierung auf
- Tasten OAuth 2.0, API, JWT
- GraphQL Abfragen
Cloud-native Dienste
Tiefe Integration mit AWS, Azure und Google Cloud
- S3, Azure Blob, GCS
- SNS/SQS, Service Bus
- CloudWatch & App Insights
- IAM & verwaltete Identitäten
Enterprise Dateifreigabe
Greifen Sie auf Unternehmensdateifreigaben und Cloud-Dokument-Repositories zu
- SMB/CIFS Netzwerkfreigaben
- NFS (Netzwerkdateisystem)
- WebDAV Protokollunterstützung
- Abstraktion eines virtuellen Dateisystems
Microsoft 365 Integration
Tiefe Integration mit SharePoint, OneDrive und Microsoft Graph API für die Zusammenarbeit im Unternehmen
Netzwerkprotokolle
Low-Level-Netzwerkzugriff für benutzerdefinierte Protokolle und Echtzeit-Datenstreaming
- TCP/UDP Quell- und Senkenunterstützung
- Raw-Socket-Handhabung
- Benutzerdefinierte Protokollimplementierung
- Binäres Daten-Streaming
E-Mail-Integration
Lösen Sie Workflows aus E-Mails aus und senden Sie Benachrichtigungen mit Anhängen
- IMAP/POP3 E-Mail-Quellen
- SMTP E-Mail-Zustellung
- Anhangverarbeitung
- Überwachung mehrerer Postfächer
Timer und geplante Quellen
Lösen Sie Workflows nach Zeitplänen, Zeitfenstern oder wiederkehrenden Intervallen für Stapelverarbeitung und periodische Aufgaben aus
Komplexe Planungsmuster mit vollständiger Cron-Unterstützung
Einfache intervallbasierte Triggerung von Sekunden bis Monaten
Definieren Sie bestimmte Zeitfenster für die Stapelverarbeitung
Dateisysteme und Legacy-Protokolle
Verarbeiten Sie Dateien von lokalen Laufwerken, Netzwerkfreigaben, FTP/SFTP-Servern oder Cloud-Speichern – mit automatischer Abfrage, Mustervergleich und Verschiebung nach der Verarbeitung
Datenformate und Parsing
Analysieren Sie jedes Format von JSON bis hin zu älteren Telekommunikationsprotokollen
Standardformate
Native Unterstützung für die Datenformate, die Sie bereits verwenden
- ASN.1
- XML
- CSV, TSV, durch Trennzeichen getrennte Dateien
- Alle strukturierten ASCII, binären oder gemischten Formate
- Datensätze mit fester Breite
Universelle Formatkonfiguration
Definieren Sie jedes benutzerdefinierte Datenformat – CSV, hierarchisches ASCII, binäre oder gemischte Strukturen – mit einer leistungsstarken grammatikbasierten Konfigurationssprache
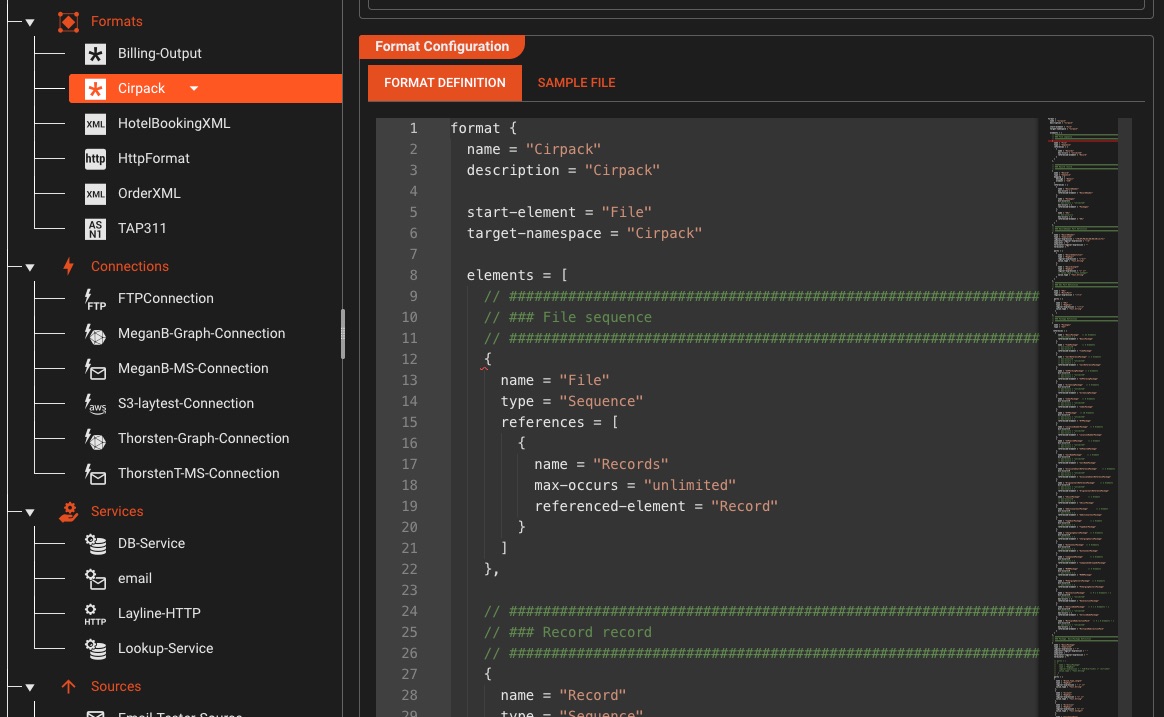
Definieren Sie Formate mithilfe regulärer Ausdrücke und hierarchischer Strukturen
Laden Sie Beispieldateien hoch und testen Sie Ihre Grammatik in Echtzeit
Verwenden Sie dieselbe Grammatik sowohl für das Parsen der Eingabe als auch für das Generieren der Ausgabe
Echtzeit-Syntaxvalidierung und Fehlerhervorhebung im Editor
ASN.1 & Telekommunikationsprotokolle
Einzigartige FähigkeitBranchenführendes ASN.1-Parsing für Telekommunikation CDRs, SS7, TCAP, MAP und ältere Protokolle – Funktionen, die Sie in generischen ETL-Tools nicht finden
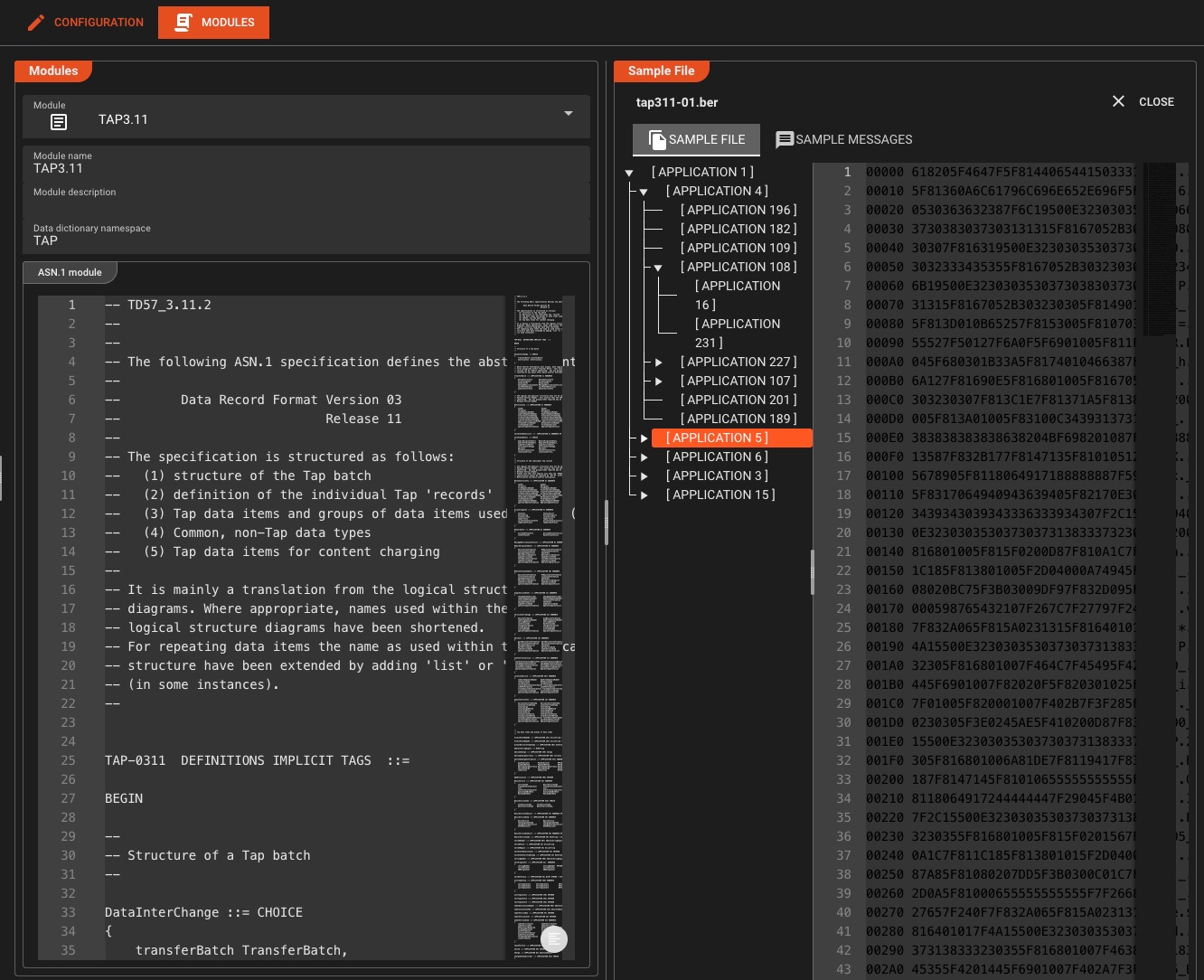
Unterstützte Standards
Anwendungsfall: Verarbeiten Sie täglich Milliarden von Telekommunikationsdaten CDRs mit Parsing in weniger als einer Millisekunde
Data Dictionary
TypensystemDefinieren Sie benutzerdefinierte Datenstrukturen und -typen, die in Ihren Arbeitsabläufen wiederverwendet werden können – mit vollständiger Unterstützung für die Kodierung/Dekodierung in externe Formate wie JSON
Benutzerdefinierte Typen
Definieren Sie Sequenzen, Arrays, Aufzählungen, Auswahlmöglichkeiten und Namespaces
Typ Wiederverwendbarkeit
Referenzieren Sie Typen über Formate und Workflows hinweg, um Konsistenz zu gewährleisten
Nachrichtenerweiterung
Fügen Sie abgeleitete oder angereicherte Daten zur Laufzeit zu Nachrichten hinzu
Formatintegration
Referenztypen aus jedem Format – generisch, ASN.1 oder andere Data Dictionaries
Formattransformation
Wenden Sie Transformationen an, um zwischen beliebigen Formaten zu konvertieren
- Feldkartierung und Umstrukturierung
- Datentypkonvertierungen
Benutzerdefinierte Binärformate
Definieren Sie Ihre eigenen binären Strukturparser mit Präzision
- Feldextraktion auf Bitebene
- Verschachtelte Strukturen
- Bedingtes Parsen
Validierung und Qualität
Erkennen Sie fehlerhafte Daten, bevor sie Ihre Pipeline beschädigen
- Schemavalidierung
- Benutzerdefinierte Validierungsregeln
- Fehleranreicherung
Verarbeitung nativer Formate
Game ChangerIm Gegensatz zu herkömmlichen ETL-Tools, die Sie dazu zwingen, externe Formate festen internen Schemata und umgekehrt zuzuordnen, arbeitet layline.io direkt mit Ihren Daten in ihrem nativen Format und eliminiert so unnötigen Transformationsaufwand
Traditionelle ETL Systeme
- •Ordnen Sie beim Lesen das externe Format dem festen internen Schema zu
- •Prozessdaten in generischer interner Darstellung
- •Ordnen Sie das interne Schema beim Schreiben wieder dem Zielformat zu
- •Doppelter Transformationsaufwand und doppelte Komplexität
Ansatz von layline.io
- Analysieren Sie Daten direkt in die native Formatstruktur
- Arbeiten Sie durchgehend mit Daten in ihrer ursprünglichen Struktur
- Data Dictionary, das dynamisch aus Ihren Formaten erstellt wird
- Erweitern Sie es nach Bedarf mit benutzerdefinierten Strukturen – ohne Zuordnung
Warum das wichtig ist
Geschäftslogik und Transformation
Integrieren Sie benutzerdefinierte Logik für Anreicherung, Routing und komplexe Transformationen
Fehlerbehandlung und erneuter Versuch
Behandeln Sie Fehler elegant mit konfigurierbaren Wiederholungsrichtlinien und Warteschlangen für unzustellbare Nachrichten
- Konfigurierbare Wiederholungsrichtlinien
- Exponentielle Backoff-Strategien
- Routing der Warteschlange für unzustellbare Nachrichten
- Leistungsschaltermuster
- Fehlerkategorisierung
JavaScript & Python Skripterstellung
Betten Sie benutzerdefinierten Code direkt in Ihre Arbeitsabläufe ein – vollständige Sprachunterstützung, keine eingeschränkte Sandbox
💡 Sie können Ihre Lieblings-IDE auch für Skripting-Zwecke verwenden
- Async/await-Unterstützung
- Import/Export
- Lebenszyklus-Hooks
- Verwenden Sie Javascript/Python austauschbar
Feldkartierung
Transformieren und ordnen Sie Datenfelder zwischen verschiedenen Formaten und Schemata zu
- Visueller Feldkartograph
- Zugriff auf verschachtelte Felder
- Bedingte Zuordnungen
- Geben Sie Zwang ein
- Standardwertbehandlung
Datenanreicherung
Erweitern Sie Ereignisse mit externen Daten aus APIs, Datenbanken oder Caches
- Greifen Sie überall in der Pipeline auf Servicequellen zu
Routing und Filterung
Definieren Sie Ihre eigenen Regeln mit individuellen Bedingungen – ein sehr flexibler Prozessor, der für die meisten, wenn nicht alle Routing- und Filterungsfälle geeignet ist. Wenn dies nicht ausreicht, können Sie jederzeit auf Skripting zurückgreifen.
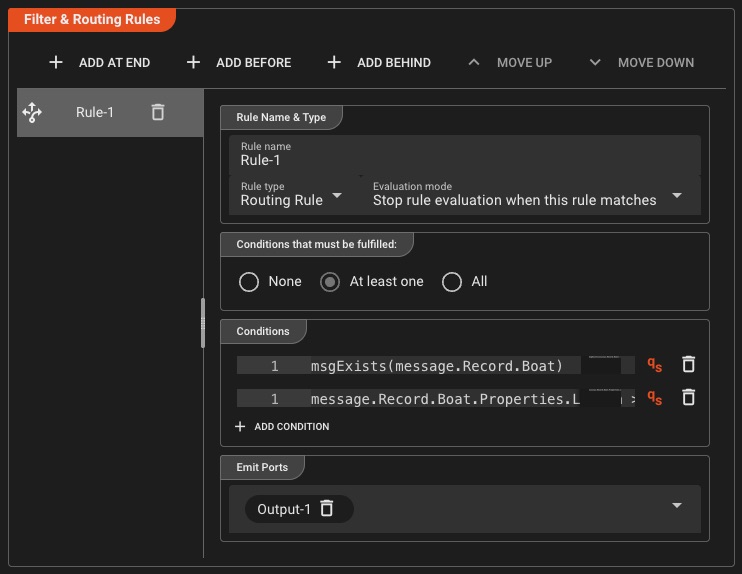
Regelbasiertes Routing
- Definieren Sie mehrere Bedingungen pro Regel
- Mehrwege-Routing zu verschiedenen Ports
- UND/ODER-Bedingungskombinationen
Flexible Filterung
- Inhaltsbasierte Filterregeln
- Feldwertvergleiche
- Bei Bedarf auf Skripterstellung zurückgreifen
Ratenbegrenzung und -drosselung
Steuern Sie den Nachrichtenfluss und verhindern Sie eine Systemüberlastung durch intelligente Drosselung
- Kontrolle der Nachrichtenrate
- Umgang mit Backpressure
- Burst-Management
- Dynamische Drosselung
Zustandsbehaftete Verarbeitung
Behalten Sie den Status ereignisübergreifend bei komplexen Arbeitsabläufen bei
- In-Memory-Statusspeicher
- Persistente Status-Backends
- Genau-einmal-Garantie
- Checkpointing und Wiederherstellung
- Transaktionssicherheit
Verfolgen Sie Benutzersitzungen, zählen Sie Ereignisse oder verwalten Sie laufende Gesamtzahlen über Millionen von Streams hinweg
Aggregations- und Zeitfenster
Verarbeiten Sie Streams mit Taumel-, Gleit- oder Sitzungsfenstern für Echtzeitanalysen
Taumelnde Fenster
Zeitfenster mit fester Größe, die sich nicht überschneiden
Alle 5 MinutenSchiebefenster
Überlappende Fenster für gleitende Durchschnitte
10-minütiges Fenster, 1-minütige FolieSitzungsfenster
Aktivitätsbasierte Gruppierung mit Timeout
30 Sekunden InaktivitätslückeUnbegrenzte Flexibilität
Mit JavaScript oder Python können Sie jede Art von Verarbeitungslogik basierend auf den Nachrichten definieren, die durch Ihre Prozessoren fließen. Verketten Sie einen oder mehrere Prozessoren, um komplette Systeme zu implementieren – Betrugserkennung, Preisberechnung, Filterung, Transformation oder alles andere, was Ihnen in den Sinn kommt. Reichern Sie Daten aus externen Quellen an, verzweigen Sie sie und leiten Sie sie basierend auf Ihrer Geschäftslogik zu bestimmten Zielen weiter. Sie können sogar Ihre eigene IDE verwenden, anstatt sich beim Schreiben Ihrer Skripte auf Configuration Center zu verlassen.
Betrugserkennung
Analysieren Sie Transaktionsmuster in Echtzeit, um betrügerische Aktivitäten zu erkennen und zu blockieren
Dynamische Preisgestaltung
Berechnen Sie Preise spontan basierend auf Nachfrage, Lagerbestand und Marktbedingungen
Datentransformation
Filtern, umformen und bereichern Sie Daten aus mehreren Quellen in einheitlichen Formaten
Echtzeitanalysen
Aggregieren und berechnen Sie Metriken aus Streaming-Daten für sofortige Erkenntnisse
Intelligente Warnung
Erkennen Sie Anomalien und lösen Sie Benachrichtigungen basierend auf benutzerdefinierten Geschäftsregeln aus
Event-Orchestrierung
Koordinieren Sie komplexe mehrstufige Arbeitsabläufe über verteilte Systeme hinweg
Dies sind nur Beispiele. Das System ist nicht auf diese Anwendungsfälle beschränkt – implementieren Sie alles, was Ihr Unternehmen benötigt, mit vollständiger Programmiersprachenunterstützung und Lebenszyklus-Hooks für Streams, Transaktionen und Nachrichten.
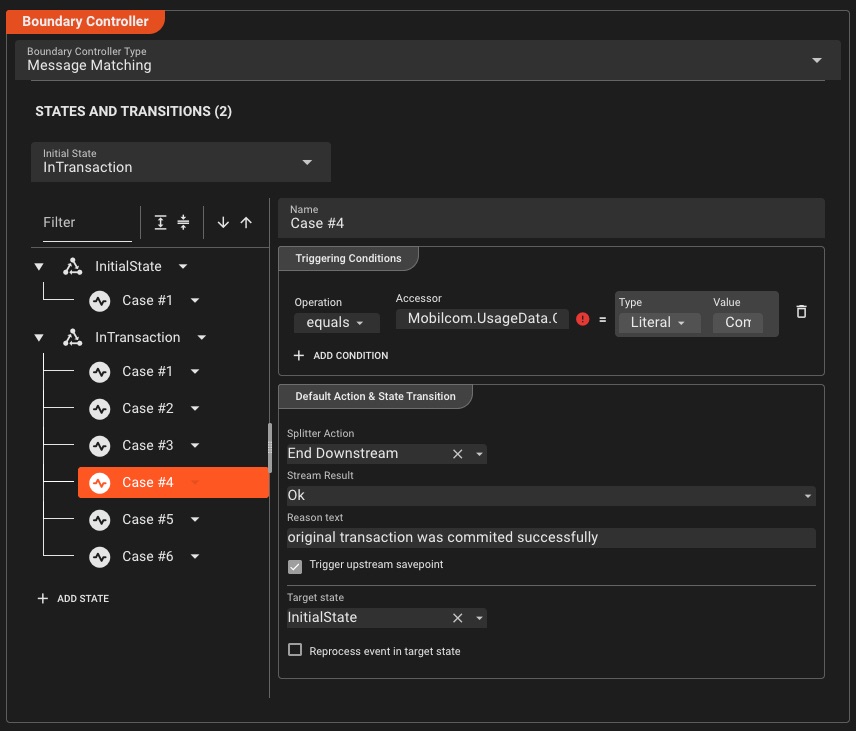
Bereitstellung und Orchestrierung
Stellen Sie es überall bereit – in der Cloud, am Edge oder vor Ort – mit Aktualisierungen ohne Ausfallzeiten
Cluster-Bereitstellung mit einem Klick
Stellen Sie mit einem einzigen Klick auf jedem Cluster bereit – keine Befehlszeile, keine komplexen Konfigurationen, nur intuitives visuelles Bereitstellungsmanagement
Vereinfachte Bereitstellung
- Bereitstellung mit einem Klick für jeden Cluster
- Automatische Verbreitung von Konfigurationen im gesamten Cluster
- Keine Befehlszeile oder komplexe Konfigurationen erforderlich
- Visuelle Bereitstellungsanleitung
- Weisen Sie Bereitstellungen bestimmten Clusterknoten zu
Versionsverwaltung
- Vollständiger Bereitstellungsverlauf im Cluster gespeichert
- Nahtloser Wechsel ohne Ausfallzeiten zwischen Versionen
- Sofortiges Rollback zu jeder vorherigen Bereitstellung
- Inkrementelle Aktualisierungen vorhandener Bereitstellungen
Docker Container
Verpacken Sie Workflows als leichtgewichtige Container
- Docker Compose-Unterstützung
- Multi-Arch-Images (x86/ARM)
- Minimale Basisbilder
Multiregionales Netz
Geoverteilte Cluster mit automatischem Failover
- Regionsübergreifende Replikation
- Automatisches Failover
- Lastausgleich
- Datenlokalität
Enterprise: Bereitstellung auf allen Kontinenten mit einer Synchronisierungslatenz von <10ms
CI/CD Pipeline-Integration
Bereitstellung über die CLI mit skriptfähiger Automatisierung für eine nahtlose CI/CD-Integration
- Ein-Befehl-Bereitstellungen mit Flags
- Shell-skriptfähig für die Automatisierung
- Exit-Codes für die Pipeline-Integration
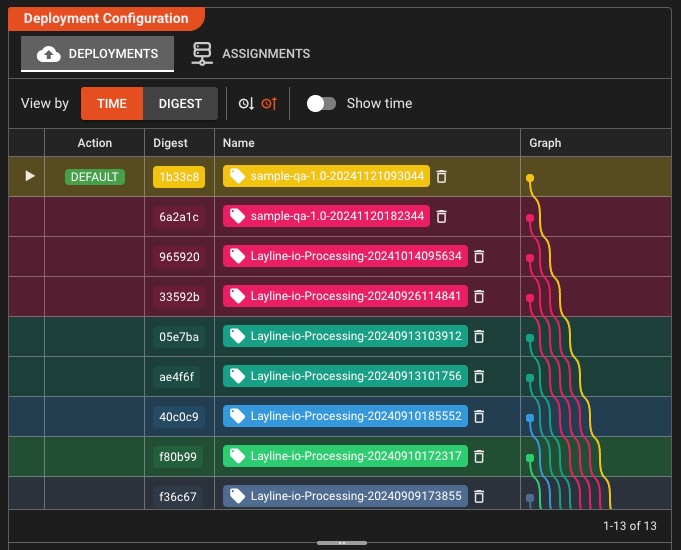
Detaillierte Bereitstellungskonfigurationen
Einmal erstellen, viele konfigurieren – erstellen Sie wiederverwendbare Bereitstellungszusammensetzungen, die auf jede Umgebung zugeschnitten sind, ohne doppelte Arbeitsabläufe
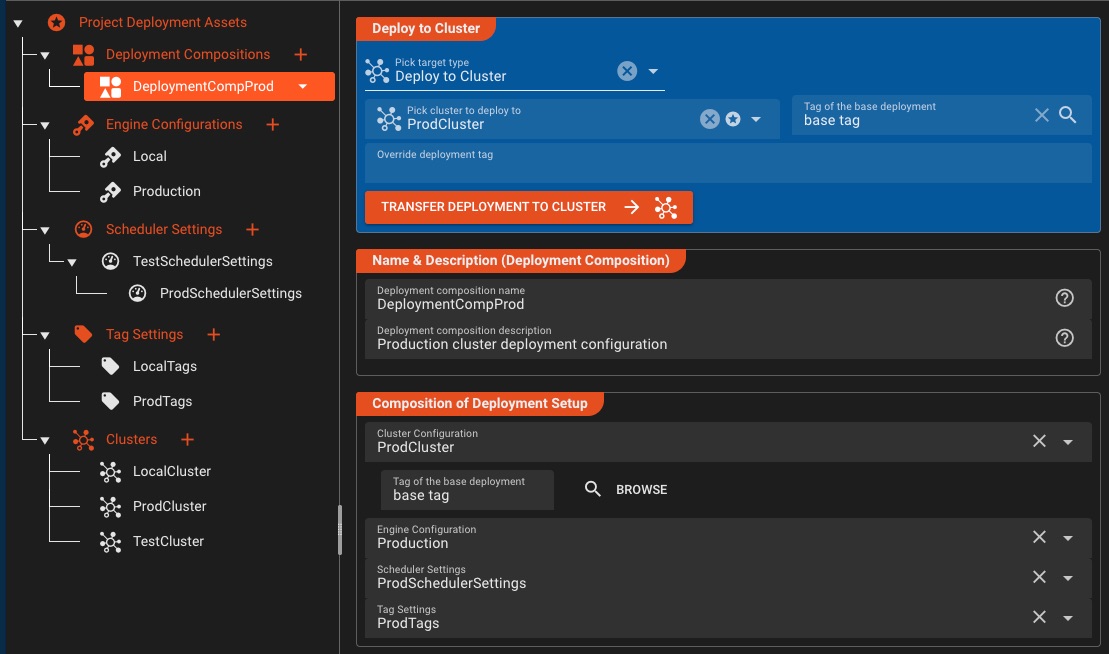
Zusammensetzbare Konfigurationen
- Engine-Konfigurationen pro Umgebung
- Scheduler-Einstellungen zur Instanzsteuerung
- Tag-Einstellungen für das Bereitstellungs-Targeting
- Bereitstellungszusammensetzungen kombinieren alle Konfigurationen
Umgebungsflexibilität
- Geheimnisse pro Umgebung überschreiben
- Umgebungsspezifische Variablenüberschreibungen
- Wählen Sie bei Bedarf den Zielcluster aus
- Verwalten Sie Test-, Entwicklungs- und Produktkonfigurationen unabhängig voneinander
Präzise Bereitstellung: Kombinieren Sie Engine-Konfigurationen, Scheduler-Einstellungen und Tag-Konfigurationen, um Bereitstellungszusammensetzungen zu erstellen, die perfekt zu jeder Umgebung passen – ohne Duplizierung von Arbeitsabläufen.
Dynamische Workflow-Planung
Skalieren Sie Workflow-Instanzen nach Bedarf und verteilen Sie die Verarbeitungsleistung intelligent in Ihrem Cluster
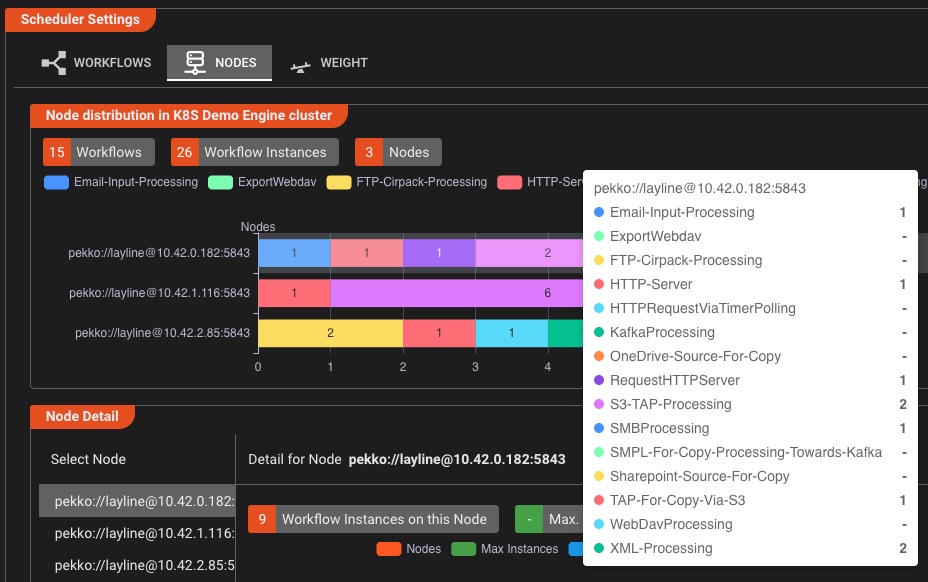
Intelligente Skalierung
- Passen Sie Workflow-Instanzen mit einem einzigen Klick an
- Definieren Sie minimale/maximale Instanzgrenzen
- Legen Sie die Verarbeitungsleistungspriorität pro Workflow fest
- Skalierung in Echtzeit ohne Ausfallzeiten
Clusterverteilung
- Visualisieren Sie die Lastverteilung über Knoten
- Heften Sie Workflows an bestimmte Clusterknoten an
- Arbeitslasten automatisch verteilen
- Überwachen Sie die Instanzverteilung in Echtzeit
Skalieren Sie mit Zuversicht: Erhöhen oder verringern Sie Workflow-Instanzen im Handumdrehen, weisen Sie bestimmte Arbeitslasten dedizierten Knoten zu und optimieren Sie die Zuweisung der Verarbeitungsleistung – alles über eine intuitive visuelle Benutzeroberfläche.
Enterprise Sicherheit und Verschlüsselung
Zero-Trust-Sicherheit mit Public-Private-Key-Verschlüsselung – schützen Sie Geheimnisse vor Entwicklern und sorgen Sie gleichzeitig für sicheren Zugriff
- Verschlüsselung mit öffentlichem und privatem Schlüssel
- Zentraler Sicherheitsspeicher
- Identität und vertrauenswürdige Zertifikate
- Rollenbasierter geheimer Zugriff
- Systemauthentifizierung von Drittanbietern
- mehr...
Zero-Trust durch Design: Nur wer über private Schlüssel verfügt, kann Geheimnisse entschlüsseln – Entwickler bleiben produktiv, ohne vertraulichen Anmeldeinformationen ausgesetzt zu sein.
Updates ohne Ausfallzeiten und sofortiger Versionswechsel
Aktualisieren Sie laufende Workflows, ohne ein einziges Ereignis zu löschen – der Cluster behält alle Bereitstellungsversionen bei und wechseln Sie mit einem Klick zu einer beliebigen
Versionswechsel
Cluster speichert alle Versionen – wechseln Sie mit einem Klick zu einer beliebigen
Kanarische Veröffentlichungen
Leiten Sie 5 % des Datenverkehrs zum Testen vor der vollständigen Einführung weiter
Sofortiger Rollback
Kehren Sie in <1 Sekunde zur vorherigen Version zurück
Gesundheitschecks
Automatische Validierung vor der Verkehrsumschaltung
Monitoring und Debugging
Vollständige Transparenz Ihrer Datenpipelines mit Echtzeitüberwachung und Debugging
Echtzeit-Überwachungs-Dashboards
Live-Leistungsmetriken und visuelle Einblicke für jeden Workflow
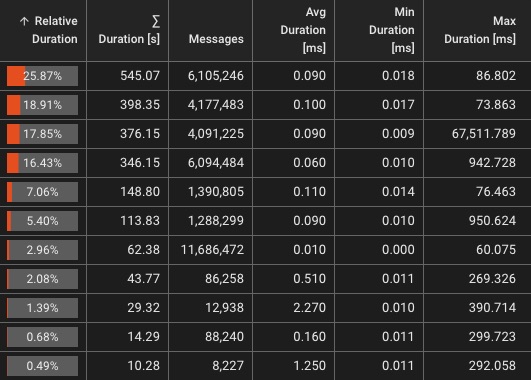
Live-Metriken
- Durchsatz (Ereignisse/Sek.)
- Fehlerraten und -typen
- Nachrichtenmetriken
Visualisierungen
- Verteilung der Workflow-Last
- Live-Flow-Diagramme
- Durchsatz pro Prozessor
Message Sniffing
Überprüfen Sie Live-Daten, die durch Ihre Pipelines fließen
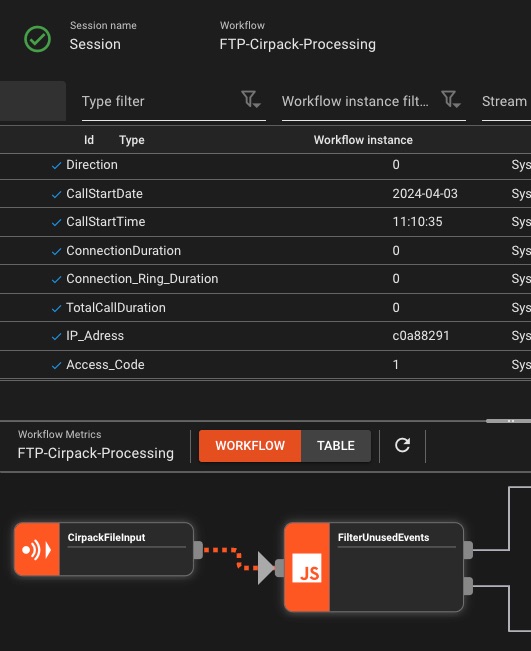
- Nachrichtenerfassung in Echtzeit
- Nach Inhalt/Metadaten filtern
- Formatbewusste Anzeige
- Proben exportieren
Profi-Tipp: Sniff an jedem Prozessor, um Transformationen in Aktion zu sehen
Prometheus Metriken & OpenTelemetry
Beobachtbarkeit nach Industriestandard, die sich in Ihren vorhandenen Stack integrieren lässt
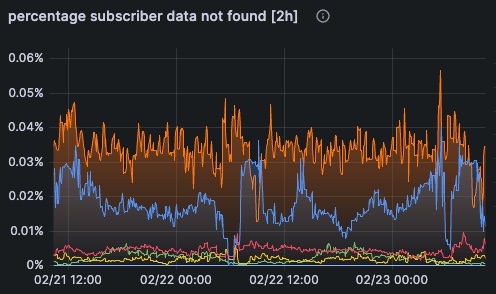
Live-Engine-Statusinspektor
Drilldown vom Cluster auf einzelne Prozessor-Ports – sehen Sie genau, was bereitgestellt und ausgeführt wird, ohne Quelldateien
- Hierarchische Bereitstellungsansicht
- Workflow-zu-Knoten-Verteilung
- Instanzanzahl pro Knoten
- Zustandsinspektion auf Prozessorebene
- Sichtbarkeit der Konfiguration
- Verbindungs- und Dienststatus
Produktionstransparenz: Überprüfen Sie, was tatsächlich in der Produktion läuft – von Workflows bis hin zu einzelnen Ports – auch ohne Projektquelldateien. Perfekt für die Fehlerbehebung und Bereitstellungsüberprüfung.
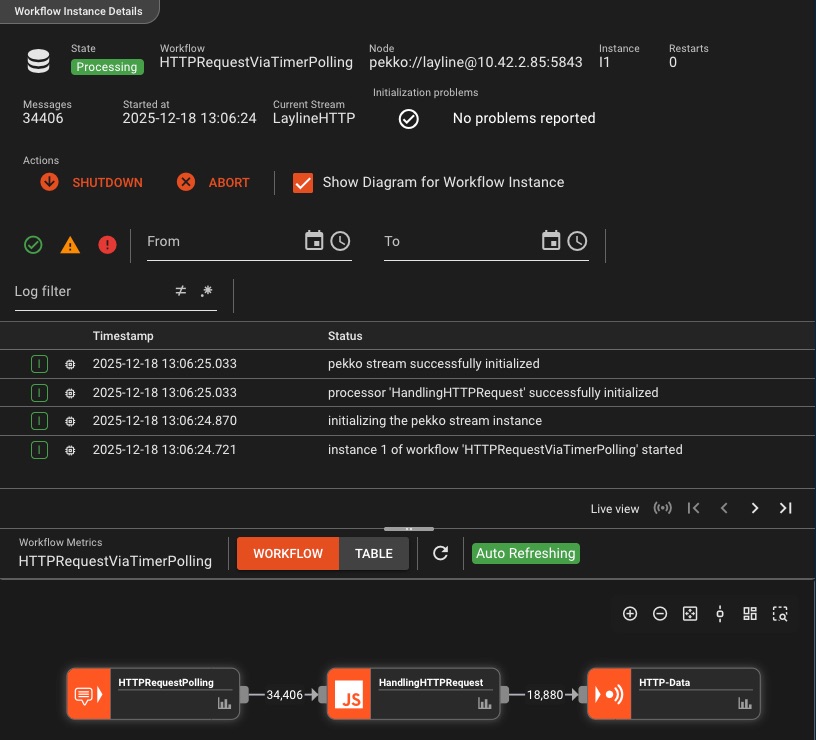
Umfassende Protokollierung und Audit-Trail
Jede Aktion, jedes Ereignis, jeder Fehler – vollständig protokolliert und nachvollziehbar mit detaillierter Sichtbarkeit pro Instanz
Granulare Sichtbarkeit
- Protokollierung pro Workflow-Instanz
- Ausführungsdetails auf Stream-Ebene
- Status- und Zustandsverfolgung
- Fehlerkontext und Stack-Traces
Kontrolle und Anpassung
- Benutzerdefinierte Protokollierungsnachrichten
- Workflow-Instanzen starten/stoppen
- Filtern Sie nach Schweregrad und Quelle
- Komplette Audit-Historie
Verlieren Sie nie den Kontext: Von der Initialisierung bis zum Herunterfahren wird jede Workflow-Aktion mit präzisen Zeitstempeln protokolliert, was eine schnelle Fehlerbehebung und vollständige Betriebstransparenz ermöglicht.
Live-Skript-Debugging in der Produktion
Debuggen Sie laufende Workflows auf jedem Clusterknoten mit Haltepunkten, schrittweiser Ausführung und Bearbeitung von Laufzeitvariablen – genau wie das DevTools Ihres Browsers
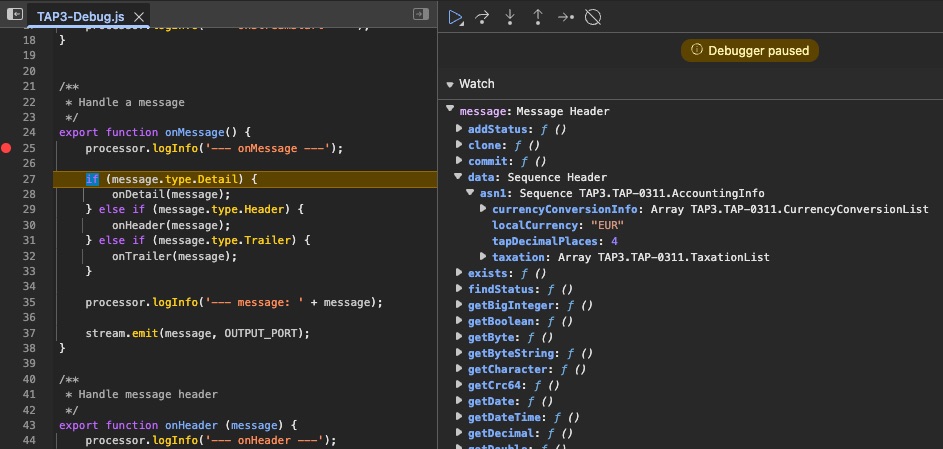
Interaktives Debuggen
- Legen Sie Haltepunkte in jedem Skript fest
- Gehen Sie den Code Zeile für Zeile durch
- Workflow am Haltepunkt anhalten
- Fortsetzen oder Einsteigen in Funktionen
Laufzeitinspektion und -manipulation
- Überprüfen Sie alle Variablen und Nachrichtendaten
- Ändern Sie Werte zur Laufzeit
- Testen Sie Edge-Fälle im laufenden Betrieb
- Debuggen Sie auf jedem Clusterknoten
Debugging auf Produktionsniveau: Fügen Sie Live-Workflows hinzu, legen Sie Haltepunkte fest und überprüfen Sie echte Nachrichten, während sie durch Ihre Pipeline fließen – ohne erneute Bereitstellung. Ändern Sie Variablen im Handumdrehen, um Fehlerbehebungen sofort zu testen.
Interaktives Testen von Servicefunktionen
Testen Sie Servicefunktionen isoliert: Führen Sie Datenbankabfragen aus, senden Sie E-Mails oder rufen Sie APIs direkt vom Dashboard aus auf, ohne Workflows auszuführen
- Funktionen interaktiv ausführen
- Füllen Sie Parameter im laufenden Betrieb aus
- Sofortige Ergebnisvalidierung
- Testen Sie DB-Abfragen live
- Validieren Sie alle Servicefunktionen
- Kein Workflow erforderlich
Testen Sie intelligenter, nicht härter: Warum sollten ganze Arbeitsabläufe neu erstellt und bereitgestellt werden, nur um eine Datenbankabfrage oder eine andere Dienstfunktion zu überprüfen? Testen Sie Servicefunktionen unabhängig, führen Sie schnelle Iterationen durch und liefern Sie sie zuverlässig aus.
Intelligente Warnungen und Benachrichtigungen
Lassen Sie sich benachrichtigen, wenn etwas schief geht – bevor Ihre Benutzer es bemerken
Schwellenwertwarnungen
Triggern Sie auf Latenz, Fehlerrate und Durchsatzanomalien
Workflow-Gesundheit
Stream-Status, Instanzfehler, Knotenverfügbarkeit
Dynamische Ziele
Definieren Sie Alarmziele im Handumdrehen: E-Mail, Teams usw.
Benutzerdefinierte Benachrichtigungsregeln
Erstellen Sie Vorlagen, Regeln und Zielgruppen
Läuft mit Deinem Stack
Standardbasierte Integration mit gängigen Tools und Protokollen
Erfahre Mehr
Erfahren Sie mehr über Anwendungsfälle, Preise und wie layline.io Ihren Anforderungen entspricht
Produktübersicht
Entdecken Sie die reaktive Architektur, die Plattformfunktionen und die technischen Grundlagen von layline.io
Erfahren Sie mehrBranchenlösungen
Sehen Sie, wie Teams in den Bereichen Finanzen, Telekommunikation, E-Commerce und mehr layline.io verwenden
Entdecken Sie LösungenWarum layline.io?
Vergleichen Sie layline.io mit anderen Plattformen und sehen Sie, wie wir abschneiden
Siehe VergleichPreise und Editionen
Vergleichen Sie die Editionen Community, Professional und Enterprise
Preise anzeigenBereit zum Start?
Testen Sie Community Edition kostenlos oder vereinbaren Sie eine Demo mit unserem Team
Legen Sie losFeature-Deep-Dives und Tutorials
Erfahren Sie, wie Sie die leistungsstarken Features von layline.io optimal nutzen

Die KI-Produktivitätslücke: Warum die Zahlen nicht aufgehen
Jedes Unternehmens-Dashboard behauptet, KI transformiere das Geschäft. Die tatsächlichen Produktivitätszahlen erzählen eine ganz andere Geschichte — und zu verstehen, warum das so ist, ist wichtig für jedes Team, das KI-Investitionsentscheidungen trifft.

Der AI Data Engineer: Was sich wirklich geändert hat (und was nicht)
Jeder Wettbewerbsblog veröffentlicht 'AI verändert die Datenverarbeitung.' Es ist alles atemlos und vage. Hier ist die ehrliche Bestandsaufnahme — was LLM-Tools wirklich helfen, was sie immer noch nicht berühren können und warum die '80% Automatisierung'-Behauptungen im Produktionsumfeld nicht standhalten.

Datenverträge sind die API-Versionierung, die Ihr Data Pipeline benötigt
Schema-Drift bricht ständig Pipelines, weil wir Änderungen überwachen, anstatt Verträge durchzusetzen. Hier ist der Grund, warum Datenverträge die fehlende Schicht zwischen Ihren Produzenten und Konsumenten sind.