Von Datenchaos
zu Echtzeit-Erkenntnissen
Erstellen Sie reaktive Datenpipelines mit einem visuellen Designer für Arbeitsabläufe. Kein Infrastruktur-Code, keine Anbieterabhängigkeit, nur schnelle und zuverlässige Datenverarbeitung in großem Maßstab.
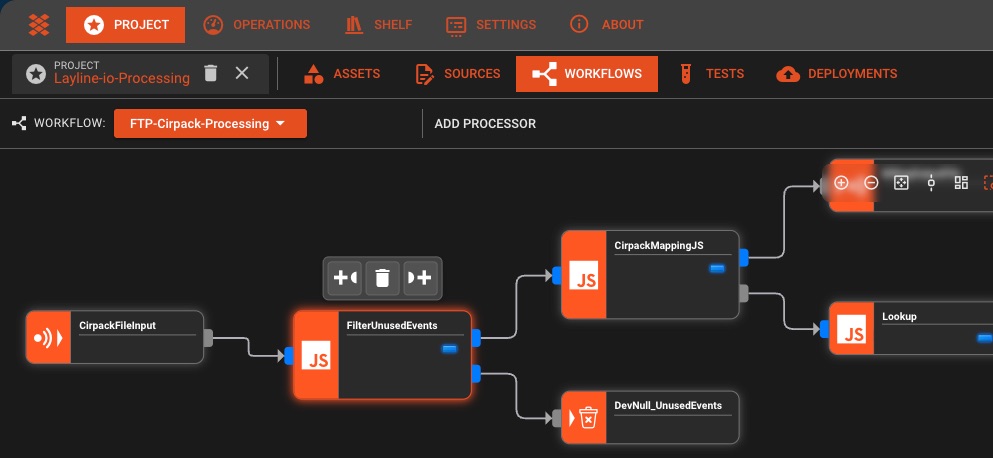
Der Data-Engineering Realitätscheck
Der Aufbau von Datenpipelines sollte keinen Doktortitel in verteilten Systemen erfordern. Dennoch verbringen die meisten Data Engineers 80 % ihrer Zeit damit, mit Infrastruktur zu kämpfen, statt Geschäftsprobleme zu lösen.
Infrastrukturkomplexität
Verwaltung von Kafka-Clustern, Kubernetes-Deployments und individuellem Monitoring über mehrere Umgebungen hinweg. Ihr Team braucht einen DevOps Engineer, nur um den Betrieb am Laufen zu halten.
Erkenntnisse aus 50 Postmortems bei Uber, Netflix und Stripe ->
Vendor-Lock-in-Albträume
Cloud-spezifische Services, die in Demos großartig wirken, Sie aber in proprietäre Ökosysteme zwingen. Eine Migration wird schnell zu einem sechsstelligen Projekt.
Zeit bis zur Produktion
Wochen oder Monate, um eine einfache Transformationspipeline bereitzustellen. Wenn sie live geht, haben sich die Business-Anforderungen bereits zweimal geändert.
Debugging von Black Boxes
Wenn Pipelines um 3 Uhr morgens ausfallen, tauchen Sie in Log-Aggregationssysteme über verteilte Services hinweg ein. Die Root Cause Analysis fühlt sich an wie digitale Archäologie.
Skalierungsengpässe
Was 1 Mio. Events bewältigt, verhält sich bei 10 Mio. Events völlig anders. Sie schreiben Ihre gesamte Pipeline-Architektur jedes Mal neu, wenn Sie wachsen.
Wie Lastspitzen 24 % der Incidents im großen Maßstab auslösten ->
Team-Zusammenarbeit
Business-Analysten verstehen Ihre Kafka-Konfigurationen nicht. Datenwissenschaftler können ihre Modelle nicht bereitstellen. Alle arbeiten in Silos.
Kommt Ihnen das bekannt vor?
Sie sind Dateningenieur geworden, um Intelligenz in Geschäftsprozesse zu bringen, nicht um Vollzeit Zuverlässigkeitsingenieur zu sein. Es gibt einen besseren Weg.
Die Lösung ansehenVisuelle Arbeitsabläufe.
Echte Ergebnisse.
Erstellen Sie Datenpipelines, indem Sie Blöcke verbinden, statt YAML zu schreiben. Verfolgen Sie Ihren Datenfluss in Echtzeit mit integriertem Monitoring und Fehlerbehandlung.
Drag-and-Drop-Editor
Visuelle Pipeline-Erstellung mit konfigurierbaren Prozessoren. Kein Code nötig, einfach die Punkte verbinden.
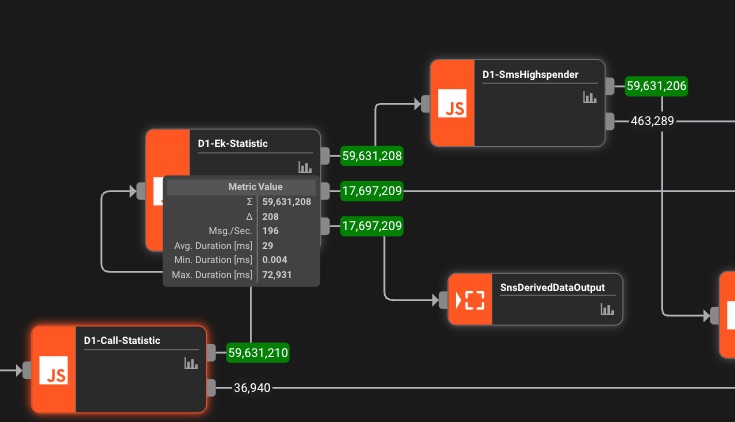
Echtzeit-Monitoring
Live-Metriken, Fehlerverfolgung und Performance-Einblicke. Sehen Sie genau, was in Ihrer Pipeline passiert.
Keine Infrastrukturarbeit
Läuft auf Ihrer Infrastruktur oder auf unserer. Automatische Skalierung, Hochverfügbarkeit und wartungsfreier Betrieb.
Die
Revolution
Hören Sie auf, mit Infrastruktur zu kämpfen. Beginnen Sie, Lösungen zu bauen, die wirklich etwas bewegen.
In Minuten bereitstellen
Überspringen Sie monatelangen Infrastrukturaufbau. Mit unserem visuellen Designer erstellen Sie produktive Pipelines schneller als beim Schreiben eines Kafka-Consumers.
Ruhig schlafen
Integriertes Monitoring, automatische Retries und Dead-Letter-Handling. Ihre Pipelines heilen sich selbst, während Sie sich auf die Business-Logik konzentrieren.
Mühelos skalieren
Vom Prototyp bis zur Produktionsskalierung. Bewältigen Sie Traffic-Spitzen, ohne Code neu zu schreiben oder Server zu provisionieren.
Unterm Strich
Schluss mit dem Infrastrukturkampf. Konzentrieren Sie sich auf das, was Ihr Unternehmen wirklich voranbringt.
"Endlich eine Datenplattform, die einfach funktioniert."

Sehen Sie layline.io
im Einsatz
Reale Lösungen von echten Data-Engineering Teams in unterschiedlichen Branchen
Echtzeit-Analytics-Dashboard
Ein E-Commerce-Unternehmen verarbeitet mehr als 50.000 Events pro Sekunde aus Web-Klicks, Käufen und Bestandsänderungen, um Live-Dashboards und Personalisierungs-Engines zu betreiben.

Fragen von Data Engineers
Häufige Fragen zur Implementierung von Echtzeit-Datenverarbeitung mit layline.io.
Die meisten Data Engineers haben layline.io innerhalb von 10 Minuten mit den ersten Datenströmen im Einsatz. Unser visueller Pipeline-Builder und vorgefertigte Konnektoren ersparen Wochen an individueller Entwicklungsarbeit.
layline.io verbindet Datenbanken, REST-APIs, Nachrichtenwarteschlangen, Dateisysteme, Streaming-Plattformen und individuelle Protokolle. Über visuelle Konfiguration verarbeitet es JSON, XML, ASCII, Binärdaten, ASN.1, HTTP und mehr.
layline.io ist für unternehmensweite Skalierung gebaut und verarbeitet mit horizontaler Skalierung Millionen von Ereignissen pro Sekunde. Unsere verteilte Architektur sorgt auch bei Traffic-Spitzen für konstante Leistung, inklusive integriertem Backpressure-Handling.
Ja. Bereitstellung vor Ort, in jeder Cloud oder hybrid. layline.io arbeitet mit Ihren bestehenden Datenbanken, Data Lakes, Warehouses und Analysewerkzeugen, ohne architektonische Änderungen zu erzwingen.
Wir bieten technischen Support, Dokumentation, Video-Tutorials und Onboarding-Begleitung. Unser Team hilft Datenengineering-Teams dabei, Pipelines hinsichtlich Leistung und Zuverlässigkeit zu optimieren.
Die Preisgestaltung von layline.io skaliert mit Ihrer Nutzung. Sie zahlen nur für das, was Sie verarbeiten, mit planbaren Kosten, die mit Ihrem Unternehmen wachsen. Unternehmenspläne beinhalten dedizierten Support und individuelle SLAs.
Erstellen Sie Ihre erste Pipeline in wenigen Minuten
Laden Sie layline.io kostenlos herunter und beginnen Sie mit dem Aufbau reaktiver Datenpipelines ohne die übliche Komplexität. Keine Kreditkarte erforderlich.
Ressourcen für Data Engineers
Fallstudien, technische Leitfäden und Best Practices für den Aufbau von Datenpipelines

Die KI-Produktivitätslücke: Warum die Zahlen nicht aufgehen
Jedes Unternehmens-Dashboard behauptet, KI transformiere das Geschäft. Die tatsächlichen Produktivitätszahlen erzählen eine ganz andere Geschichte — und zu verstehen, warum das so ist, ist wichtig für jedes Team, das KI-Investitionsentscheidungen trifft.

Der AI Data Engineer: Was sich wirklich geändert hat (und was nicht)
Jeder Wettbewerbsblog veröffentlicht 'AI verändert die Datenverarbeitung.' Es ist alles atemlos und vage. Hier ist die ehrliche Bestandsaufnahme — was LLM-Tools wirklich helfen, was sie immer noch nicht berühren können und warum die '80% Automatisierung'-Behauptungen im Produktionsumfeld nicht standhalten.

Datenverträge sind die API-Versionierung, die Ihr Data Pipeline benötigt
Schema-Drift bricht ständig Pipelines, weil wir Änderungen überwachen, anstatt Verträge durchzusetzen. Hier ist der Grund, warum Datenverträge die fehlende Schicht zwischen Ihren Produzenten und Konsumenten sind.