
Was wir demonstrieren
Wir präsentieren ein einfaches layline.io-Projekt, das Daten aus einer Datei liest und deren Inhalte in ein Kafka-Topic ausgibt.
Um die Demonstration in einer realen Umgebung nachzuvollziehen, können Sie die Assets dieses Projekts aus dem Ressourcenbereich am Ende herunterladen. Lesen Sie dies, um zu erfahren, wie Sie das Projekt in Ihre Umgebung importieren können.
Konfiguration
Der Workflow
Übersicht
Die Workflow-Konfiguration dieser Demonstration wurde mit dem Workflow Editor von layline.io erstellt und sieht wie folgt aus:
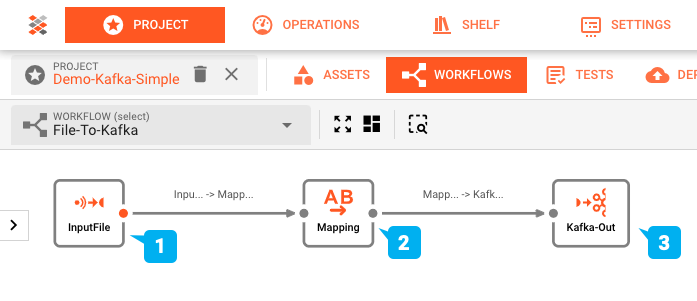
- (1) Input Processor: Liest eine Eingabedatei mit einer Header-/Detail-/Trailer-Struktur, dann
- (2) Flow Processor: Mapped diese in ein Ausgabeformat, welches anschließend
- (3) Output Processor: in ein Kafka-Topic geschrieben wird.
Für diese Demonstration verwenden wir ein Kafka-Topic, das von Cloud Karafka gehostet wird. Wenn Sie die Demonstration selbst durchführen, benötigen Sie also keine eigene Kafka-Installation.
Konfiguration der zugrunde liegenden Assets
Der Workflow basiert auf einer Reihe von zugrunde liegenden Assets, die mit dem Asset Editor konfiguriert werden. Die logische Verbindung zwischen Workflow und Assets kann wie folgt verstanden werden:
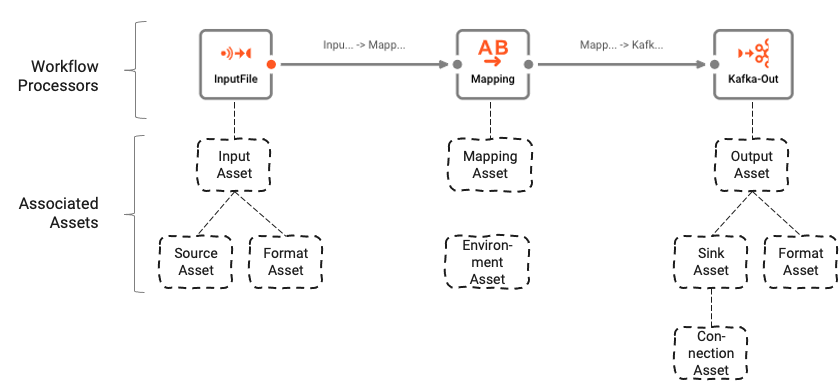
Workflows bestehen aus einer Reihe von Prozessoren, die durch Links verbunden sind.
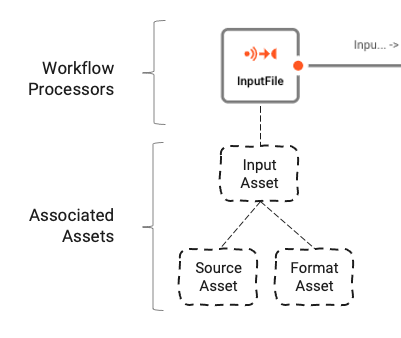
Prozessoren basieren auf Assets. Assets sind Konfigurationseinheiten, die einer bestimmten Klasse und einem bestimmten Typ angehören. Im obigen Bild sehen wir einen Prozessor mit dem Namen "InputFile", der der Klasse Input Processor und dem Typ Stream Input Processor angehört. Dieser wiederum basiert auf zwei weiteren Assets, "Source Asset" und "Format Asset", die vom Typ File System Source bzw. Generic Format sind.
Kurz gesagt:
- Ein Workflow besteht aus miteinander verbundenen Prozessoren
- Prozessoren basieren auf Assets, die sie definieren
- Assets können auf andere Assets angewiesen sein
Environment Asset: "My-Environment"
Zunächst: layline.io kann mehrere verschiedene Umgebungen mit Environment Assets verwalten. Dies ist besonders hilfreich, wenn dasselbe Projekt in Test-, Staging- und Produktionsumgebungen verwendet wird, die unterschiedliche Verzeichnisse, Verbindungen, Passwörter usw. erfordern. In diesem Projekt verwenden wir ein Environment Asset (2).
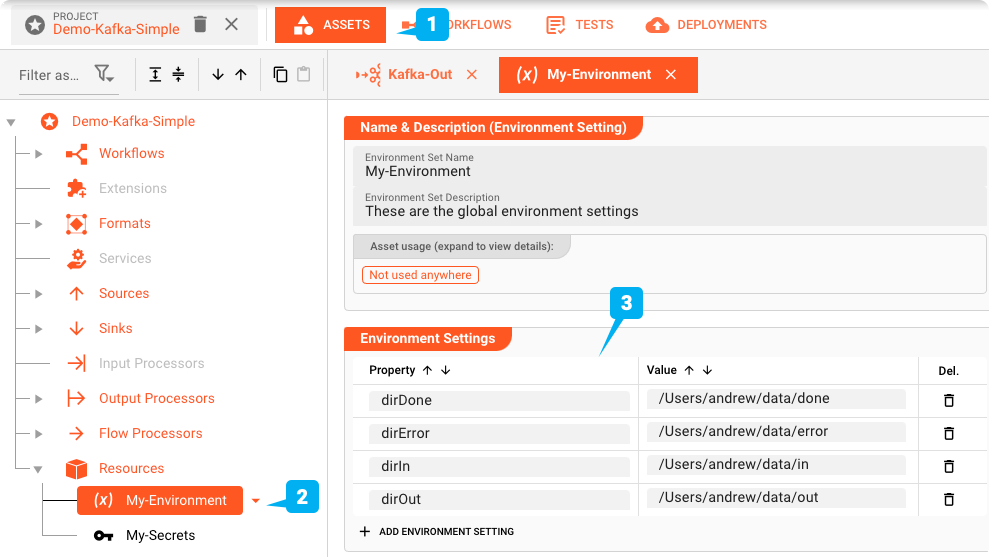
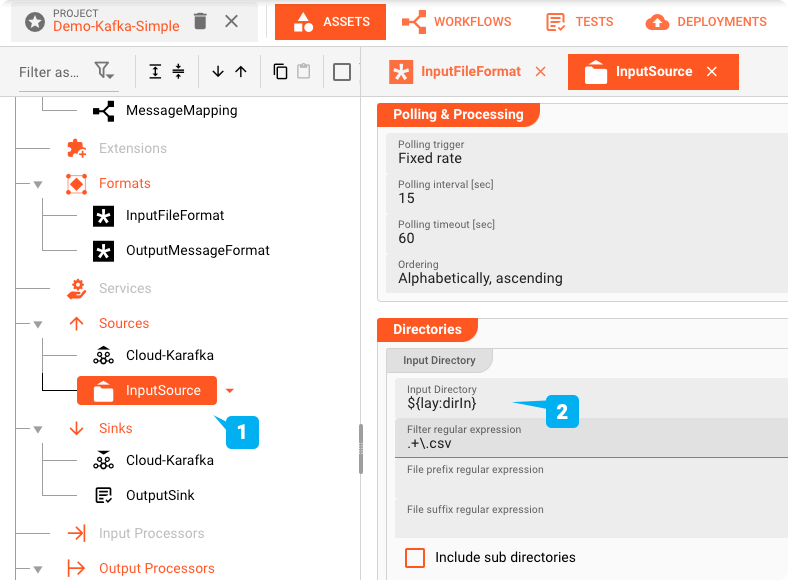
Solche Variablen können im gesamten Projekt mit einem Makro wie ${lay:dirIn} verwendet werden. Betriebssystem- oder Java-Systemumgebungsvariablen werden mit env: bzw. sys: anstelle von lay: vorangestellt.
Stream Input Processor: "InputFile"
Der Input Processor (Name: InputFile / Typ: Stream Input Processor) kümmert sich um das Lesen der Eingabedateien und das Weiterleiten der Daten innerhalb des Workflows.
Generic Format Asset: "InputFileFormat"
layline.io bietet die Möglichkeit, komplexe Datenstrukturen mit einer eigenen Grammatiksprache zu definieren. Die Datei in unserem Beispiel ist ein Muster für Banktransaktionen. Sie enthält einen Header-Datensatz mit zwei Feldern, eine Reihe von Detaildatensätzen mit den Transaktionsdetails und schließlich einen Trailer-Datensatz.
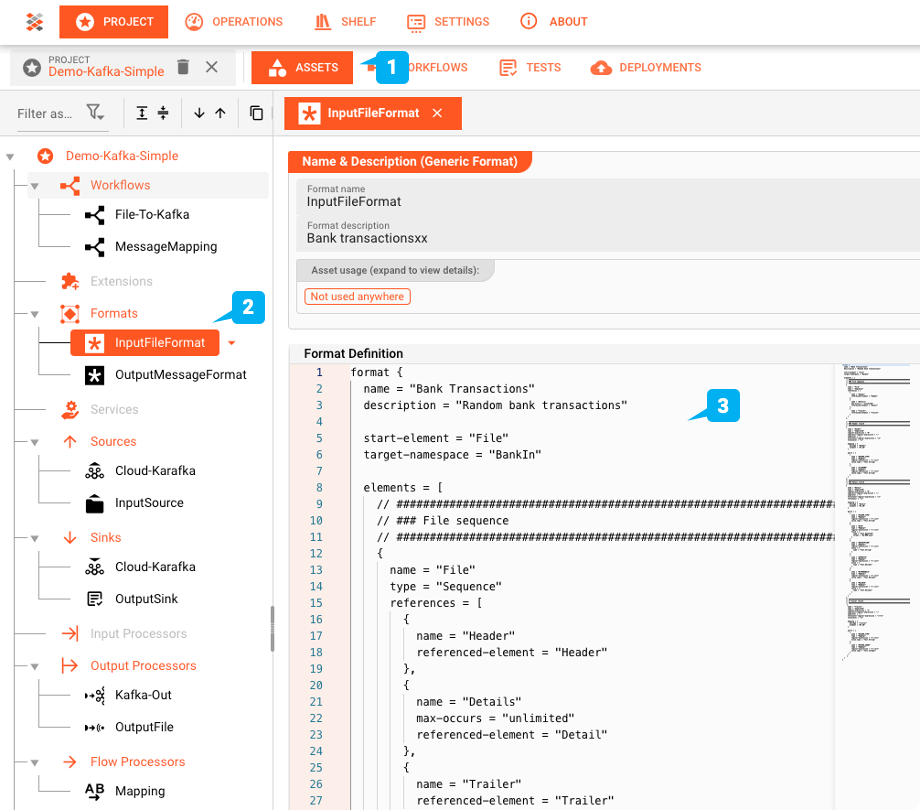
File-System-Source Asset: "InputSource"
Das "InputSource" ist ein Asset vom Typ File System Source, das verwendet wird, um zu definieren, woher die Datei gelesen wird.
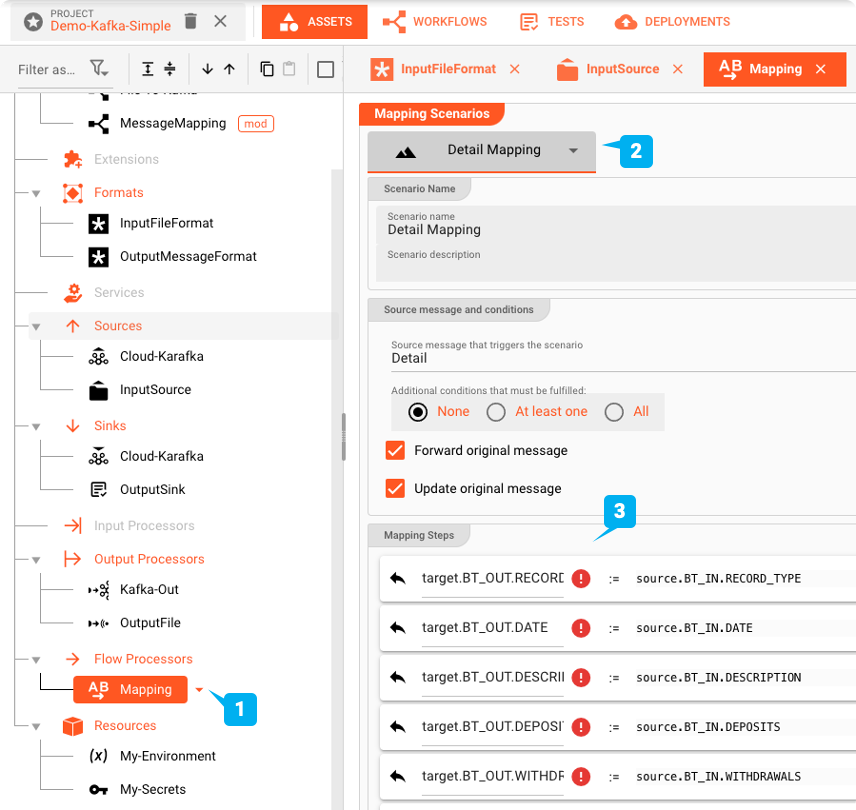
Flow Processor: Map
Das Mapping Asset ermöglicht es, Werte vom Eingabe- in das Ausgabeformat zuzuordnen.
Stream Output Processor: Kafka
Der letzte Prozessor im Workflow ist der Output Processor "Kafka-Out".
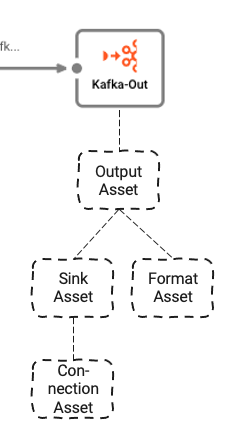
Er basiert auf drei zugrunde liegenden Assets:
- Output Asset: Definiert Kafka-Topics und Partitionen, in die wir schreiben
- Kafka Sink Asset: Der Sink, den das Output Asset verwenden kann, um Daten zu senden
- Generic Format Asset: Definiert, in welchem Format die Daten an Kafka geschrieben werden
- Kafka Connection Asset: Definiert die physischen Kafka-Verbindungsparameter
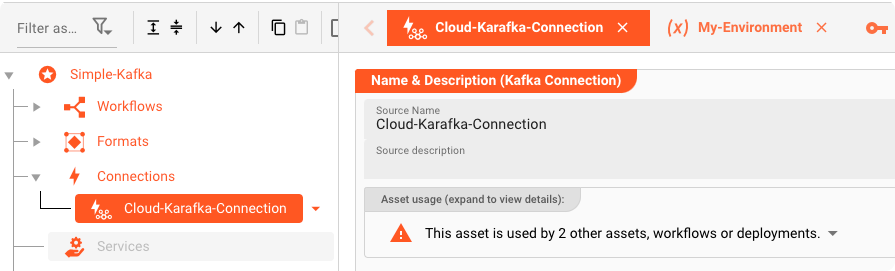
Kafka Connection Asset: "Cloud-Karafka-Connection"
Um Daten an Kafka auszugeben, müssen wir zunächst ein Kafka Connection Asset definieren.
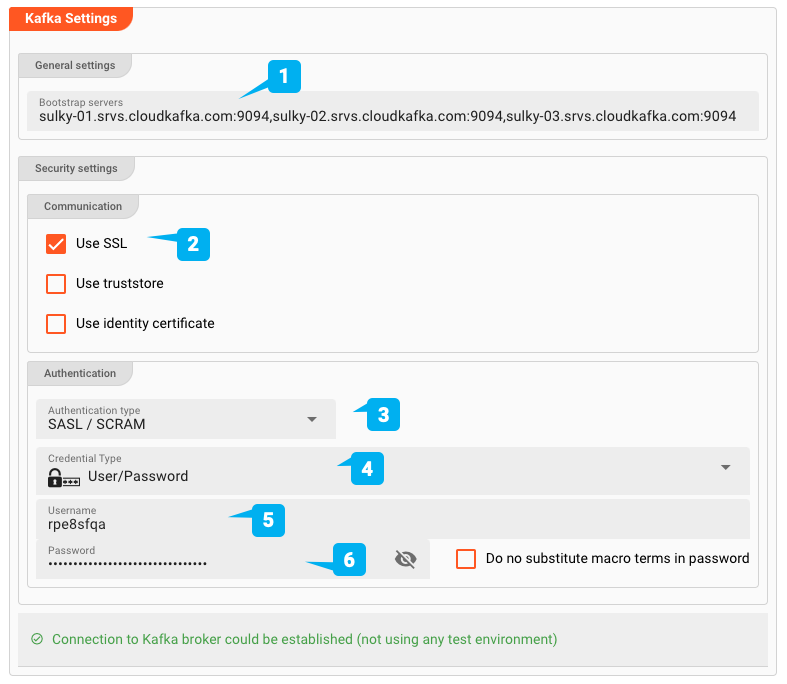
- (1) Bootstrap servers: Die Adressen von einem oder mehreren Bootstrap-Servern
- (2) Use SSL: Definiert, ob es sich um eine SSL-Verbindung handelt
- (3) Authentication type: SASL / Plaintext oder SASL / SCRAM
- (4/5/6) Credentials: Benutzername/Passwort
Deployment & Ausführung
Übertragung des Deployments
Um das Deployment durchzuführen, wechseln wir zur DEPLOYMENT-Registerkarte des Projekts:
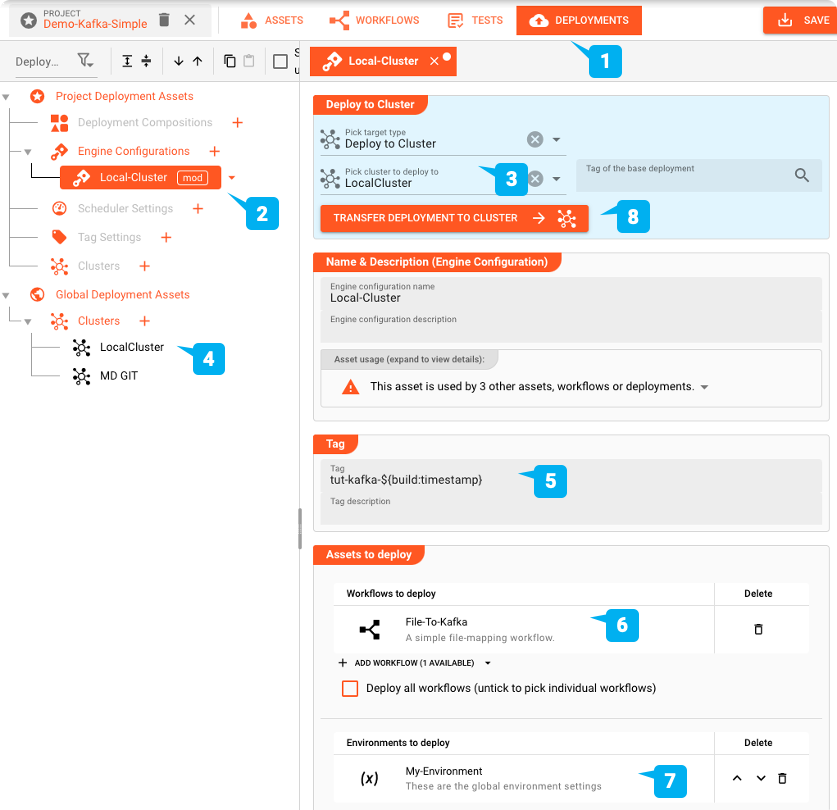
Wir erstellen eine Engine Configuration, um das Projekt bereitzustellen. Dies definiert die Teile des Projekts, die wir bereitstellen möchten.
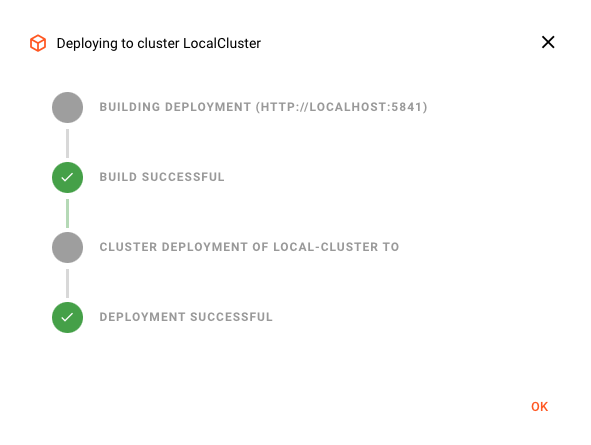
Aktivierung des Deployments
Wir wechseln zur "CLUSTER"-Registerkarte:
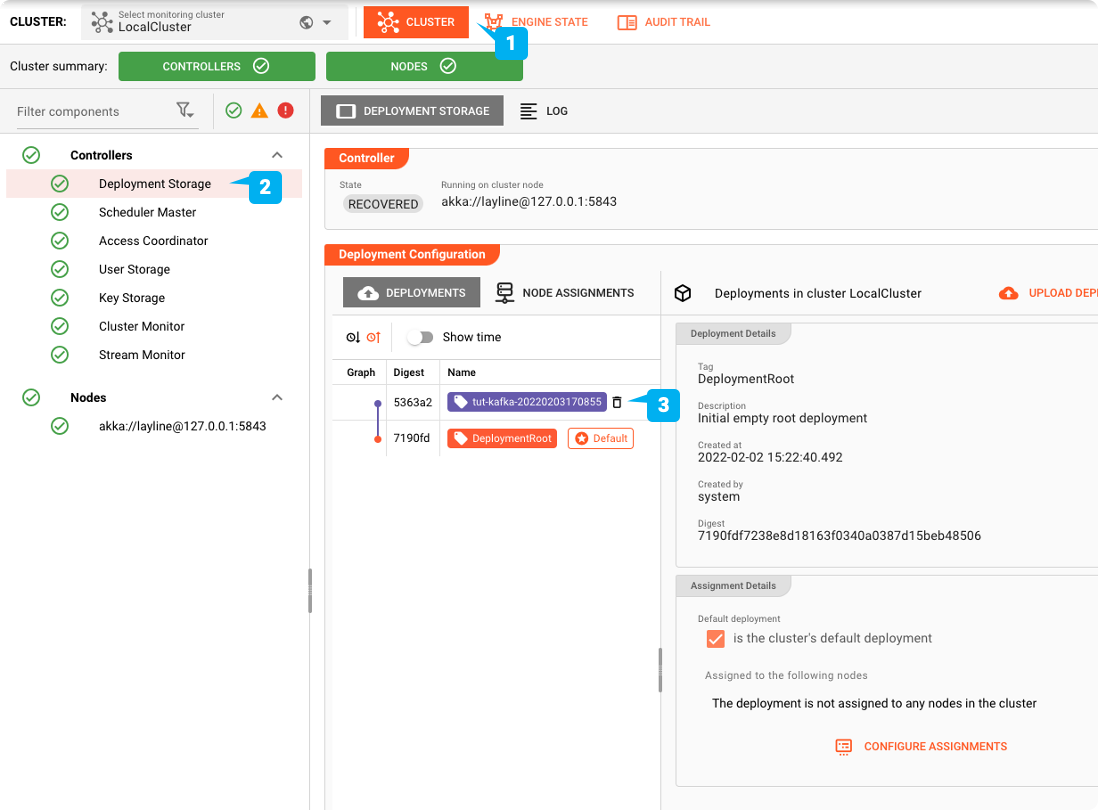
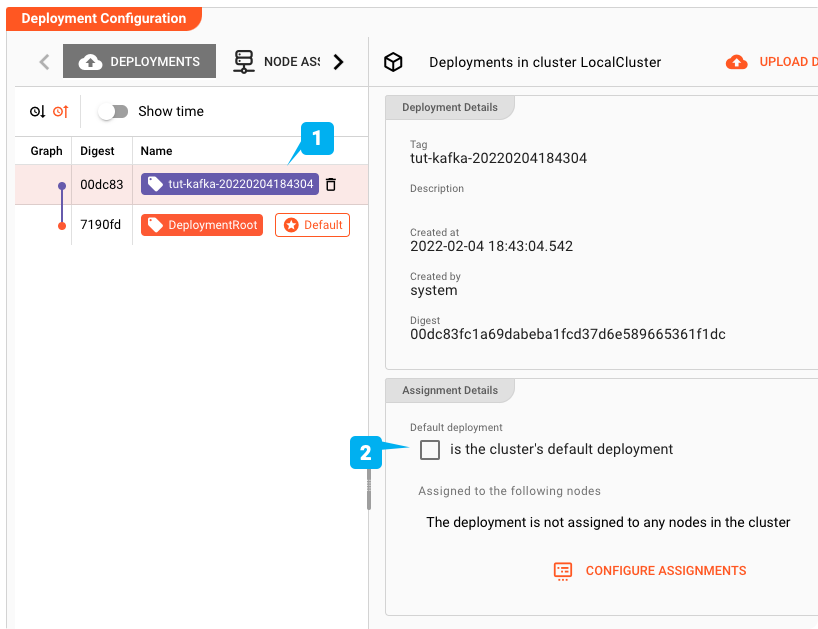
Als Standard-Deployment festlegen
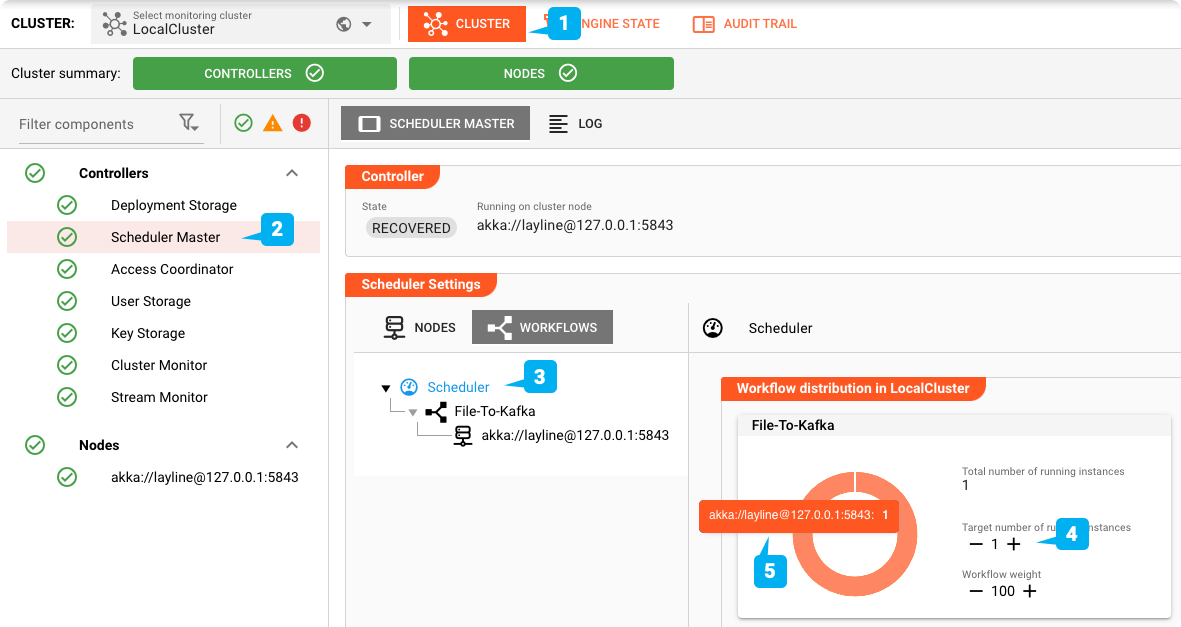
Zeitplan
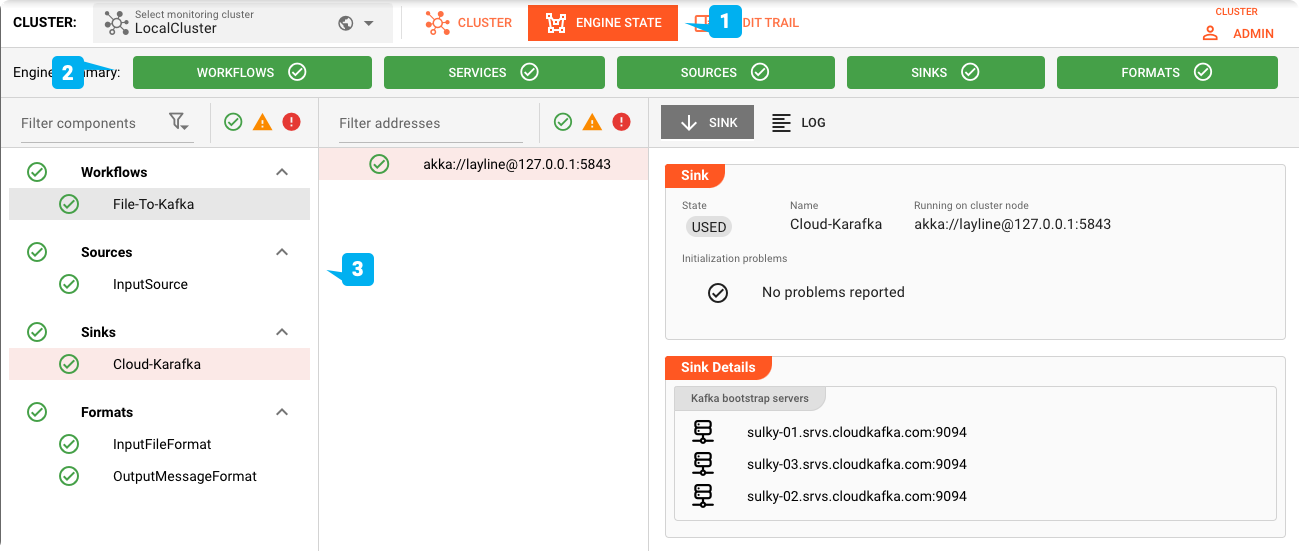
Engine-Status
Testdatei einfügen
Zum Testen legen wir unsere Testdatei in das Eingabeverzeichnis, das wir konfiguriert haben.
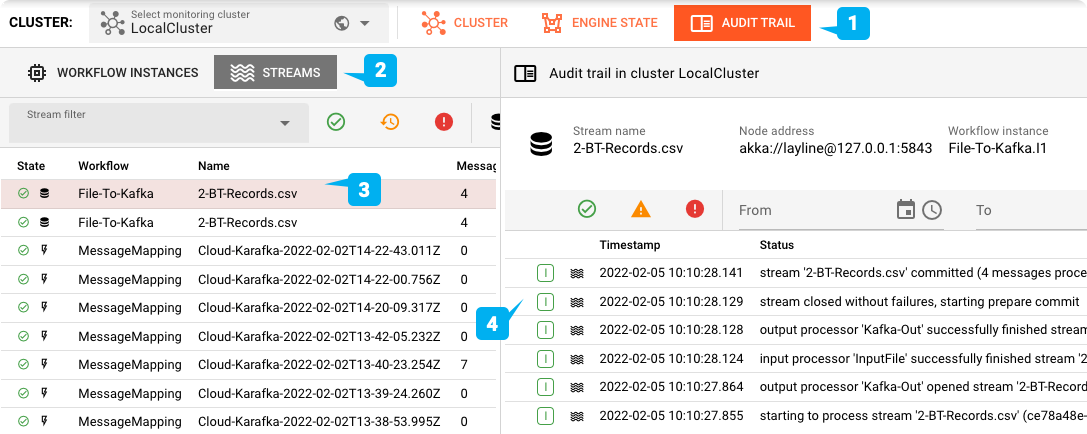
Sie können das Cloud Karafka-Topic mit einem Tool Ihrer Wahl überprüfen:

Zusammenfassung
Diese Demonstration zeigt, wie Sie einen File-to-Kafka-Workflow im Handumdrehen und ohne großen Aufwand erstellen können. Und Sie erhalten noch viel mehr direkt out-of-the-box:
- Reaktiv — Nutzt das reaktive Verarbeitungsparadigma
- Hohe Skalierbarkeit — Skaliert innerhalb einer Engine-Instanz und darüber hinaus
- Resilienz — Ausfallsicher in verteilten Umgebungen
- Automatisches Deployment — Änderungen in der Konfiguration mit einem Klick bereitstellen
- Echtzeit und Batch — Beides auf derselben Plattform ausführen
- Metriken — Automatische Generierung von Metriken für das Monitoring (z. B. Prometheus)
Ressourcen
| # | Beschreibung |
|---|---|
| 1 | Github: Simple Kafka Project |
| 2 | Eingabe-Testdateien im Verzeichnis _test_files des Projekts |
| 3 | Cloud Karafka-Zugangsdaten in der Datei cloud-karafka-credentials.txt |
| # | Dokumentation |
|---|---|
| 1 | Getting Started |
| 2 | Importing a Project |
| 3 | What are Assets, etc? |
- Lesen Sie mehr über layline.io hier.
- Kontaktieren Sie uns unter hello@layline.io.

