
Wie vergleicht sich layline.io mit Kafka?
Diese Frage hören wir von Zeit zu Zeit. Wir fragen uns, warum. Um es besser zu verstehen, schauen wir uns an, was Kafka ist:
Was ist Kafka?
So beschreibt es AWS:
"Apache Kafka ist ein verteiltes Datenspeicher-System, das für das Einlesen und Verarbeiten von Streaming-Daten in Echtzeit optimiert ist. Streaming-Daten sind Daten, die kontinuierlich von Tausenden von Datenquellen erzeugt werden, die typischerweise die Datenaufzeichnungen gleichzeitig senden. Eine Streaming-Plattform muss diesen konstanten Datenzufluss bewältigen und die Daten sequentiell und inkrementell verarbeiten.
Kafka bietet seinen Nutzern drei Hauptfunktionen:
- Veröffentlichen und Abonnieren von Datenströmen.
- Effektives Speichern von Datenströmen in der Reihenfolge, in der die Aufzeichnungen erzeugt wurden.
- Verarbeitung von Datenströmen in Echtzeit.
Kafka wird hauptsächlich verwendet, um Echtzeit-Streaming-Datenpipelines und Anwendungen zu erstellen, die sich an die Datenströme anpassen. Es kombiniert Messaging, Speicherung und Stream-Verarbeitung, um sowohl historische als auch Echtzeit-Daten zu speichern und zu analysieren."
Unsere Sicht auf Kafka
In der obigen Beschreibung gibt es ein wenig Technogeschwafel, das wir ansprechen müssen. Es spricht von Streaming-Verarbeitung, Echtzeit usw. Was bedeutet das alles im Kontext von Kafka?
- Kafka ist in erster Linie eine Datenspeicherlösung. Es sollte als eine spezielle Art von Datenbank betrachtet werden, in der Daten in Warteschlangen (Topics) gespeichert werden. Es gibt verschiedene Möglichkeiten, wie diese Warteschlangen beschrieben (veröffentlicht) und dann gelesen (abonniert) werden können. Warteschlangen folgen dem FIFO-Prinzip (First-In-First-Out). Es gibt das Argument, dass Kafka kein Speicher, sondern ein Streaming-Ereignisprozessor ist, aber das ist unserer Meinung nach irreführend. Kafka ist darauf ausgelegt, Daten zu speichern und dann von Verbrauchern schnell gelesen zu werden. Es ist darauf ausgelegt, gespeicherte Daten nach einer vorkonfigurierten Aufbewahrungsfrist zu löschen, unabhängig davon, ob die Daten konsumiert wurden oder nicht. In diesem Sinne ist es ein temporärer Datenspeicher mit einigen sehr speziellen, wenn auch nützlichen Funktionen.
- Einzelne Prozesse können in Warteschlangen veröffentlichen (Produzenten) oder Warteschlangen abonnieren (Verbraucher). Wenn keiner der vorgefertigten Konnektoren (siehe unten) als Produzent/Verbraucher für Ihren Zweck ausreicht (wahrscheinlich), müssen Sie einen selbst programmieren (die meisten verwenden Java, aber es gibt auch andere Optionen).
- Kafka kann in einer Cloud-nativen, verteilten Umgebung laufen, die Resilienz und Skalierbarkeit bietet.
Confluent (das Unternehmen) hat Kafka einige weitere Funktionen hinzugefügt, wie vorgefertigte "Konnektoren". Konnektoren sind spezielle Arten von Produzenten und Verbrauchern, die spezielle Arten von Datenquellen/-senken von/zu Kafka-Topics lesen/schreiben können. Sie sind ziemlich begrenzt und spezialisiert in dem, was sie tun können.
Darüber hinaus haben sie die Fähigkeit geschaffen, Daten mit "ksql" zu "filtern, zu leiten, zu aggregieren und zu kombinieren". Es wird suggeriert, dass Sie Informationen in Echtzeit von Kafka-Topics filtern und leiten können. Klingt großartig. Es ist jedoch nur eine weitere Art von Verbraucher, der Daten von einem Kafka-Topic liest, dann filtert, aggregiert, kombiniert und die Ergebnisse an ein anderes Topic weiterleitet, damit ein anderer Verbraucher sie lesen kann. Der beste Weg, dies logisch zu vergleichen, ist die Analogie zu einer tabellengesteuerten Datenbank (z.B. Oracle), in der Sie Daten von einer Tabelle in eine andere kopieren, indem Sie SQL verwenden; außer dass es bei Kafka viel komplizierter ist.
Kafka hat einige, aber keine bedeutenden Fähigkeiten zur Datenumwandlung. Eines der großen Hindernisse hier ist, dass Kafka keine inhärente Fähigkeit hat, Daten zu parsen und somit daran zu arbeiten. Es unterstützt nur sehr wenige begrenzte Datenformate. Alles Ungewöhnliche (wahrscheinlich) erfordert benutzerdefinierte Programmierung von Produzenten und Verbrauchern, um die Aufgabe zu erledigen. Dies ist wiederum wie bei jeder anderen Datenbank, die sich hauptsächlich um Interna kümmert, nicht um Externa. Insgesamt ist es fair zu sagen, dass Kafka Daten nicht wirklich verarbeitet. Es speichert lediglich Daten. Jedes andere Szenario impliziert das Verketten von atomaren Topics mit Produzenten und Verbrauchern.
Kafka ist auch dafür bekannt, ziemlich schwer zu bedienen zu sein. Es gibt keine umfassende Benutzeroberfläche. So ziemlich alles wird in Konfigurationsdateien konfiguriert und über die Befehlszeile betrieben.
Zusammenfassung
Der Hauptzweck von Kafka ist:
- Schnelle Datenspeicherung
- Für große Volumina
- Die sowohl schnell produziert als auch konsumiert werden
Wir lieben Kafka für diesen Zweck. Es ist großartig, und wir nutzen es häufig in Implementierungen, obwohl es auch mehrere andere Lösungen gibt, um dies zu erreichen.
Was ist layline.io?
layline.io ist ein schneller, skalierbarer, robuster Ereignisdatenprozessor. Es kann Daten in Echtzeit einlesen, verarbeiten und ausgeben. Verarbeiten bedeutet, "etwas" mit den Daten zu tun, im Gegensatz zu dem, was Kafka tut (speichern). Ein wesentlicher Unterschied zu Kafka ist beispielsweise, dass sich bei layline.io alles um den Begriff "Workflows" dreht. Workflows spiegeln datengesteuerte Logik wider, die häufig komplexe Datenorchestrierung ähnelt.
Dies bedeutet:
- die Daten zu interpretieren,
- sie zu analysieren,
- zu entscheiden und sie möglicherweise in Echtzeit durch Konsultation anderer Quellen anzureichern
- Statistiken zu erstellen
- sie zu filtern,
- sie zu leiten,
- ansonsten unterschiedliche Datenquellen und -senken zu integrieren.
und all dies in:
- Echtzeit,
- transaktionssicher (Option),
- ohne Speicher-Overhead,
- konfigurierbar,
- UI-gesteuert
- und vieles mehr
Beispiel-Workflow:
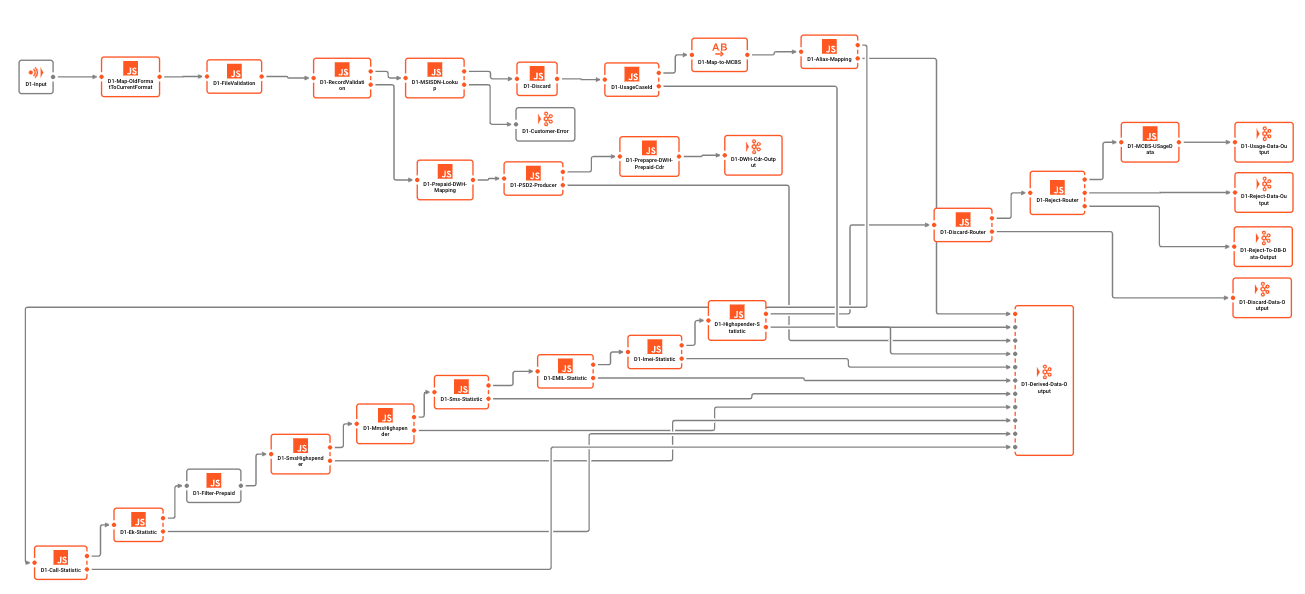
Kafka unterstützt Workflows nicht von Haus aus. Alles, was in Kafka als Workflow interpretiert werden könnte, ist eher ein Versuch, eine Verkettung von Kafka-Warteschlangen und Verbrauchern/Produzenten als Workflow zu "verkaufen". Beachten Sie jedoch, dass jede dieser Einheiten individuelle Einheiten sind, die sich nicht gegenseitig kennen. Es gibt keine übergreifende (Transaktions-)Kontrolle, noch gibt es tatsächliche Unterstützung für Workflows innerhalb von Kafka.
Kombination von Kafka und layline.io
Aus der Sicht von Kafka bedeutet dies, dass layline.io als Produzent (schreiben) oder Verbraucher (lesen) angesehen wird. Aus der Sicht von layline.io wird Kafka als Ereignisdatenbank betrachtet, vergleichbar mit anderen Datenbanken wie SQL-DBs, NOSQL-DBs oder sogar dem Dateisystem. Das ist eine großartige Kombination, abhängig vom Anwendungsfall. layline.io fungiert in diesem Kontext als das Datenorchestrierungselement zwischen einer theoretisch unbegrenzten Anzahl von Kafka-Topics und anderen Quellen und Senken außerhalb der Kafka-Sphäre.
Aus diesem Blickwinkel sind Kafka und layline.io extrem komplementär, nicht wettbewerbsfähig. Die Überschneidung ist minimal. Wir sehen kein sinnvolles Szenario, in dem ein potenzieller Kunde sich zwischen dem einen oder dem anderen entscheiden würde, sondern eher für das eine und das andere.
Wie kommen Kafka-Nutzer heute zurecht?
Der typische Kafka-Nutzer von heute nutzt Kafka als das, was es ist: Eine spezielle Art von Ereignisdatenbank. Um Daten darauf zu schreiben und davon zu lesen. Er programmiert hauptsächlich benutzerdefinierte Verbraucher und Produzenten. Diese benutzerdefinierten Teile müssen dann die Punkte 1 bis 6 von oben enthalten (Hinweis: sie werden es nicht). Sie gewährleisten außerdem keine Resilienz, Skalierbarkeit, Berichterstattung, Überwachung und alles andere, was von solchen Komponenten erwartet werden müsste. Sie werden oft mit einfachen Skripting-Tools wie Python bis hin zu anspruchsvolleren Microservice-Frameworks wie Spring Boot et al. gebaut.
Stattdessen könnten sie einfach layline.io verwenden und all das oben Genannte erhalten.
Beispiel für eine reale Bereitstellung
Dieser tatsächliche Kunde verwendet layline.io, um alle Kundennutzungsdaten (Kommunikationsmetadaten) zu verarbeiten.
Vor der Implementierung von layline.io befanden sie sich in einer Situation, die dem im vorherigen Absatz beschriebenen Szenario sehr ähnelte. Mehrere Kafka-Warteschlangen wurden von einzelnen benutzerdefinierten Prozessen gespeist. Andere solche Prozesse lasen aus diesen Warteschlangen und schrieben Daten in andere Ziele in anderen Formaten und mit angewandter Logik. Eine unordentliche und fehleranfällige Architektur, die kostspielig zu warten war und fast unmöglich zu verwalten.
Nach der Implementierung von layline.io, bei der die vorherige Geschäftslogik und die Prozessoren ersetzt wurden, sah die Architektur wie folgt aus:
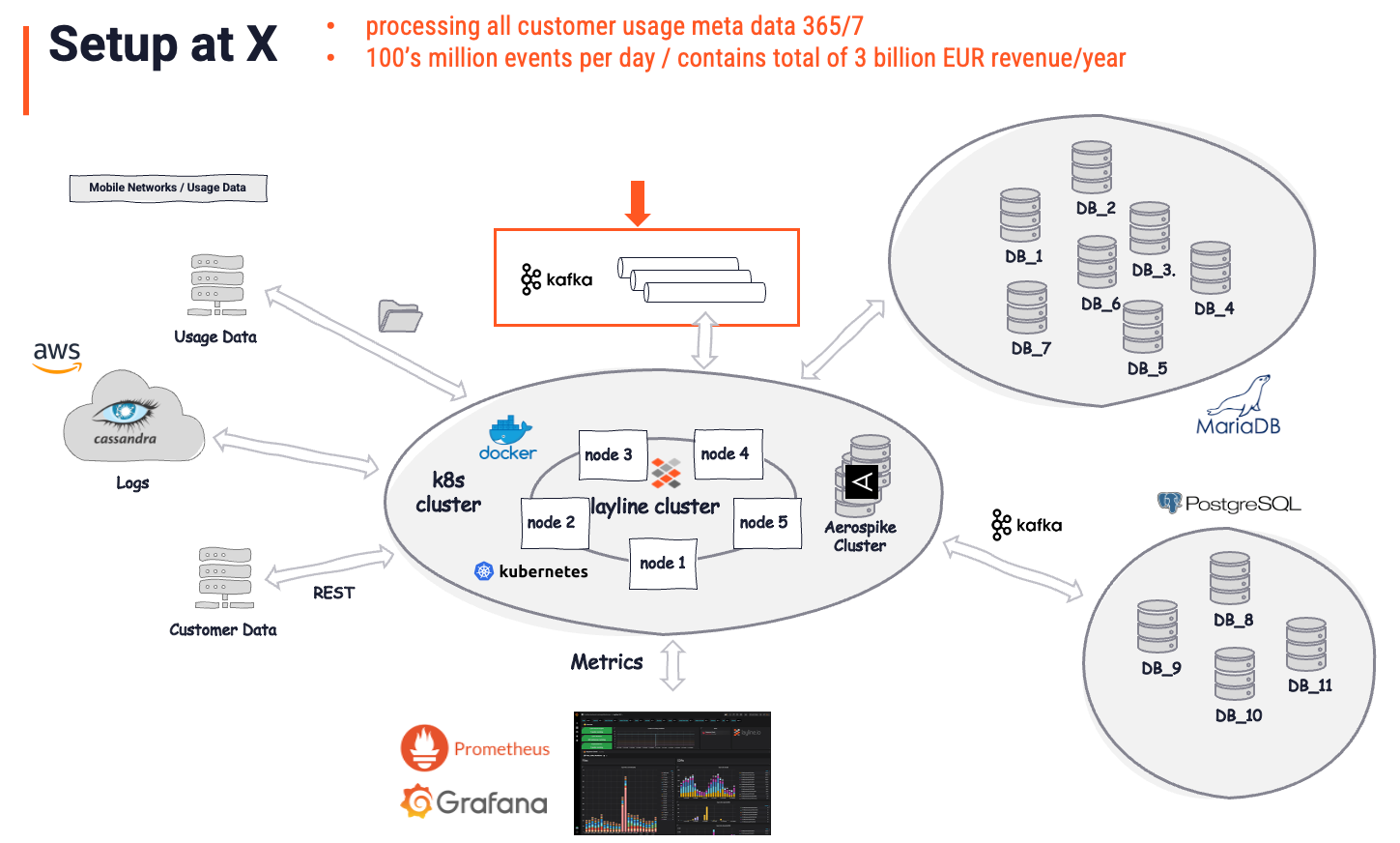
Das Gesamtbild wird als die "Lösung" betrachtet. Es ist wichtig zu verstehen, dass layline.io als die tatsächliche Lösung anerkannt wird, während Kafka nur ein weiterer (wichtiger) Speicher ist. Kafka war vor layline.io da. Es spielt eine vergleichsweise kleine Rolle (roter Pfeil und Kasten) in der Gesamtlösung, jedoch. Es dient als Zwischenspeicher, was genau das ist, was es per Definition ist. Alle intelligente Datenanalyse, Anreicherung, Filterung, Transformation, Routing, komplexe Geschäftslogik und vieles mehr wird von layline.io gehandhabt. Eine Aufgabe auf einem Niveau, das mit Kafka unmöglich zu erreichen wäre. Fragt man, welcher Teil davon Kafka zuzuschreiben ist, würde die Antwort des Kunden wahrscheinlich lauten: "5% der Gesamtlösung".
Fazit
Kafka wird weithin als Nachrichtenbus betrachtet, aber es geht eigentlich um Daten im Ruhezustand, die anderen Anwendungen ermöglichen, Daten in Bewegung zu bringen. In diesem Kontext ist die tatsächliche Anwendung aus Sicht eines Benutzers etwas, das mit Daten aus Kafka über eine Client-API gefüttert wird. layline.io hingegen bildet einen integralen Bestandteil der Logik Ihrer Anwendung, wenn es nicht die Anwendung selbst ist (siehe Beispiel). Sie können sich layline.io wie das Kreislaufsystem plus Logik vorstellen, während Kafka nur ein extern gut organisiertes Reservoir ist. Die Überschneidung zwischen Kafka und layline.io ist daher minimal.
Ein Kunde, der Kafka betreibt, wird nicht in Frage stellen, ob layline.io "zusätzlich zu Kafka" sinnvoll sein könnte. Ebenso würden wir die Verwendung von Kafka als Datenspeicher nicht in Frage stellen, sondern nur, ob dies der richtige Datenspeicher für den Zweck wäre. Kunden würden eher in Frage stellen, wie sie Probleme lösen (die Kafka nicht anspricht) mit layline.io. Sie könnten etwas Neues tun oder bestehende Prozesse (z.B. Microservices) ersetzen, die in der Vergangenheit in gewissem Umfang benutzerdefiniert programmiert wurden.
Anhang: Schneller Vergleich layline.io <> Kafka
Kein vollständiger Vergleich, aber es hilft:
| Aspekt | Kafka | layline.io |
|---|---|---|
| Typ | Nachrichtenwarteschlange | Parallelitätsplattform |
| Workflow-Unterstützung | Nicht wirklich. Nur ein Speicher. | Integrierter Teil der Lösung |
| Datenspeicher | Ja | Nein |
| Unterstützung von Datenformaten | Kein Verständnis von Datenformaten out-of-the-box. Nur im Kontext mit ksql einige begrenzte Unterstützung für Formate wie CSV, JSON, Avro, ProtoBuf. | Vollständiges Verständnis des Dateninhalts. Stark typisiert. Unterstützung für extrem komplexe Datenformate, wie ASCII und Binär, hierarchische Strukturen, ASN.1 usw. |
| Geschäftslogik | Keine Unterstützung | Volle Unterstützung. Dies ist ein wesentlicher Unterschied zwischen einem Speicher und einer Datenverarbeitungslösung. |
| Datenanreicherung | Nicht unterstützt. Keine Drittparteien können zur Datenanreicherung konsultiert werden. | Volle Unterstützung. |
| Echtzeit | Kafka ist ein Speicher. Dies kann nur so echtzeitfähig sein wie das, was die Daten aus dem Speicher (Puffer) liest. | Voll. So echtzeitfähig wie möglich. Keine Zwischenlagerung. Daten werden sofort verarbeitet und ausgegeben. |
| Benutzerdefinierte Metriken | Keine benutzerdefinierten Metriken, die spezifisch für Ihren Anwendungsfall sind | Jede Art von benutzerdefinierter Metrik (z.B. "4711 Kunden haben sich im letzten Zeitintervall für Dienst y angemeldet") |
| Leistung | Hoch | Hoch |
| Skalierbar | Ja | Ja |
| Resilient / HA | Ja | Ja |
| Persistent | Ja. Das ist der Zweck von Kafka. | Nein. Nicht der Zweck von layline.io, aber funktioniert hervorragend mit Persistenzschichten, wie Kafka. |
| UI-gesteuerte Konfiguration | Nein | Ja |
| Speicherintensität | Hoch | Niedrig |
| Hardware-Fußabdruck | Hoch | Niedrig |
| Open Source | Ja, für die Community Edition. Nein für die Confluent-Lösung (z.B. ksql) | Noch nicht. |
| Bereitgestelltes Cloud-Angebot | Ja, für Confluent | Noch nicht. |
- Lesen Sie mehr über layline.io hier.
- Kontaktieren Sie uns unter hello@layline.io.


