The traditional Microservices model on Kubernetes/Docker has some disadvantages which result in overly complex management and resource consumption. In this article we explain how layline.io embraces container and container orchestration technology, while helping to resolve the aforementioned challenges with a better approach.
Quick explainer: Kubernetes (K8S) & Docker
Containers
Programs running on Kubernetes are packaged into Containers. The advantage being that software and dependencies are packed together. One less thing to worry about and warranting the independence of the Container. There are tons of ready-made Containers downloadable from such portals as DockerHub, packaging up all sorts software.
You can in theory pack many programs into one Container, but the recommendation and industry standard is one Container = one Process. This makes everything more granular, and you can replace individual containers (and therefore processes) more easily that way.
Pods
Containers don't run on their own, but are packaged in yet another "container". This time they're called Pods. Pods - among other things - manage virtual resources such as network, memory, CPU etc. for the Containers running within them.
It's important to understand, that you don't assign CPU power to a Container, but to a Pod. Therefore, if you run more than one Container in the same Pod, they all have to share the resources available to the Pod. For the same reasons you should not put more than one program in a Container, you should not put more than one Container in a Pod, unless multiple Containers are required to serve the purpose of the Microservice.
Resource Issues when Scaling in Kubernetes
In Kubernetes the currency of scalability is Pods. To have more processing power, you fire up more Pods, also known as replication.
If you look at this design, a Pod itself is actually pretty static. If you want to adhere to utmost flexibility and be able to replace one program with another, then your Pod contains one Container, which in turn contains one program which will run as one process.
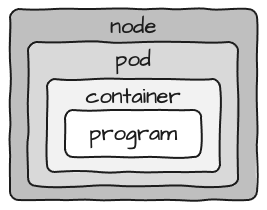
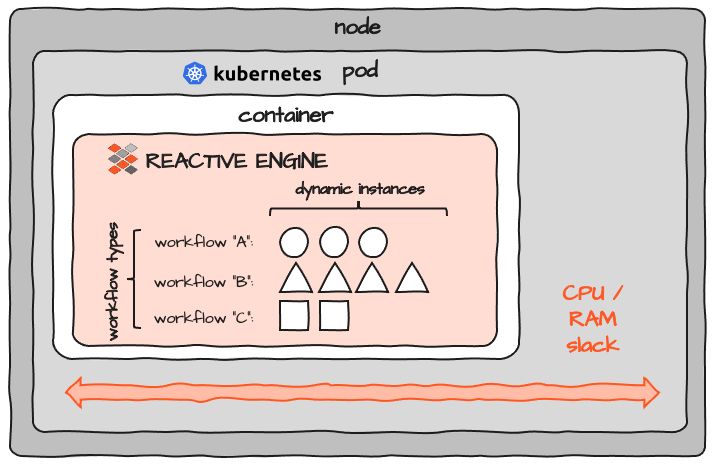
Considering that the actual resources required for the container are configured on Pod-level, the image looks more like this:
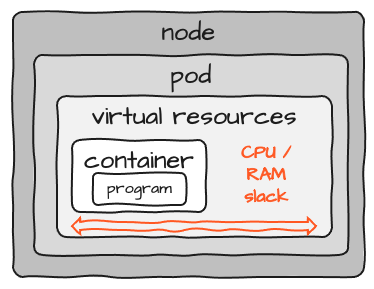
Check out the space marked as "slack". When you size the resources for a container, you have to account for some slack in CPU and memory. But because it's almost impossible to exactly determine the necessary resources for one program you end up having some reserve in every pod. If you run 100 of these, the slack adds up 100-fold. There is no resource-sharing between Pods. On top of this there is some overhead for each Pod and Node which gets added to the cluster. So, while overall the concept of K8S is great, it also adds considerable resource overhead overall.
Distribution of Containers within a Kubernetes Cluster
Pods are also the smallest denominator to distribute functionality within a Kubernetes Cluster. Let's say you have Microservices A, B and C and you want to distribute them unevenly within a Cluster, you either have individual Pods which each contain either A, B or C, or you have to have a number of Pods to make up all permutations of Pods containing containers A, B and C (e.g. a Pod with A and B, a Pod with A and C, etc.). That's a lot of Pods to manage and can quickly become overwhelming and inefficient.
Distribution of Pods is then a major configuration challenge within Kubernetes and/or your CI/CD tool of choice. Add to this the management of automated scaling and load balancing between Nodes and you end up having a major setup and monitoring headache.
How layline.io deals with scalability, resources, and distribution in a Kubernetes Cluster
Reactive Engine
layline.io introduces the Reactive Engine. The Engine serves as an execution context for Workflows which can be configured to run within a Reactive Engine. Workflows are comparable to Microservices in that they fulfil specific data processing tasks ranging from ingestion, analysis and enrichment as well as responding to query requests etc. Workflows are configured using the web-based Configuration Center:
Multiple Reactive Engines form a Reactive Cluster of their own. When setting up layline.io in a Cluster environment like Kubernetes, you actually set up a number of Nodes which then run Reactive Engines encapsulated in containers:
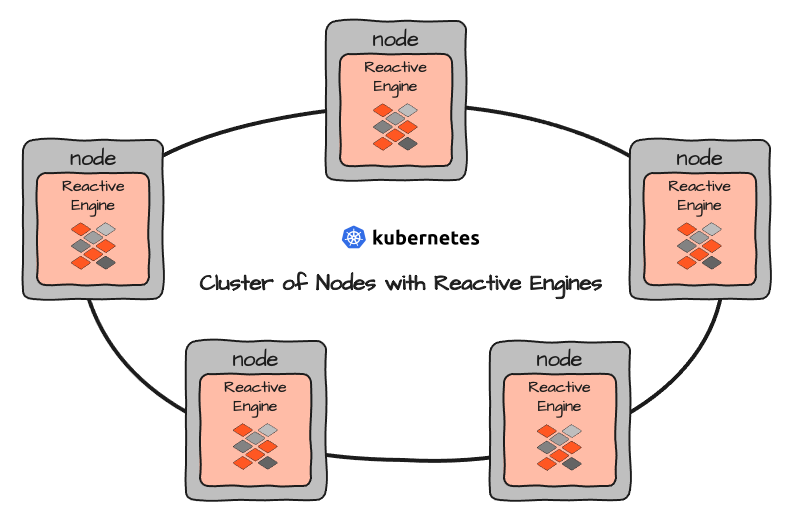
All Reactive Engines are created equal. They serve as execution contexts for Workflows. Simplified, you may view Workflows as equivalent to Microservices. The difference being that Workflows are configured and therefore a Configuration, and not programmed object code like with typical Microservices.
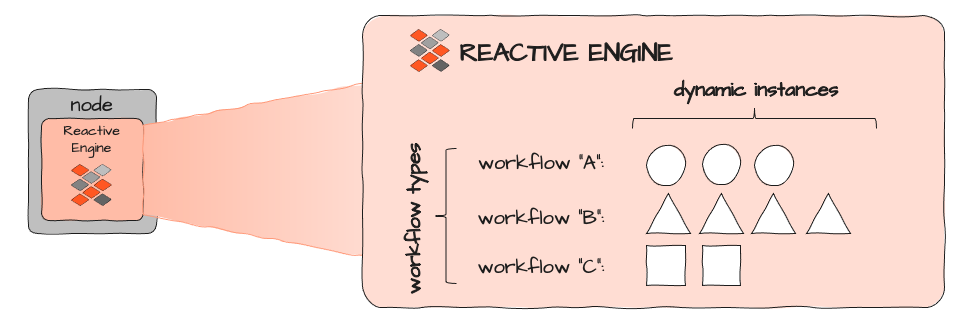
Each Reactive Engine can run different Workflows (A, B and C above). Each Workflow can be dynamically instantiated multiple times. The number of instances is limited by how many resources a single Workflow instance consumes and how much resource is available and assigned to the execution context in which the Reactive Engine itself runs. In a Kubernetes Cluster this would be the image of a respective Pod:
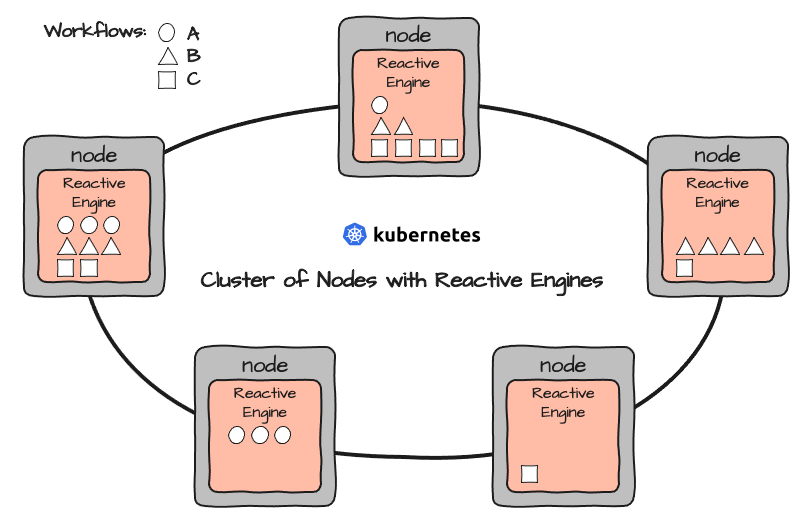
Any Reactive Engine can run any Workflow. Workflows are deployed either directly via the Configuration Center or via your preferred CI/CD tool (e.g. Bamboo et al).
This could result in a setup like this:
Elastic scaling
The number of instances of each Workflow can be scaled up and down dynamically, either by manual intervention from the Config Center or command line, or automatically based on data pressure.
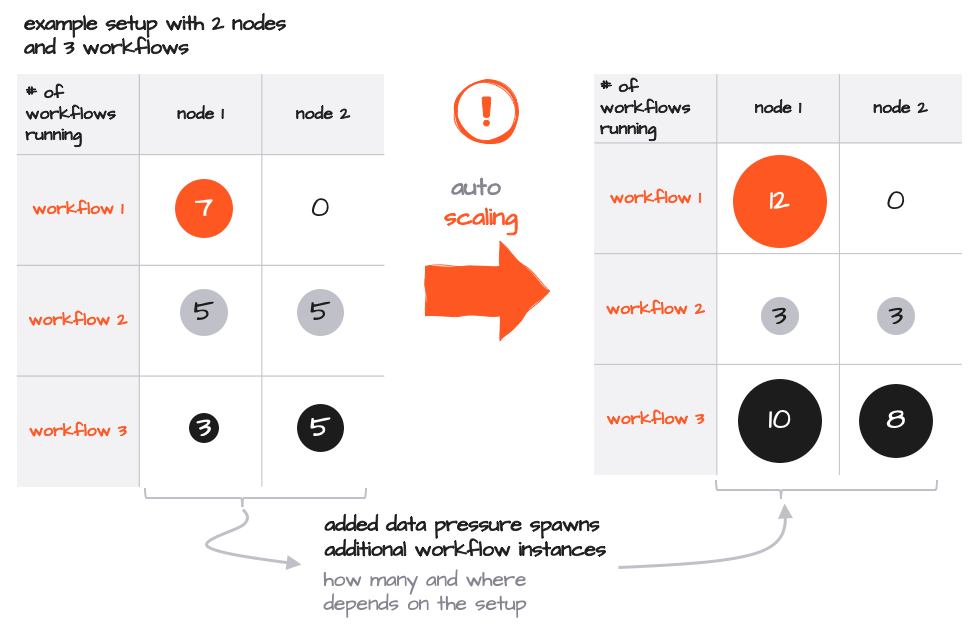
While the standard Kubernetes path to scale by firing up additional Pods remains valid, you can simply fire up additional Workflow instances within a Pod. Note that no additional Pods would be activated in this example, given that each Pod contains enough breathing room to scale. Because everything is scaled within a Reactive Engine, this process is extremely fast and efficient, requiring only few additional resources per instance and no intervention on Kubernetes level.
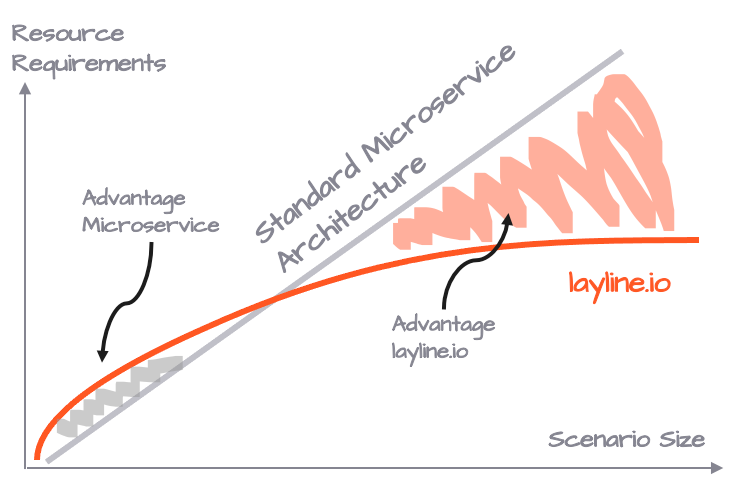
Advantage Resources
It makes sense to think, that one will require respective CPU power and RAM regardless of whether you distribute 30 Pods with the same Microservice on three Nodes, or three Reactive Engines with 10 instances of the same Workflow each on three Nodes. But that is not the case.
Depending on the characteristic of the Microservice which is replaced by a Workflow, you typically save between 25-50% of resources compared to the traditional way of deploying Microservices. It's also true, however, that a Reactive Engine running one Workflow instance only, requires a more resources than a custom Microservice which is only run one time.
It's a tradeoff between flexibility and resource requirements, which flips quickly to the favor of the layline.io model with the size of your processing scenario.
Advantage Setup
Setting up layline.io in a Kubernetes/Docker cluster means to deploy the same container on every Node. Each container runs a Reactive Engine and there are no other container types with different content. Just one.
For a Reactive Engine to know what Workflows to execute, a configuration is injected at runtime. Because all Reactive Engines form a Reactive Cluster of their own, it is enough to inject the Configuration into one Reactive Engine. It is then automatically distributed to all other Engines in the Cluster. Again, this can all be triggered manually or automatically through CI/CD tools.
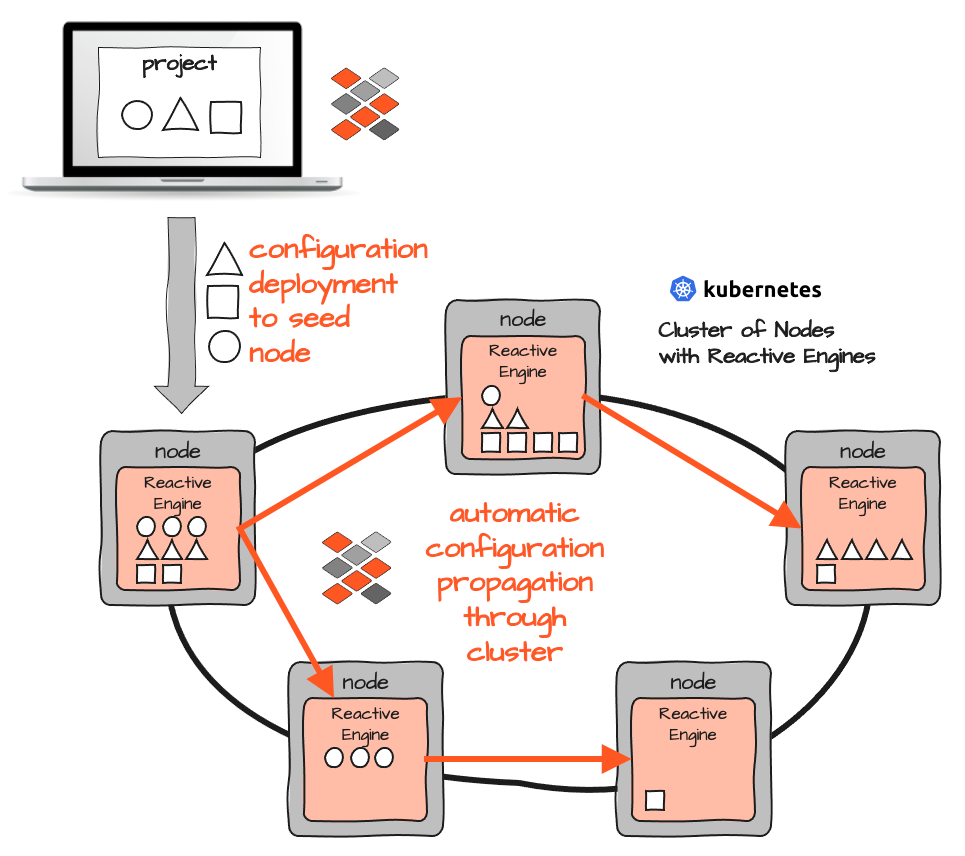
So unlike the pure Kubernetes/Docker concept, there is no hassle with different Pods containing different containers which need to be re-built on every change and then managed from a deployment point-of-view. Contrary to Kubernetes you don't have to think about where to run which Pod/Container upfront, or how to shuffle Pods around in case you want to rearrange them. In layline.io you can simply activate a preloaded Workflow in one or more Reactive Engines, or deploy a new Workflow Configuration to the Cluster in order to bring this Workflow online.
Summary
| Aspect | Kubernetes/Docker | layline.io |
|---|---|---|
| Scaling | Scale via Pods | Scale within Pod via Workflow instances |
| Scaling reaction time | medium | fast |
| Resource consumption | Better with small scenarios | Better with medium to large scenarios |
| Setup | Many different Pods and Containers | Configurations injected into Reactive Engine |
Kubernetes is great. Period. But there are downsides in complexity and operation.
layline.io provides a much better and leaner way to not only create and manage Services, but also to manage and distribute them in a Cluster environment. For medium to large scenarios, there is also a significant upside in regard to resource management and consumption.
You can download and use layline.io for free here. If you have any questions about layline.io please don't hesitate to contact us!
Resources
- Download layline.io
- Fixing what's wrong with Microservices
- Read more about layline.io here.
- Contact us at hello@layline.io.


