Seit einigen Jahren sind Microservices und serviceorientierte Architekturen der letzte Schrei. Kurz darauf half die Containerisierung, die installierte Plattform von der bereitgestellten Plattform zu abstrahieren, indem das Betriebssystem und die abhängigen Bibliotheken zusammen mit der eigentlichen Anwendung verpackt wurden.
Doch wo Licht ist, da ist auch Schatten. Die Arbeit mit und die Nutzung von Microservices bringt ihre eigenen Herausforderungen mit sich. Wir haben eine ziemlich umfassende Liste hier gefunden. Werfen wir einen Blick auf einige der wichtigsten Vor- und Nachteile:
Hauptprobleme bei der Entwicklung, Bereitstellung und dem Betrieb von Microservices
Die Vorteile
- Atomarität: Autonome Services können individuell in Bezug auf Entwicklung und Ausführung behandelt werden (abgesehen von Schnittstellen).
- Resilienz: Einzelne Services sind in der Regel nicht beeinträchtigt, wenn es zu Ausfällen in anderen Services kommt, was zu einer besseren Resilienz führt.
- Skalierbarkeit: Einzelne Services können elastisch und bedarfsgerecht skaliert werden.
Die Nachteile
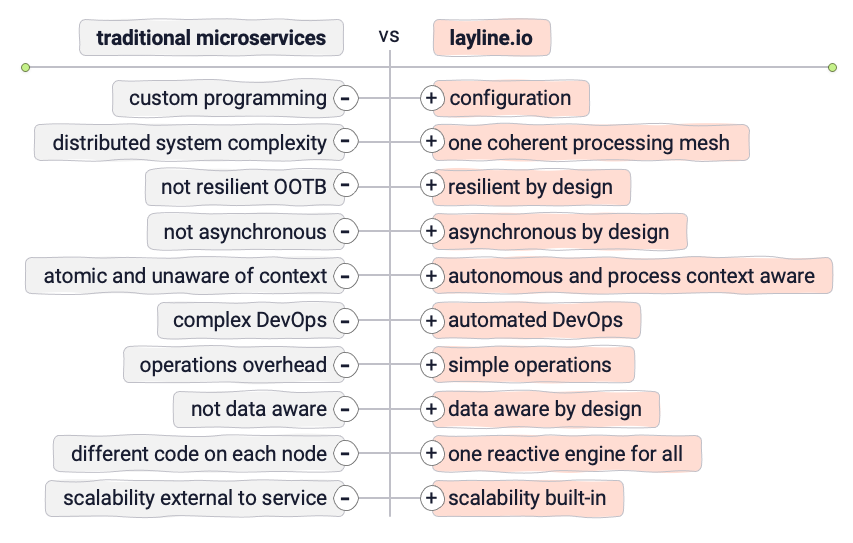
- Lose Kopplung: Microservices wissen in der Regel nichts voneinander und über ihren breiteren Ausführungskontext. Sie sind von Natur aus atomar. Die Kommunikation zwischen ihnen bringt einen Overhead mit sich und ist nicht standardisiert.
- Überwachung: Eine umfassende Überwachung einer Vielzahl von Microservices ist extrem schwierig und fast unmöglich. Einzelne Probleme über verschiedene Services hinweg klar zu identifizieren, kann aufgrund unterschiedlicher Log-Typen, die überall verstreut sind, unklarer Abhängigkeiten zwischen Services und dienstübergreifender Transaktionen äußerst schwierig sein.
- Debugging: Fehler, die in einer komplexen verteilten Microservices-Architektur auftreten, können extrem zeitaufwändig und teuer zu verfolgen sein. Es gibt kein übergreifendes Überwachungssystem, sondern nur einzelne Logs und Stack-Traces, die untersucht werden müssen, um sicher festzustellen, was die Ursache des Fehlers war.
- Sicherheit: Ein integrales Merkmal von Microservices sind ihre Schnittstellen/APIs. Besonders in verteilten Umgebungen erfordert jede von ihnen besondere Sorgfalt in Bezug auf Sicherheit. Es ist leicht, in solch komplexen Framework-Umgebungen den Überblick und die Kontrolle zu verlieren.
- Resilienz: Mit vielen verschiedenen Arten von Microservices, die möglicherweise von unterschiedlichen Teams entwickelt werden, wird es exponentiell schwieriger, ordnungsgemäße Failover-Mechanismen sicherzustellen, damit das gesamte System entsprechend reagieren kann, wenn einer oder mehrere Microservices ausfallen.
- Bereitstellung: Die Bereitstellung einzelner Microservices in einer komplexen Umgebung ohne Ausfallzeiten ist schwer zu orchestrieren und manchmal unmöglich, ohne alles neu zu starten.
- Kommunikation: Es muss eine Form der Standardisierung der Kommunikation zwischen Microservices geben, sei es in Bezug auf Serialisierung, Sicherheit, Anforderungsoptionen, Fehlerbehandlung und die Liste der erwarteten Antworten. Eine Art Top-Level-Design-Orchestrierung ist sehr notwendig, sonst führt dies zu Kommunikationsproblemen und Latenzproblemen.
Dies sind nur einige der Herausforderungen. Es gibt viele weitere Herausforderungen in Bezug auf Wartung, Netzwerke, Teammanagement usw., wie Sie sich vorstellen können.
Lösung: MicroConfigurations statt MicroServices
Während die Idee von Microservices großartig ist, kann sie sehr schnell sehr unangenehm werden. Natürlich stellt sich die Frage, ob es einen Weg gibt, die guten Teile einer Microservices-Architektur beizubehalten und die schlechten Teile zu vermeiden.
Micro-Configurations könnten hier helfen. Wir definieren Micro-Configuration (oder MicroConfig) als eine Trennung zwischen der eigentlichen Service-Logik (der Konfiguration) und der Service-Ausführung (der Engine).
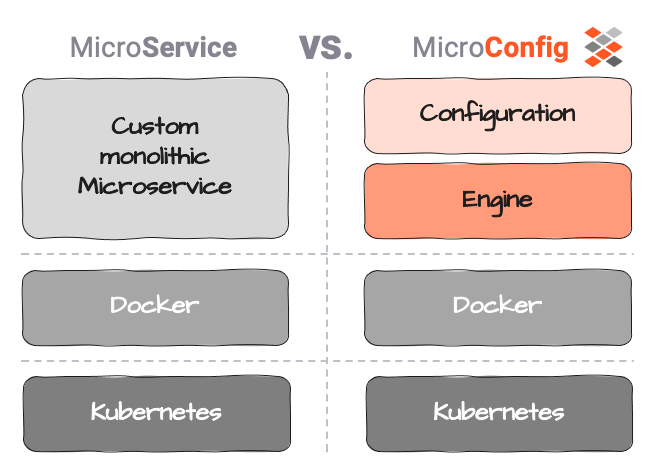
Konfiguration in diesem Kontext soll sich rein auf die Geschäftslogik beschränken, d. h. was mit den Daten zu tun ist, welche Aktion ausgelöst werden soll usw.
Ausführung umfasst alles, was die Ausführung der Konfiguration ermöglicht:
- Ausführung der Logik (Konfiguration),
- zentrale und standardisierte Protokollierung von Aktivitäten und Problemen,
- Orchestrierung der Ausführung über Services hinweg,
- Berichterstattung über Metriken zur Überwachung,
- Unterstützung beim Debugging,
- standardisierte Kommunikation über Service-Grenzen hinweg
- und vieles mehr.
Dies ist im Allgemeinen kein neues Konzept in der Welt der Technik.
Beispiel: Eine typische Datenbank unterscheidet zwischen Datenbankstruktur (Tabellen, Indizes, Einschränkungen usw.) und Datenbank-Engine (Interpretation, Speicherung, Bereitstellung). Während die Engine für jeden Benutzer gleich ist, ist die Struktur einzigartig. Dennoch würde niemand auf die Idee kommen, Tabellen direkt in die Engine zu programmieren. Die Trennung von Konfiguration und Engine ist das, was die Datenbank überhaupt erst generisch macht, wobei jede von ihnen einen speziellen Zweck und eine spezielle Stärke hat.
layline.io ist ähnlich, da Services als sogenannte Workflow Configurations implementiert werden und nicht als monolithische ausführbare Dateien. Eine unbegrenzte Anzahl verschiedener Workflows kann definiert werden. Workflows werden von Reactive Engines ausgeführt, die wiederum auf Nodes laufen. Ein Kubernetes-Pod oder ein Raspberry Pi wäre beispielsweise ein Node. Zwei oder mehr Engines bilden einen logischen Reactive Cluster. Das Setup hängt ausschließlich von Ihren Anforderungen und Ihrer Umgebung ab. Eine theoretisch unbegrenzte Anzahl von Engines (auf Nodes) kann in einem geografisch verteilten logischen Cluster gestartet und ausgeführt werden. Edge-Computing ist hier einer der interessanten Anwendungsfälle. Da alles auf dem gleichen Typ von Reactive Engine läuft, müssen Sie sich keine Gedanken darüber machen, was auf physischer Ebene bereitgestellt werden soll.
Die Bereitstellung von Workflow Configurations erfolgt automatisch, indem eine Konfiguration auf einem Node im Reactive Cluster veröffentlicht wird, und der Cluster propagiert die Konfiguration dann automatisch im gesamten Cluster. Dies erspart Ihnen die Sorge um die physische Bereitstellung von Microservices auf Pods oder tatsächlichen physischen Nodes. Neue Nodes, die dem Cluster hinzugefügt werden, erhalten automatisch die Konfigurationsdaten und können sofort mit der Verarbeitung beginnen.
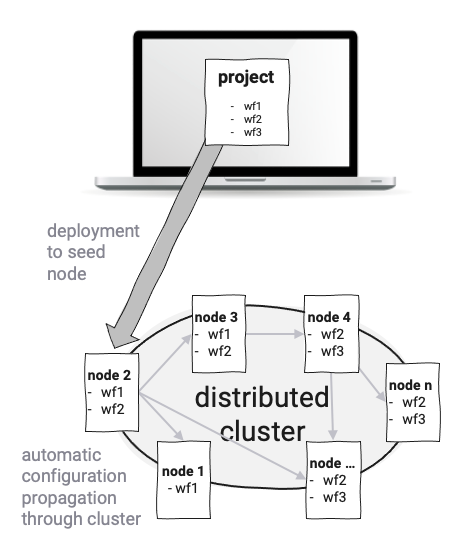
Resilienz, Skalierbarkeit und Failover sind in layline.io integriert. Eine kontinuierliche Cluster-Überwachung stellt sicher, dass die konfigurierten Skalierungen der Workflow-Instanzen eingehalten werden, und balanciert die Arbeitslast der Workflows im Falle eines Node-Ausfalls automatisch neu aus.
Zentrales Monitoring und Logging stellt sicher, dass Probleme innerhalb des Reactive Clusters sofort erkannt werden. Lösungen können in der Regel über die Benutzeroberfläche bereitgestellt werden, ohne dass ein Eingriff auf physischer Ebene erforderlich ist.
Alles innerhalb der layline.io-Plattform ist auf Ausführungsebene standardisiert, aber auf Konfigurationsebene offen. Dies ermöglicht es Ihnen, das einzurichten, was Sie benötigen, ohne sich um die schwierigen Teile kümmern zu müssen, wie die Infrastruktur tatsächlich funktioniert.
Während das Konzept eines Frameworks möglicherweise nicht das ist, was der eingefleischte "Nur-Low-Level"-Entwickler gerne akzeptiert, ergibt es technisch und geschäftlich viel Sinn. Sie würden Ihre eigene Datenbank auch nicht selbst programmieren, oder?
Ressourcen
- Top 10 Challenges of Using Microservices for Managing Distributed Systems
- Here's Why Microservices Desperately Need Service Mesh Anomaly Detection
- Lesen Sie mehr über layline.io hier.
- Kontaktieren Sie uns unter hello@layline.io.