From Data Chaos
to Real-Time Insights
Build reactive data pipelines with a visual workflow designer. No infrastructure code, no vendor lock-in, just fast, reliable data processing at scale.
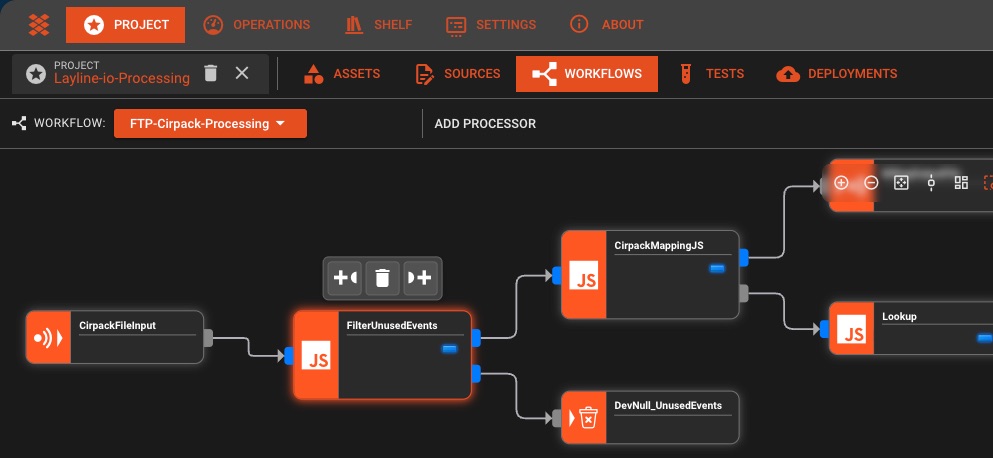
The Data Engineering Reality Check
Building data pipelines should not require a PhD in distributed systems. Yet most data engineers spend 80% of their time wrestling with infrastructure instead of solving business problems.
Infrastructure Complexity
Managing Kafka clusters, Kubernetes deployments, and custom monitoring across multiple environments. Your team needs a DevOps engineer just to keep the lights on.
Vendor Lock-in Nightmares
Cloud-specific services that work great in demos but trap you in proprietary ecosystems. Migrating becomes a six-figure project.
Time to Production
Weeks or months to deploy a simple transformation pipeline. By the time it's live, business requirements have changed twice.
Debugging Black Boxes
When pipelines fail at 3 AM, you're diving into log aggregation systems across distributed services. Finding root causes is like digital archaeology.
Scaling Bottlenecks
What handles 1M events handles 10M events very differently. Rewriting your entire pipeline architecture every time you grow.
Team Collaboration
Business analysts can't understand your Kafka configurations. Data scientists can't deploy their models. Everyone works in silos.
Sound Familiar?
You became a data engineer to build intelligence into business processes, not to become a full-time site reliability engineer. There's a better way.
See The SolutionVisual Workflows.
Real Results.
Build data pipelines by connecting blocks, not writing YAML. Watch your data flow in real-time with built-in monitoring and error handling.
Drag and Drop Designer
Visual pipeline creation with configurable processors. No coding required, just connect the dots.
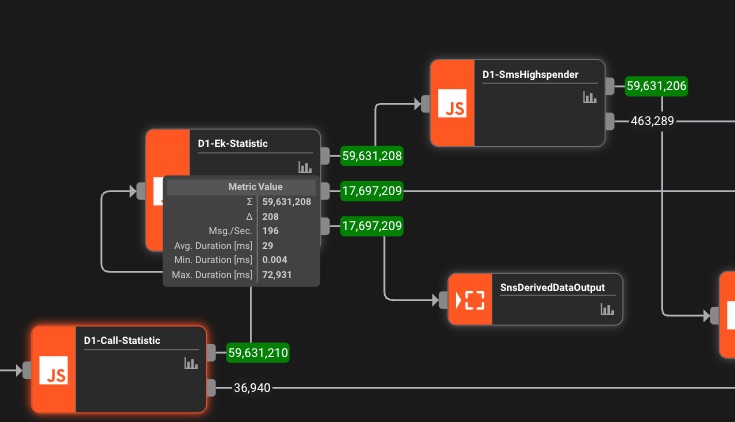
Real-Time Monitoring
Live metrics, error tracking, and performance insights. See exactly what's happening in your pipeline.
Zero Infrastructure
Runs on your infrastructure or ours. Auto-scaling, high availability, and maintenance-free operation.
The Data Engineering
Revolution
Stop fighting infrastructure. Start building solutions that matter.
Deploy in Minutes
Skip months of infrastructure setup. Our visual designer lets you build production pipelines faster than writing a Kafka consumer.
Sleep at Night
Built-in monitoring, automatic retries, and dead letter handling. Your pipelines self-heal while you focus on business logic.
Scale Effortlessly
From prototype to production scale. Handle traffic spikes without rewriting code or provisioning servers.
The Bottom Line
Stop wrestling with infrastructure. Focus on what actually moves your business forward.
"Finally, a data platform that just works."

See layline.io
in Action
Real solutions from real data engineering teams across industries
Real-Time Analytics Dashboard
E-commerce company processes 50,000+ events per second from web clicks, purchases, and inventory changes to power live dashboards and personalization engines.

Questions from Data Engineers
Common questions about implementing real-time data processing with layline.io.
Most data engineers have layline.io processing their first data streams within 10 minutes. Our visual pipeline builder and pre-built connectors eliminate weeks of custom development work.
layline.io connects to databases, REST APIs, message queues, file systems, streaming platforms, and custom protocols. It handles JSON, XML, ASCII, Binary, ASN.1, HTTP, and more through visual configuration.
layline.io is built for enterprise scale, processing millions of events per second with horizontal scaling. Our distributed architecture ensures consistent performance even during traffic spikes, with built-in backpressure handling.
Yes. Deploy on-premise, in any cloud, or hybrid. layline.io works with your existing databases, data lakes, warehouses, and analytics tools without requiring architectural changes.
We provide technical support, documentation, video tutorials, and onboarding guidance. Our team helps data engineering teams optimize pipelines for performance and reliability.
layline.io pricing scales with your usage. Pay only for what you process, with predictable pricing that grows with your business. Enterprise plans include dedicated support and custom SLAs.
Build Your First Pipeline in Minutes
Download layline.io for free and start building reactive data pipelines without the complexity. No credit card required.
Resources for Data Engineers
Case studies, technical guides, and best practices for building data pipelines

The AI Productivity Gap: Why the Numbers Don't Add Up
Every enterprise dashboard claims AI is transforming the business. The actual productivity numbers tell a very different story — and understanding why matters for every team making AI investment decisions.

The AI Data Engineer: What Actually Changed (And What Didn't)
Every competitor blog is publishing 'AI is changing data engineering.' It's all breathless and vague. Here's the honest inventory — what LLM tooling genuinely helps with, what it still can't touch, and why the '80% automation' claims don't survive contact with production.

Data Contracts Are the API Versioning Your Data Pipeline Needs
Schema drift keeps breaking pipelines because we're monitoring for changes instead of enforcing contracts. Here's why data contracts are the missing layer between your producers and consumers.