
Von Andrew Tan
Dashboards, die lügen
Viele Unternehmen geben über sechsstellige Beträge für Datenherkunfts-Tools aus. Ihre Demos sind beeindruckend: weitläufige Visualisierungen, die jede Tabelle, Pipeline und Abhängigkeit in einem Data Warehouse zeigen. Farben zeigen die Frische an. Pfeile zeigen den Datenfluss. Es sieht aus wie der Kontrollraum eines Kernkraftwerks.
All das ist großartig und schick, aber eine der unbeantworteten Fragen ist, was passiert, wenn Tabelle X schlechte Daten hat.
Man kann in den Diagrammen herumklicken, zoomen und schwenken, die Tabelle lokalisieren, die nachgelagerten Verbraucher und Transformationen inspizieren, in die sie eingeflossen ist. Und dann kann man feststellen, dass zwölf Dashboards 'Kundenadresse' verwenden.
Die eigentliche Frage ist jedoch, welche Geschäftsprozesse ausfallen. Stoppt der Versand? Gehen Rechnungen an den falschen Ort? Scheitern Compliance-Berichte? Sie verstehen, worauf ich hinaus will.
Das Dashboard weiß stattdessen, dass Daten von A nach B geflossen sind, aber es hat keine Ahnung, wofür B tatsächlich verwendet wurde.
Herkunftstheater
Das nenne ich Herkunftstheater: die Praxis, beeindruckend aussehende Datenflussdiagramme zu erstellen, die Compliance-Checklisten und Anbieter-Demos zufriedenstellen, aber nicht wirklich helfen, wenn etwas schiefgeht.
Die Tool-Anbieter haben für das falsche Ziel optimiert. Sie verkaufen Visualisierungen. Was Datenteams brauchen, ist Kontext: die Fähigkeit, ein Datenqualitätsproblem in weniger als 60 Sekunden auf seine geschäftlichen Auswirkungen zurückzuführen.
Dieses Muster sieht man in vielen Unternehmen. Sie implementieren Herkunftstools mit großem Tamtam. Die Diagramme werden auf Büro-TVs angezeigt (cool), und das Data-Governance-Team schreibt Dokumentationen über die Dokumentation. Dann, sechs Monate später, ändert ein vorgelagertes System einen Spaltennamen und das Herkunftsdiagramm leuchtet wie ein Weihnachtsbaum, während die tatsächlichen geschäftlichen Auswirkungen ein Rätsel bleiben.
Das Team endet damit, das zu tun, was sie ohne das Tool getan hätten: Durch Slack blättern, mit Stakeholdern sprechen, manuell nachverfolgen, welche Berichte für welche Entscheidungen wichtig sind.
Die Lücke im Geschäftskontext
Hier ist das grundlegende Problem: Technische Herkunft und geschäftliche Herkunft sind unterschiedliche Dinge, und die meisten Tools machen nur das erste.
Technische Herkunft beantwortet: Woher kommen diese Daten und wohin gehen sie?
Geschäftliche Herkunft beantwortet: Welche Entscheidungen hängen von diesen Daten ab, und was passiert, wenn sie falsch sind?
Die Lücke dazwischen ist der Ort, an dem Datenkatastrophen passieren. Eine Pipeline kann aus technischer Sicht zu 100 % korrekt sein: alle Jobs grün, alle Tests bestanden, während sie ein Ergebnis produziert, das für das Geschäft katastrophal falsch ist.
Angenommen, Sie sind ein Fintech-Unternehmen und Ihr Kreditgenehmigungsmodell ist technisch perfekt. Die Herkunft zeigt saubere Daten von der Anwendung über die Merkmalsentwicklung bis zur Modellbewertung. Was die Herkunft nicht erfasst, ist, dass eine kürzliche Schemaänderung zwei ähnlich benannte Felder, "Jahreseinkommen" und "Monatseinkommen", vertauscht hat, auf eine Weise, die die Validierungsregeln der Pipeline nicht erfasst haben.
Das Modell behandelt nun Monatseinkommen als Jahreseinkommen. Genehmigungsschwellen, die $60.000/Jahr erfordern sollten, werden bei $5.000/Monat ausgelöst. Das Herkunftsdiagramm zeigt grüne Pfeile. Das Geschäftsergebnis ist ein Monat schlechter Kredite, die sechs Monate zur Aufarbeitung benötigen.
Wie nützliche Herkunft tatsächlich aussieht
Die Teams, die Herkunft gut machen, haben eines gemeinsam: Sie behandeln es als eine geschäftliche Mapping-Übung, nicht als eine technische Dokumentationsaufgabe.
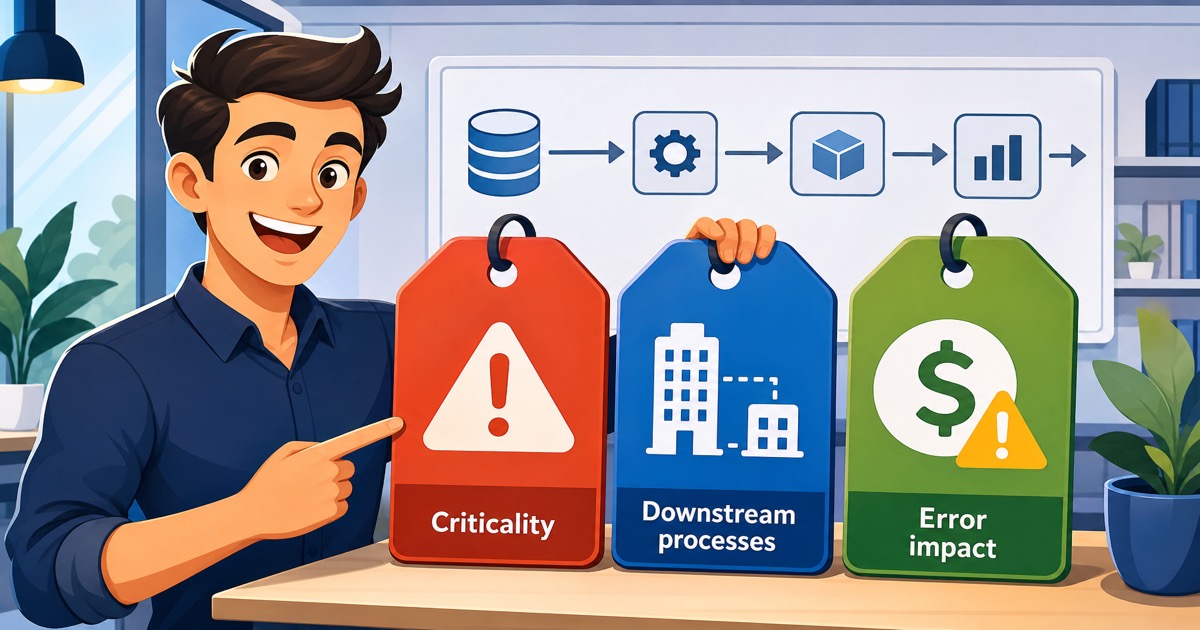
Sie müssen einen anderen Ansatz wählen: Jeder Datenbestand in Ihrem Warehouse hat drei Tags:
- Kritikalität: Wird dies für regulatorische Berichterstattung, operative Entscheidungen oder nur für Analysen verwendet?
- Nachgelagerte Prozesse: Welche Geschäftsbereiche hängen davon ab? (Nicht welche Tabellen, sondern welche Funktionen: Abrechnung, klinische Entscheidungen, Compliance)
- Fehlerauswirkung: Was passiert, wenn diese Daten falsch sind? (Verzögerung, finanzieller Verlust, regulatorisches Problem, Patientensicherheit)
Das resultierende Herkunftstool ist technisch einfach: nur ein grundlegender Abhängigkeits-Tracker. Aber kombiniert mit diesen drei Tags sagt es genau das, was Sie wissen müssen, wenn etwas schiefgeht.
Wenn Ihre Tabelle zur Schadenbearbeitung ein Datenqualitätsproblem hat, müssen Sie nicht durch fünfzehn nachgelagerte Tabellen nachverfolgen. Sie schauen sich die Tags an, sehen "Kritikalität: Regulatorisch, Nachgelagert: Monatliche CMS-Einreichung, Fehlerauswirkung: $2M Strafe bei Verspätung," und wussten sofort, dass Sie an den CFO eskalieren und den manuellen Einreichungs-Backup-Prozess einleiten müssen.
Die gesamte Vorfallreaktion dauert Minuten. Keine Diagrammnavigation erforderlich.
Warum wir das Falsche bauen
Warum kaufen Teams weiterhin visualisierungsintensive Herkunftstools, die das eigentliche Problem nicht lösen?
Ein Teil davon ist Beschaffungstheater. Die Person, die das Tool kauft, ist oft nicht die Person, die den Vorfall um 2 Uhr morgens debuggt. Sie kaufen etwas, das für das Compliance-Audit oder die Vorstandspräsentation gründlich aussieht. Schöne Diagramme setzen Häkchen. Geschäftskontext-Mapping erfordert organisatorische Arbeit, die sich nicht gut fotografieren lässt.
Ein Teil davon ist die Art und Weise, wie diese Tools verkauft werden. Anbieter demonstrieren mit sauberen, synthetischen Datenumgebungen, in denen die Herkunft offensichtlich ist. Echte Unternehmensdatenumgebungen sind super chaotisch: Jahrzehnte alte Legacy-Systeme, undokumentierte Transformationen, Stammeswissen, das nie aufgeschrieben wurde. Geschäftskontext-Mapping erfordert Gespräche mit Menschen, nicht nur das Scannen von Code. Es skaliert nicht so sauber wie automatisierte technische Entdeckung.
Und ein Teil davon ist, dass technische Herkunft einfacher zu erstellen ist. Sie können Abfrageprotokolle scannen, SQL parsen, DAGs inspizieren. Geschäftskontext erfordert Interviews, Dokumentation, laufende Wartung, da sich Prozesse ändern. Es ist organisatorische Arbeit, die als technische Arbeit getarnt ist.
Wie Sie Ihre Herkunft reparieren
Wenn Sie bereits in ein Herkunftstool investiert haben (und die meisten Unternehmen sind es zu diesem Zeitpunkt), müssen Sie es nicht herausreißen. Sie müssen ihm Geschäftskontext hinzufügen.
Beginnen Sie mit Ihrer Vorfallhistorie. Schauen Sie sich die letzten fünf Datenqualitätsvorfälle an, die echte geschäftliche Auswirkungen hatten. Für jeden identifizieren Sie:
- Welche Daten waren falsch
- Welcher Geschäftsprozess brach zusammen
- Wer musste es wissen
- Wie lange es dauerte, das herauszufinden
Jetzt schauen Sie sich Ihr Herkunftstool an. Hilft es bei einer dieser Fragen? Wenn nicht, haben Sie Ihre Verbesserungsliste.
Markieren Sie kritische Assets manuell. Versuchen Sie nicht, alles zu markieren. Beginnen Sie mit Ihren Top-20-Daten-Assets nach Geschäftsauswirkung. Dokumentieren Sie für jedes: welche Entscheidungen es speist, wer diese Entscheidungen trifft und was passiert, wenn die Daten schlecht sind.
Das dauert Zeit: vielleicht 30 Minuten pro Asset; vielleicht mehr. Aber es verwandelt Ihre Herkunft von einem hübschen Diagramm in ein operatives Tool.
Bauen Sie geschäftsbewusste Alarme. Die meisten Datenqualitätsalarme sind technisch. "Dieser Job ist fehlgeschlagen" oder "diese Spalte hat Nullwerte." Fügen Sie geschäftsbewusste Alarme hinzu: "Die tägliche Umsatzübersicht hat verdächtige Werte, die das CEO-Dashboard um 8 Uhr morgens speisen."
Der Alarm sollte nicht nur enthalten, was falsch ist, sondern auch, was davon abhängt und wer es wissen muss.
Üben Sie die Vorfallreaktion. Führen Sie eine Tischübung durch. Simulieren Sie ein Datenqualitätsproblem in einem kritischen vorgelagerten System. Messen Sie, wie lange es dauert, um zu beantworten: welche Geschäftsentscheidungen betroffen sind, wer benachrichtigt werden muss und welche Milderungsoptionen es gibt.
Wenn es länger als fünf Minuten dauert, benötigt Ihre Herkunft mehr Geschäftskontext.
Das Produkt, das ich mir wünsche
Ich habe einige der Herkunftstools auf dem Markt betrachtet. Sie sind alle Variationen desselben Themas: Scannen Sie Ihre Infrastruktur, erstellen Sie ein Diagramm, zeigen Sie Ihnen hübsche Visualisierungen.
Was ich möchte, ist etwas anderes. Ich möchte ein Tool, das mit Geschäftsprozessen beginnt und rückwärts arbeitet. Kartieren Sie zuerst die Entscheidungen, dann verfolgen Sie die Daten, die sie speisen. Wenn etwas schiefgeht, sagen Sie mir, welche Entscheidungen gefährdet sind, nicht nur, welche Tabellen betroffen sind.
Aber Sie brauchen keine neue Plattform, um bessere Herkunft zu erhalten. Sie müssen aufhören, Herkunft als technisches Problem zu behandeln, und anfangen, es als organisatorisches Problem zu betrachten. Das Diagramm ist nicht das Produkt. Der Geschäftskontext ist es.
Der Test für Ihr Herkunftstool
Hier ist ein einfacher Test. Wählen Sie ein kritisches Datenasset in Ihrem System: etwas, das schmerzhaft wäre, wenn es falsch wäre. Beantworten Sie nun diese Fragen, ohne den Code anzusehen:
- Welche Geschäftsentscheidungen hängen von diesen Daten ab?
- Wer trifft diese Entscheidungen und wann?
- Was kostet es, wenn man falsch liegt?
- Wer muss informiert werden, wenn es ein Qualitätsproblem gibt?
Wenn Sie diese Fragen nicht in 60 Sekunden beantworten können, erfüllt Ihr Herkunftstool nicht seine Aufgabe: egal wie schön das Diagramm aussieht.
Das Ziel ist nicht perfekte Beobachtbarkeit. Es ist nutzbarer Kontext. Und das ist schwieriger zu bauen, aber unendlich wertvoller.

Andrew Tan ist ein Serienunternehmer und Gründer von layline.io, das Unternehmensdatenverarbeitungsinfrastrukturen entwickelt, die sowohl Batch- als auch Echtzeit-Workloads in großem Maßstab verarbeiten.