Desde hace algunos años, las arquitecturas de Microservicios y orientadas a servicios han estado en auge. Poco después, la contenedorización ayudó a abstraer la plataforma instalada de la plataforma implementada al empaquetar el sistema operativo y las bibliotecas dependientes junto con la aplicación real.
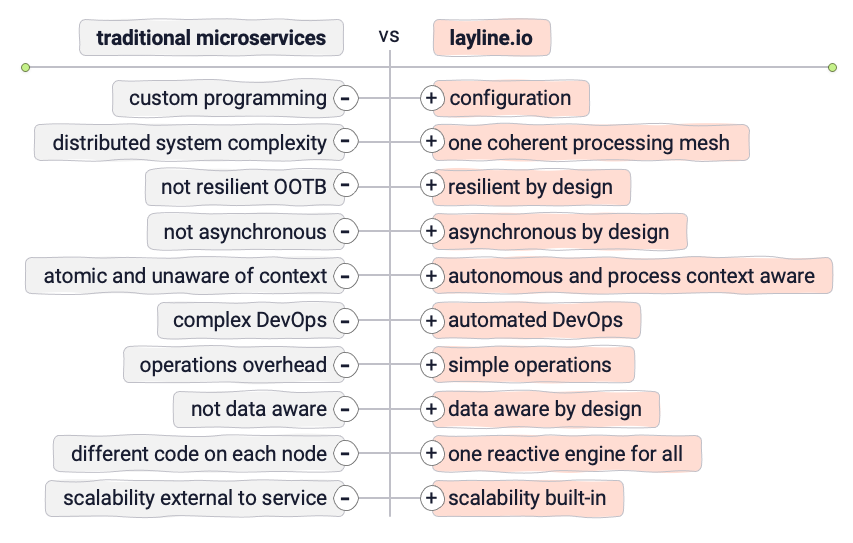
Pero donde hay luz, también hay sombra. Trabajar con y usar Microservicios trae consigo su propio conjunto de desafíos. Encontramos una lista bastante completa aquí. Veamos algunos de los principales pros y contras:
Principales desafíos del desarrollo, implementación y operación de Microservicios
Lo bueno
- Atomicidad: Los servicios autónomos pueden tratarse individualmente en términos de desarrollo y ejecución (aparte de las interfaces).
- Resiliencia: Los servicios individuales generalmente no se ven comprometidos cuando ocurren fallos en otros servicios, lo que conduce a una mejor resiliencia.
- Escalabilidad: Los servicios individuales pueden escalarse de manera elástica según la demanda.
Lo malo
- Acoplamiento débil: Los Microservicios generalmente no tienen conocimiento entre sí ni de su contexto de ejecución más amplio. Son de naturaleza atómica. La comunicación entre ellos conlleva una sobrecarga y no está estandarizada.
- Monitoreo: El monitoreo integral de una variedad de Microservicios es extremadamente difícil y casi imposible de realizar. Identificar claramente problemas individuales en diferentes servicios puede ser extremadamente complicado debido a los diferentes tipos de registros distribuidos, las interdependencias poco claras entre servicios y la extensión de transacciones entre servicios, etc.
- Depuración: Los errores que ocurren en una arquitectura compleja de Microservicios distribuidos pueden ser extremadamente lentos y costosos de rastrear. No existe un sistema de monitoreo general, sino más bien registros individuales y trazas de pila que deben investigarse para concluir con seguridad cuál fue la causa del error.
- Seguridad: Una característica integral de los Microservicios son sus interfaces/APIs. Especialmente en entornos distribuidos, cada una de ellas requiere un cuidado especial en lo que respecta a la seguridad. Es fácil perder el control y la supervisión en entornos de marco tan complejos.
- Resiliencia: Con muchos tipos diferentes de Microservicios, que pueden ser desarrollados por diferentes equipos, se vuelve exponencialmente más difícil garantizar mecanismos de conmutación por error adecuados, de modo que todo el sistema pueda actuar en consecuencia cuando uno o más de los Microservicios fallen.
- Implementación: La implementación de Microservicios individuales en una configuración compleja sin tiempo de inactividad es difícil de orquestar y, a veces, imposible de lograr sin reiniciar todo.
- Comunicación: Debe haber algún tipo de estandarización de la comunicación entre los Microservicios en términos de serialización, seguridad, opciones de solicitud, manejo de errores y la lista de respuestas esperadas. Es muy necesaria alguna forma de orquestación de diseño de alto nivel, de lo contrario, resultará en fallos de comunicación y problemas de latencia.
Esto es solo para nombrar algunos de los desafíos. Hay muchos más desafíos cuando se trata de mantenimiento, redes, gestión de equipos, etc., como puedes imaginar.
Solución: MicroConfigurations en lugar de MicroServices
Si bien la idea de los Microservicios es excelente, puede volverse muy complicada muy rápidamente. Naturalmente, la pregunta es si hay una manera de mantener las partes buenas de una configuración de Microservicios y evitar las malas.
Micro-Configurations puede ser de ayuda aquí. Definimos Micro-Configuration (o MicroConfig) como una separación entre la lógica real del servicio (la Configuración) y la ejecución del servicio (el Motor).
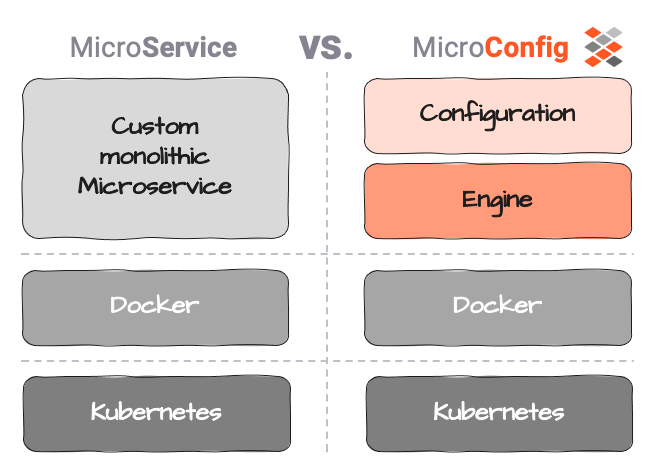
Configuración en este contexto se limitará puramente a la lógica de negocio, es decir, qué hacer con los datos, qué acción desencadenar, etc.
Ejecución es todo lo que hace posible la ejecución de la Configuración:
- ejecución de la lógica (configuración),
- registro centralizado y estandarizado de actividades y problemas,
- orquestación de la ejecución entre servicios,
- generación de métricas para monitoreo,
- soporte para depuración,
- comunicación estandarizada entre los límites de los servicios,
- y mucho más.
Este concepto no es nuevo en el mundo de la tecnología.
Ejemplo: Una base de datos típica distingue entre la estructura de la base de datos (tablas, índices, restricciones, etc.) y el motor de la base de datos (interpretación, almacenamiento, servicio). Mientras que el motor es el mismo para cada usuario, la estructura es única. Sin embargo, nadie consideraría la idea de codificar directamente las tablas en el motor. La separación de configuración y motor es lo que hace que la base de datos sea genérica en primer lugar, cada uno de ellos teniendo un propósito y poder especial.
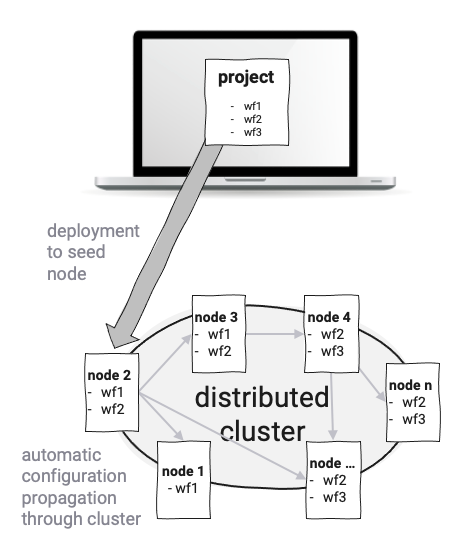
layline.io es similar en el sentido de que los Servicios se implementan como las llamadas Workflow Configurations y no como ejecutables monolíticos. Se puede definir un número ilimitado de Workflows diferentes. Los Workflows son ejecutados por Reactive Engines, que a su vez se ejecutan en Nodes. Un Kubernetes Pod o una Raspberry Pi, por ejemplo, serían un Node. Dos o más Engines forman un Reactive Cluster lógico. La configuración depende únicamente de tus requisitos y entorno. Un número teóricamente indefinido de Engines (en Nodes) puede ser creado y ejecutado en un clúster lógico distribuido geográficamente. El Edge-computing es uno de los casos de uso interesantes aquí. Debido a que todo se ejecuta en el mismo tipo de Reactive Engine, no tienes que preocuparte por qué implementar a nivel físico.
La implementación de Workflow Configurations ocurre automáticamente, ya que una configuración se publica en un Node en el Reactive Cluster, y el Cluster luego propaga automáticamente la configuración a través del Cluster. Esto evita tener que preocuparse por la implementación física de bajo nivel de Microservicios en Pods o Nodes físicos reales. Los nuevos Nodes que se agregan al Cluster también reciben automáticamente los datos de configuración y pueden comenzar a procesar de inmediato.
La Resiliencia, Escalabilidad y Conmutación por error están integradas en layline.io. El monitoreo constante del Cluster asegura el cumplimiento con las escalas configuradas de instancias de Workflows y reequilibra automáticamente la carga de trabajo de los Workflows en caso de fallo de un Node.
El monitoreo y registro centralizados aseguran que los problemas dentro del Reactive Cluster se detecten de inmediato. El remedio comúnmente puede proporcionarse a través de la interfaz de usuario sin interferencia a nivel físico.
Todo dentro de la plataforma de layline.io está estandarizado a nivel de ejecución, pero abierto a nivel de configuración. Esto te permite configurar lo que necesitas, sin tener que preocuparte por las partes difíciles de cómo funciona realmente la infraestructura.
Si bien el concepto de un framework puede no ser algo que los desarrolladores "puristas de bajo nivel" estén dispuestos a aceptar, tiene mucho sentido tanto técnica como comercialmente. ¿Acaso programarías tu propia base de datos?
Recursos
- Top 10 Challenges of Using Microservices for Managing Distributed Systems
- Here's Why Microservices Desperately Need Service Mesh Anomaly Detection
- Lee más sobre layline.io aquí.
- Contáctanos en hello@layline.io.