
¿Cómo se compara layline.io con Kafka?
Esta es una pregunta que escuchamos de vez en cuando. Nos preguntamos por qué. Para entender mejor, veamos qué es Kafka:
¿Qué es Kafka?
Así es como AWS lo describe:
"Apache Kafka es un almacén de datos distribuido optimizado para la ingestión y procesamiento de datos en streaming en tiempo real. Los datos en streaming son datos que se generan continuamente por miles de fuentes de datos, que típicamente envían los registros de datos simultáneamente. Una plataforma de streaming necesita manejar este flujo constante de datos y procesar los datos secuencial e incrementalmente.
Kafka proporciona tres funciones principales a sus usuarios:
- Publicar y suscribirse a flujos de registros.
- Almacenar eficazmente flujos de registros en el orden en que se generaron.
- Procesar flujos de registros en tiempo real.
Kafka se utiliza principalmente para construir pipelines de datos en streaming en tiempo real y aplicaciones que se adaptan a los flujos de datos. Combina mensajería, almacenamiento y procesamiento de flujos para permitir el almacenamiento y análisis de datos tanto históricos como en tiempo real."
Nuestra opinión sobre Kafka
Hay un poco de jerga técnica en la descripción anterior que necesitamos abordar. Habla sobre procesamiento en streaming, tiempo real, etc. ¿Qué significa todo esto en el contexto de Kafka?
- Kafka es una solución de almacenamiento de datos primero. Debe verse como un tipo especial de base de datos en la que los datos se almacenan en colas (temas). Hay varias formas de cómo se pueden escribir (publicar) estas colas y luego leer (suscribirse). Las colas siguen el principio FIFO (primero en entrar, primero en salir). Hay un argumento de que Kafka no es un almacén sino un procesador de eventos en streaming, pero esto es engañoso en nuestra opinión. Kafka está diseñado para almacenar datos y luego para que los Consumidores lean esos datos rápidamente. Está diseñado para deshacerse de los datos almacenados después de un período de retención preconfigurado, independientemente de si los datos fueron consumidos o no. En ese sentido, es un almacén de datos temporal con algunas características muy especiales, aunque útiles.
- Los procesos individuales pueden publicar en colas (Productores) o suscribirse a colas (Consumidores). Si ninguno de los conectores predefinidos (ver más abajo) es suficiente como productor/consumidor para su propósito (probable), entonces necesita codificar uno personalizado usted mismo (la mayoría usa Java, pero hay otras opciones).
- Kafka puede ejecutarse en un entorno nativo de la nube, distribuido, proporcionando resiliencia y escalabilidad.
Confluent (la empresa) ha añadido algunas características más a Kafka, como "Conectores" predefinidos. Los conectores son tipos especiales de Productores y Consumidores que pueden leer/escribir tipos especiales de fuentes/destinos de datos desde/hacia temas de Kafka. Son bastante limitados y especializados en lo que pueden hacer.
Además de esto, crearon la capacidad de "filtrar, enrutar, agregar y fusionar" datos usando "ksql". Sugiere que puede filtrar y enrutar información en tiempo real desde temas de Kafka. Suena genial. Sin embargo, es solo otro tipo de Consumidor que lee datos de un tema de Kafka, luego filtra, agrega, fusiona y enruta resultados a otro tema para que algún otro Consumidor los lea. La mejor manera de comparar esto lógicamente es usar la analogía de una base de datos impulsada por tablas (por ejemplo, Oracle) en la que copia datos de una tabla a otra, usando SQL; excepto que con Kafka es mucho más complicado.
Kafka tiene algunas, pero no significativas, capacidades para transformar datos. Uno de los grandes obstáculos aquí es que Kafka no tiene capacidad inherente para analizar datos, y por lo tanto poder trabajar con ellos. Solo admite muy pocos formatos de datos limitados. Cualquier cosa fuera de lo común (probable) requiere codificación personalizada de Productores y Consumidores para hacer el trabajo. Esto nuevamente es como cualquier otra base de datos que se preocupa principalmente por los internos, no por los externos. En general, es justo decir que Kafka no procesa realmente los datos. Simplemente almacena datos. Cualquier otro escenario implica encadenar temas atómicos con Productores y Consumidores.
Kafka también es conocido por ser bastante difícil de operar. No hay una interfaz de usuario completa. Prácticamente todo se configura en archivos de configuración y se opera desde la línea de comandos.
Resumen
El uso principal de Kafka es para:
- Almacenamiento rápido de datos
- Para grandes volúmenes
- Que se producen y consumen rápidamente
Amamos Kafka para este propósito. Es genial, y lo usamos frecuentemente en implementaciones, aunque hay varias otras soluciones para lograr esto también.
¿Qué es layline.io?
layline.io es un procesador de datos de eventos rápido, escalable y resiliente. Puede ingerir, procesar y emitir datos en tiempo real. Procesar significa "hacer" algo con los datos, a diferencia de lo que hace Kafka (almacenar). Una diferencia importante con Kafka, por ejemplo, es que en layline.io todo gira en torno a la noción de "Workflows". Los Workflows reflejan la lógica impulsada por datos que comúnmente se asemeja a una orquestación de datos compleja.
Esto se traduce en:
- interpretar los datos,
- analizarlos,
- decidir y potencialmente enriquecerlos consultando otras fuentes en tiempo real
- crear estadísticas
- filtrarlos,
- enrutarlo,
- integrar fuentes de datos y destinos dispares.
y hacer todo esto en:
- tiempo real,
- seguro transaccionalmente (opción),
- sin sobrecarga de almacenamiento,
- configurable,
- impulsado por UI
- y mucho más
Ejemplo de Workflow:
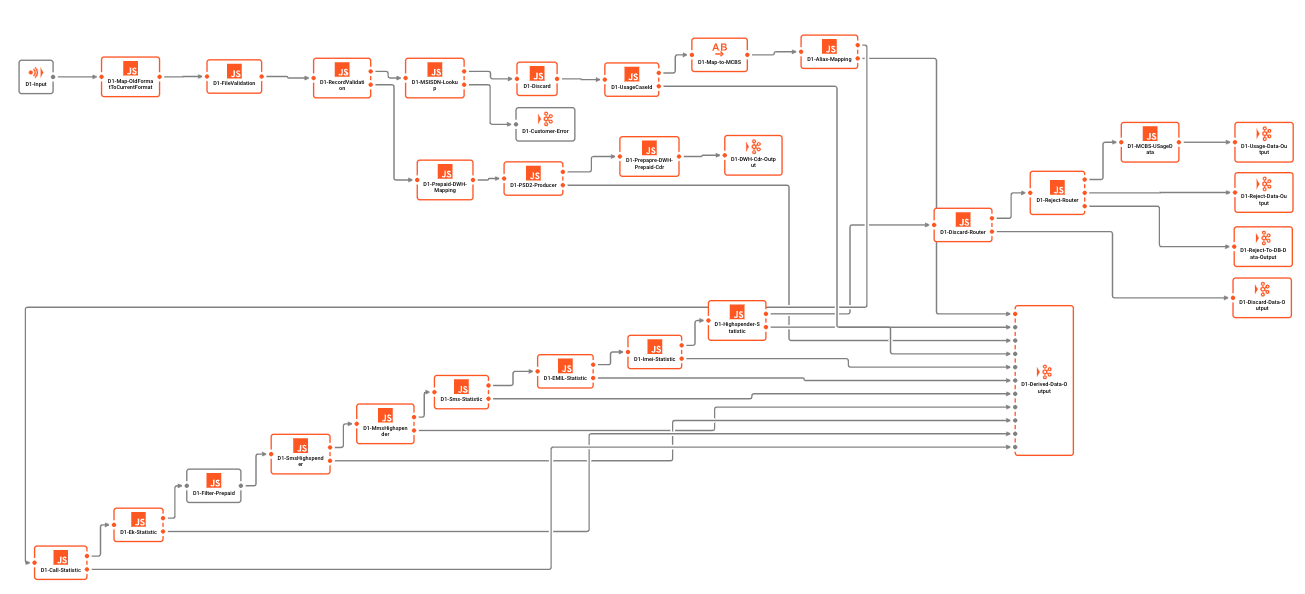
Kafka no admite Workflows por diseño. Cualquier cosa que pueda interpretarse como un Workflow en Kafka es más bien un intento de "vender" un encadenamiento de colas de Kafka y Consumidores / Productores como un Workflow. Sin embargo, tenga en cuenta que cada uno de estos son entidades individuales que no son conscientes unas de otras. No hay un control (transacción) general, ni hay soporte real para Workflows dentro de Kafka.
Combinando Kafka y layline.io
Desde el punto de vista de Kafka, esto significa que layline.io se ve como un Productor (escribir) o Consumidor (leer). Desde el punto de vista de layline.io, Kafka se ve como un almacén de datos de eventos, comparable a otros almacenes de datos como bases de datos SQL, bases de datos NOSQL, o incluso el sistema de archivos. Esa es una gran combinación, dependiendo del caso de uso. layline.io en este contexto actúa como el elemento de orquestación de datos entre un número teóricamente ilimitado de temas de Kafka, y otras fuentes y destinos fuera de la esfera de Kafka.
Desde ese ángulo, Kafka y layline.io son extremadamente complementarios, no competitivos. La superposición es mínima. No vemos un escenario significativo donde un cliente potencial decidiría entre uno u otro, sino más bien por uno y el otro.
¿Cómo se enfrentan los usuarios de Kafka hoy en día?
El usuario típico de Kafka de hoy usa Kafka como lo que es: Un tipo especial de almacén de datos de eventos. Para escribir y leer datos hacia/desde él. Principalmente codifica consumidores y productores personalizados. Estas partes codificadas a medida deben contener los puntos 1 a 6 de arriba (pista: no lo harán). Además, no garantizan resiliencia, escalabilidad, informes, monitoreo y todo lo demás que se esperaría de tales componentes. A menudo se construyen utilizando herramientas de scripting simples como Python hasta usar marcos de microservicios más sofisticados como Spring Boot, etc.
En lugar de esto, podrían simplemente estar usando layline.io y obtener todo lo anterior.
Ejemplo de Despliegue Real
Este cliente real utiliza layline.io para encargarse de procesar todos los datos de uso del cliente (metadatos de comunicación).
Antes de la implementación de layline.io, estaban en una situación que se parecía mucho al escenario descrito en el párrafo anterior. Varias colas de Kafka eran alimentadas por procesos codificados a medida singulares. Otros procesos similares leían de esas colas y escribían datos a otros destinos en otros formatos y con cierta lógica aplicada. Una arquitectura desordenada y propensa a errores, que era costosa de mantener y casi imposible de gestionar.
Después de la implementación de layline.io, en la que se reemplazó la lógica de negocio y los procesadores anteriores, la arquitectura se veía de la siguiente manera:
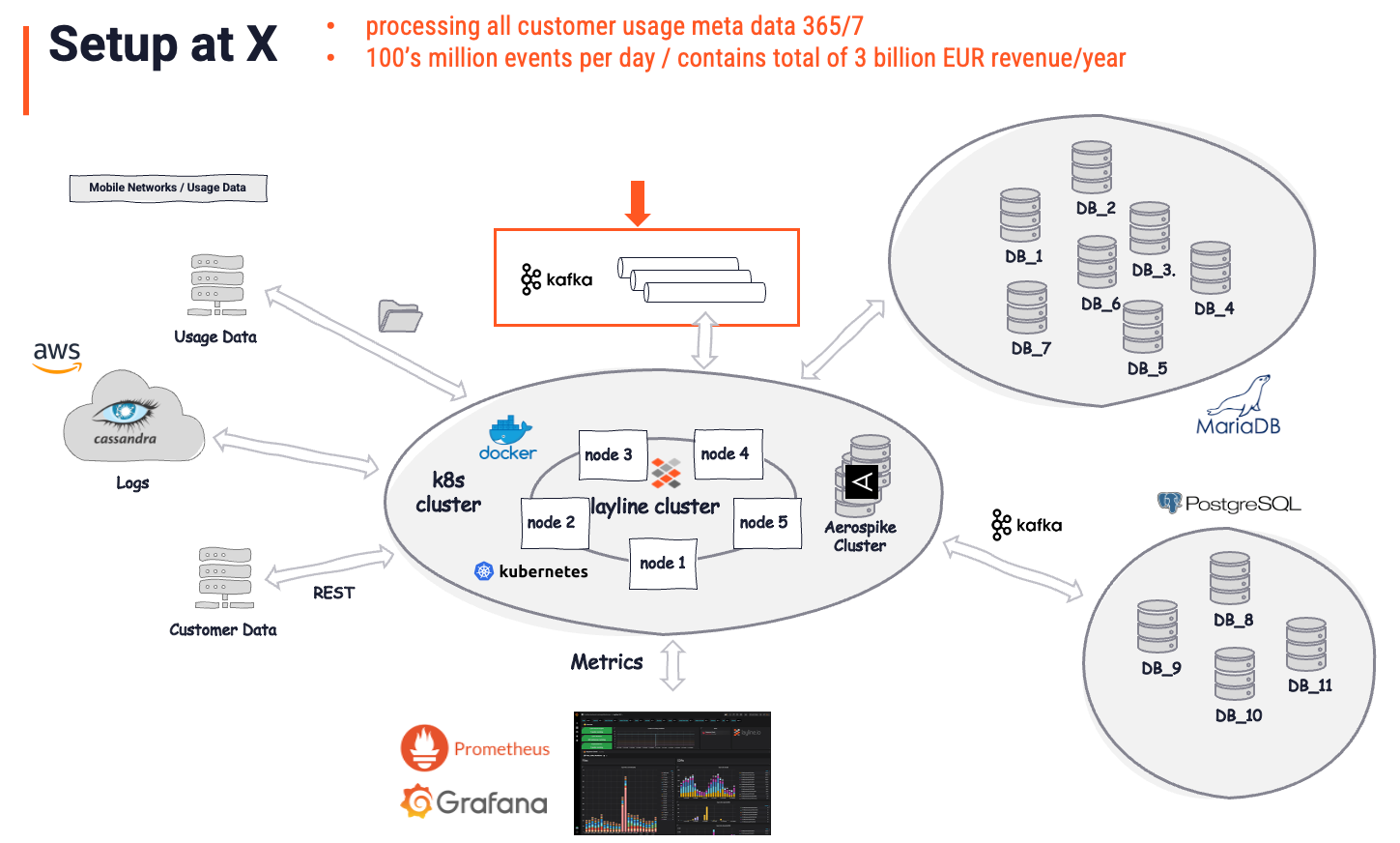
La imagen general se considera la "Solución". Es importante entender que layline.io se reconoce como la solución real, mientras que Kafka es solo otro almacén (importante). Kafka estaba allí antes de layline.io. Sin embargo, juega un papel comparativamente pequeño (flecha y caja roja) en la solución general. Sirve como un almacén de datos intermedio, que es exactamente lo que es por definición. Todo el análisis de datos inteligente, enriquecimiento, filtrado, transformación, enrutamiento, lógica de negocio compleja y mucho más es manejado por layline.io. Una tarea a un nivel que sería imposible de lograr usando Kafka. Al preguntar qué parte de esto se debe a Kafka, la respuesta del cliente probablemente sería: "5% de la solución general".
Conclusión
Kafka es ampliamente considerado un bus de mensajes, pero realmente se trata de datos en reposo que facilitan que otras aplicaciones pongan datos en movimiento. En este contexto, la aplicación real desde el punto de vista de un usuario es algo que se alimenta de datos de Kafka usando una API de cliente. layline.io, por el contrario, forma una parte integral de la lógica de su aplicación, si no es la aplicación misma (ver ejemplo). Puede imaginar layline.io como el sistema circulatorio más la lógica, mientras que Kafka es solo un reservorio externo bien organizado. La superposición entre Kafka y layline.io es por lo tanto mínima.
Un cliente que está ejecutando Kafka, no cuestionará si layline.io podría tener sentido "además de Kafka". Del mismo modo, no cuestionaríamos el uso de Kafka como un almacén de datos, solo si este sería el almacén de datos adecuado para el propósito. Los clientes más bien cuestionarían cómo resuelven problemas (que Kafka no aborda) usando layline.io. Podrían estar haciendo algo nuevo, o reemplazando procesos existentes (por ejemplo, microservicios) que fueron codificados a medida hasta cierto punto en el pasado.
Apéndice: Comparación Rápida layline.io <> Kafka
No es una comparación completa, pero ayuda:
| Aspecto | Kafka | layline.io |
|---|---|---|
| Tipo | Cola de Mensajes | Plataforma de Concurrencia |
| Soporte de Workflow | No realmente. Solo un almacén. | Parte inherente de la solución |
| Almacén de datos | Sí | No |
| Soporte de formato de datos | Sin comprensión de formatos de datos de fábrica. Solo en contexto con ksql algún soporte limitado para formatos como CSV, JSON, Avro, ProtoBuf. | Comprensión completa del contenido de los datos. Fuertemente tipado. Soporte para formatos de datos extremadamente complejos, como ASCII y binario, estructuras jerárquicas, ASN.1, etc. |
| Lógica de negocio | Sin soporte | Soporte completo. Esta es una diferencia importante entre un almacén y una solución de procesamiento de datos. |
| Enriquecimiento de datos | No soportado. No se pueden consultar terceros para el enriquecimiento de datos. | Soporte completo. |
| Tiempo real | Kafka es un almacén. Esto solo puede ser tan en tiempo real como lo que sea que lea los datos del almacén (buffer). | Completo. Tan en tiempo real como se puede. Sin almacenamiento intermedio. Los datos se procesan y se emiten instantáneamente. |
| Métricas personalizadas | No hay métricas personalizadas específicas para su caso de uso | Cualquier tipo de métrica personalizada (por ejemplo, "4711 clientes se han registrado para el servicio y en el último intervalo de tiempo") |
| Rendimiento | Alto | Alto |
| Escalable | Sí | Sí |
| Resiliente / HA | Sí | Sí |
| Persistente | Sí. Ese es el propósito de Kafka. | No. No es el propósito de layline.io, pero funciona muy bien con capas de persistencia, como Kafka. |
| Configuración impulsada por UI | No | Sí |
| Intensidad de memoria | Alta | Baja |
| Huella de hardware | Alta | Baja |
| Código Abierto | Sí, para la edición comunitaria. No para la solución de confluent (por ejemplo, ksql) | Aún no. |
| Oferta en la nube lista | Sí, para confluent | Aún no. |
- Lea más sobre layline.io aquí.
- Contáctenos en hello@layline.io.