Depuis quelques années, les Microservices et les architectures orientées services sont très en vogue. Peu après, la conteneurisation a permis d'abstraire la plateforme installée de la plateforme déployée en regroupant le système d'exploitation et les bibliothèques dépendantes avec l'application elle-même.
Mais là où il y a de la lumière, il y a de l'ombre. Travailler avec et utiliser des Microservices s'accompagne de son lot de défis. Nous avons trouvé une liste assez complète ici. Examinons certains des principaux avantages et inconvénients :
Principaux défis du développement, du déploiement et de l'exploitation des Microservices
Les avantages
- Atomicité : Les services autonomes peuvent être traités individuellement en termes de développement et d'exécution (à l'exception des interfaces).
- Résilience : Les services individuels ne sont généralement pas compromis en cas de défaillance d'autres services, ce qui conduit à une meilleure résilience.
- Scalabilité : Les services individuels peuvent être mis à l'échelle de manière élastique à la demande.
Les inconvénients
- Couplage lâche : Les Microservices ne se connaissent généralement pas entre eux ni dans leur contexte d'exécution global. Ils sont de nature atomique. La communication entre eux entraîne une surcharge et n'est pas standardisée.
- Supervision : Une supervision complète d'une variété de Microservices est extrêmement difficile, voire presque impossible. Identifier clairement les problèmes individuels à travers différents services peut être très compliqué en raison de la diversité des types de journaux répartis un peu partout, des interdépendances peu claires entre les services et des transactions s'étendant sur plusieurs services, etc.
- Débogage : Les erreurs qui surviennent dans une architecture complexe de Microservices distribués peuvent être extrêmement chronophages et coûteuses à tracer. Il n'existe pas de système de supervision global, mais plutôt des journaux individuels et des traces de pile qui doivent être examinés pour conclure en toute sécurité à la cause de l'erreur.
- Sécurité : Une caractéristique intégrale des Microservices est leurs interfaces/APIs. Surtout dans des environnements distribués, chacun d'eux nécessite une attention particulière en matière de sécurité. Il est facile de perdre de vue et de contrôle dans des environnements de framework aussi complexes.
- Résilience : Avec de nombreux types différents de Microservices, qui peuvent être développés par différentes équipes, il devient exponentiellement plus difficile de garantir des mécanismes de basculement appropriés, afin que l'ensemble du système puisse réagir correctement lorsqu'un ou plusieurs Microservices échouent.
- Déploiement : Le déploiement de Microservices individuels dans une configuration complexe sans temps d'arrêt est difficile à orchestrer et parfois impossible à réaliser sans tout redémarrer.
- Communication : Une certaine forme de standardisation de la communication entre les Microservices est nécessaire en termes de sérialisation, de sécurité, d'options de requête, de gestion des erreurs et de liste des réponses attendues. Une forme d'orchestration de conception de haut niveau est très nécessaire, sinon cela entraînera des échecs de communication et des problèmes de latence.
Ce ne sont que quelques-uns des défis. Comme vous pouvez l'imaginer, il existe de nombreux autres défis en matière de maintenance, de mise en réseau, de gestion des équipes, etc.
Solution : MicroConfigurations au lieu de MicroServices
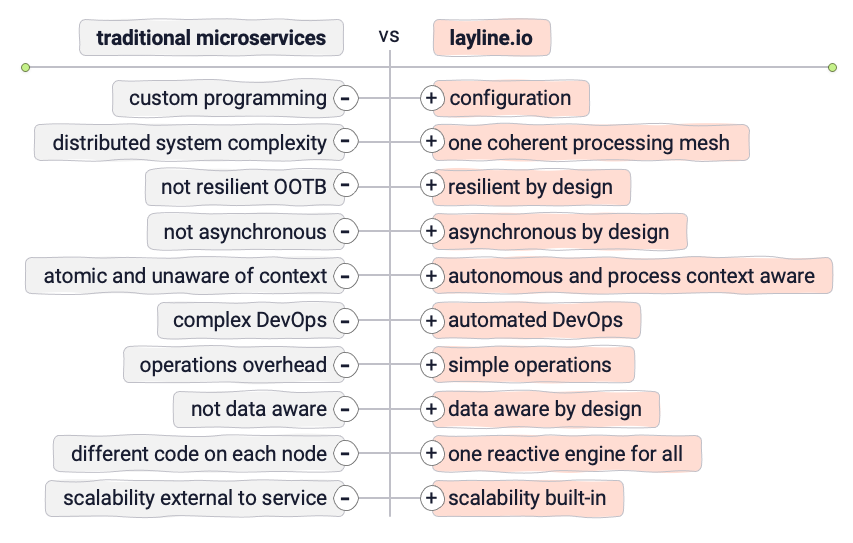
Bien que l'idée des Microservices soit excellente, elle peut rapidement devenir très complexe. Naturellement, la question est de savoir s'il existe un moyen de conserver les bons aspects d'une configuration Microservices tout en évitant les mauvais.
Les Micro-Configurations pourraient être une solution. Nous définissons la Micro-Configuration (ou MicroConfig) comme une séparation entre la logique réelle du service (la Configuration) et l'exécution du service (le Moteur).
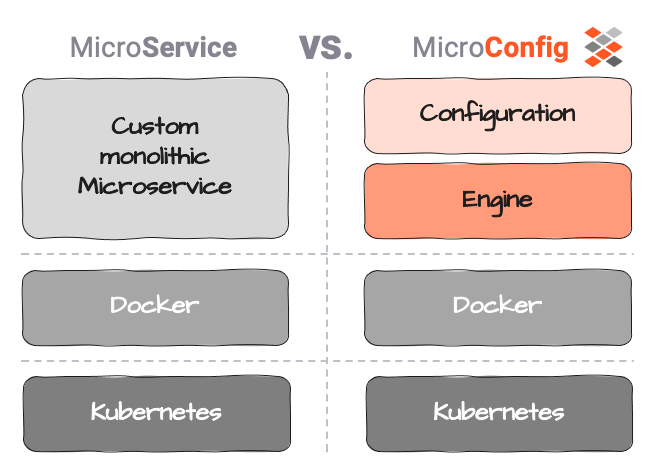
La Configuration, dans ce contexte, doit être purement limitée à la logique métier, c'est-à-dire ce qu'il faut faire avec les données, quelle action déclencher, etc.
L'Exécution comprend tout ce qui rend possible l'exécution de la Configuration :
- l'exécution de la logique (configuration),
- la journalisation centralisée et standardisée des activités et des problèmes,
- l'orchestration de l'exécution entre les services,
- le reporting des métriques pour la supervision,
- le support au débogage,
- la communication standardisée entre les frontières des services,
- et bien plus encore.
Ce concept n'est généralement pas nouveau dans le monde de la technologie.
Exemple : Une base de données typique distingue entre la structure de la base de données (tables, index, contraintes, etc.) et le moteur de la base de données (interprétation, stockage, service). Alors que le moteur est le même pour chaque utilisateur, la structure est unique. Pourtant, personne n'envisagerait de coder en dur les tables directement dans le moteur. La séparation entre configuration et moteur est ce qui rend la base de données générique en premier lieu, chacun ayant un objectif et une puissance spécifiques.
layline.io est similaire en ce que les Services sont implémentés comme des Workflow Configurations et non comme des exécutables monolithiques. Un nombre illimité de Workflows différents peut être défini. Les Workflows sont exécutés par des Reactive Engines qui, à leur tour, fonctionnent sur des Nodes. Un Pod Kubernetes ou un Raspberry Pi, par exemple, serait un Node. Deux ou plusieurs Engines forment un Reactive Cluster logique. La configuration dépend uniquement de vos besoins et de votre environnement. Un nombre théoriquement illimité d'Engines (sur des Nodes) peut être déployé et exécuté dans un cluster logique distribué géographiquement. Le Edge-computing est l'un des cas d'utilisation intéressants ici. Étant donné que tout fonctionne sur le même type de Reactive Engine, vous n'avez pas à vous soucier de ce qu'il faut déployer au niveau physique.
Le déploiement des Workflow Configurations se fait automatiquement en publiant une configuration sur un Node dans le Reactive Cluster, et le Cluster propage ensuite automatiquement la configuration dans tout le Cluster. Cela évite d'avoir à se soucier du déploiement physique de bas niveau des Microservices sur des Pods ou des Nodes physiques réels. Les nouveaux Nodes ajoutés au Cluster reçoivent également automatiquement les données de configuration et peuvent commencer à traiter immédiatement.
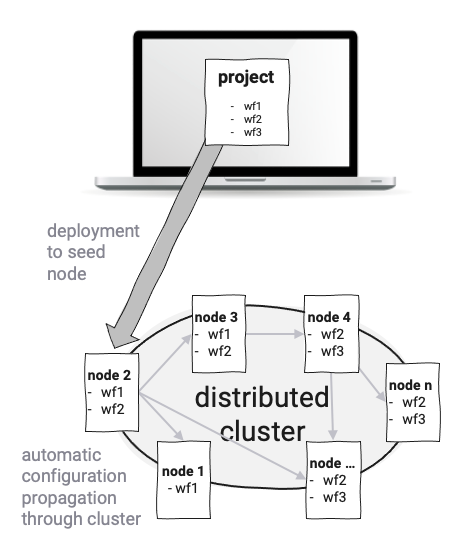
La Résilience, la Scalabilité et le Basculement sont intégrés à layline.io. Une supervision constante du Cluster garantit la conformité avec les échelles configurées des instances de Workflows, et rééquilibre automatiquement la charge de travail des Workflows en cas de défaillance d'un Node.
La supervision et la journalisation centralisées permettent de repérer immédiatement les problèmes au sein du Reactive Cluster. Les solutions peuvent généralement être apportées via l'interface utilisateur sans interférer au niveau physique.
Tout au sein de la plateforme layline.io est standardisé au niveau de l'exécution, mais ouvert au niveau de la configuration. Cela vous permet de configurer ce dont vous avez besoin, sans avoir à vous soucier des aspects complexes liés au fonctionnement de l'infrastructure.
Bien que le concept de framework ne soit peut-être pas ce que les développeurs "puristes du bas niveau" aiment adopter, il a beaucoup de sens d'un point de vue technique et commercial. Vous ne programmeriez pas votre propre base de données non plus, n'est-ce pas ?
Ressources
- Top 10 Challenges of Using Microservices for Managing Distributed Systems
- Here's Why Microservices Desperately Need Service Mesh Anomaly Detection
- En savoir plus sur layline.io ici.
- Contactez-nous à hello@layline.io.


