
Che cos'è la data-pressure?
Si sente spesso parlare di data-pressure quando si tratta di sistemi non-stop. Che cos'è e perché è così importante?
La pressione, nel senso fisico, descrive uno squilibrio tra gas o fluidi tra due compartimenti confinati. Si bilancia in entrambe le direzioni fino a raggiungere un equilibrio. Se si vuole gestirla, di solito si mette una valvola tra i due.
Nei sistemi di elaborazione dati, la data-pressure, o upstream-pressure, descrive la quantità di dati pronti per l'elaborazione. Per le soluzioni basate su file (batch), questo descrive semplicemente la quantità di file in attesa di essere elaborati (asincroni). La velocità di elaborazione dipende esclusivamente dalla potenza di elaborazione degli attori downstream ed è basata sulla domanda. La data-pressure nei batch di solito non rappresenta una minaccia di sovraccarico del sistema perché è implicita. Il sistema di elaborazione batch elaborerà sempre solo quanto è in grado di gestire.
Tuttavia, è una storia molto diversa negli ambienti moderni di elaborazione in tempo reale basati su messaggi, dove la data-pressure è esplicita perché i dati devono essere elaborati man mano che arrivano.
Importanza del back-pressure nei sistemi non-stop in tempo reale
I casi d'uso basati su messaggi di solito richiedono che i dati vengano gestiti in tempo reale, in ogni momento. Pertanto, i sistemi devono essere in grado di scalare elasticamente per gestire i picchi di carico o liberare risorse non necessarie durante le finestre di bassa data-pressure.
Esistono innumerevoli esempi di architetture che si bloccano quando devono gestire grandi carichi di dati. Questo spesso porta a un circolo vizioso che tipicamente conduce al collasso di tali architetture. Il dilemma principale è l'assenza di un segnale di domanda negativo (o di un segnale di alto back-pressure dei dati) verso gli attori upstream, su cui essi possano reagire. Se esistesse un tale segnale, si potrebbero adottare azioni appropriate.
Tali azioni potrebbero essere:
- rallentare l'elaborazione complessiva lungo il flusso di dati, oppure
- attivare più potenza di elaborazione per gestire la pressione aggiuntiva
Una volta che la data-pressure upstream diminuisce, le contromisure possono essere invertite. Più dati possono essere nuovamente consegnati, oppure la potenza di elaborazione precedentemente attivata può essere dismessa.
Per riassumere, abbiamo:
- un data-signal o upstream-pressure che segnala che i dati sono disponibili per l'elaborazione, e
- un demand-signal o back-pressure che segnala quanto sono carichi gli attori downstream e se la pressione degli attori upstream può essere trasferita su quelli downstream.
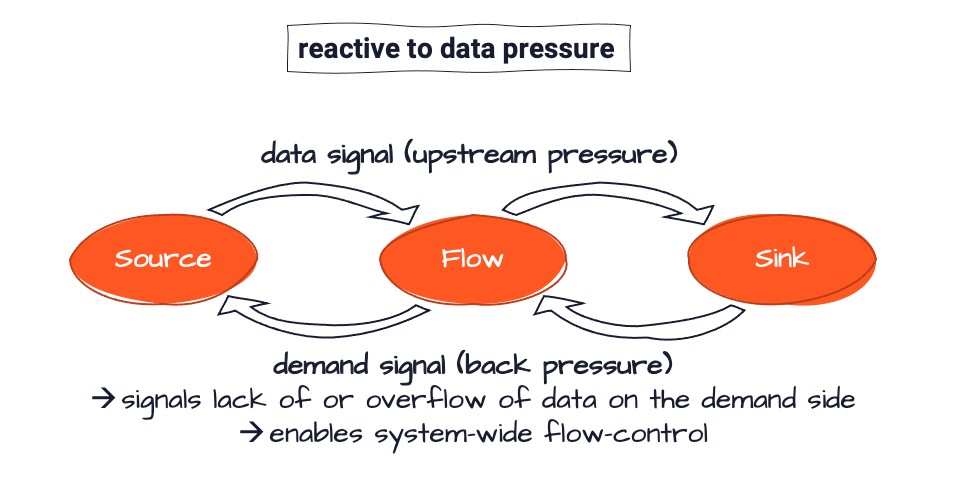
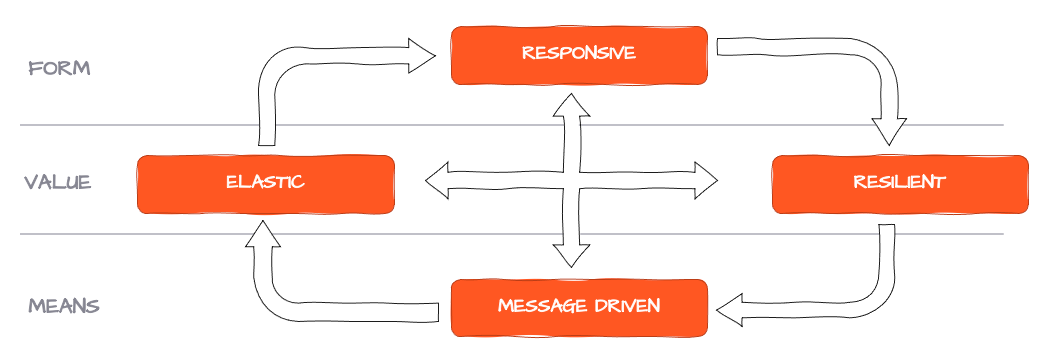
Utilizzando questi segnali, il sistema è in grado di negoziare un equilibrio tra tutti i partecipanti, garantendo che l'elaborazione non si fermi mai, ma piuttosto rallenti (o che venga automaticamente resa disponibile una capacità aggiuntiva). Questo problema è ben riconosciuto e definito nel Reactive Manifesto, che richiede che i sistemi siano basati su messaggi, elastici e resilienti, e quindi reattivi al carico. I sistemi che soddisfano questi requisiti sono chiamati "Reactive".
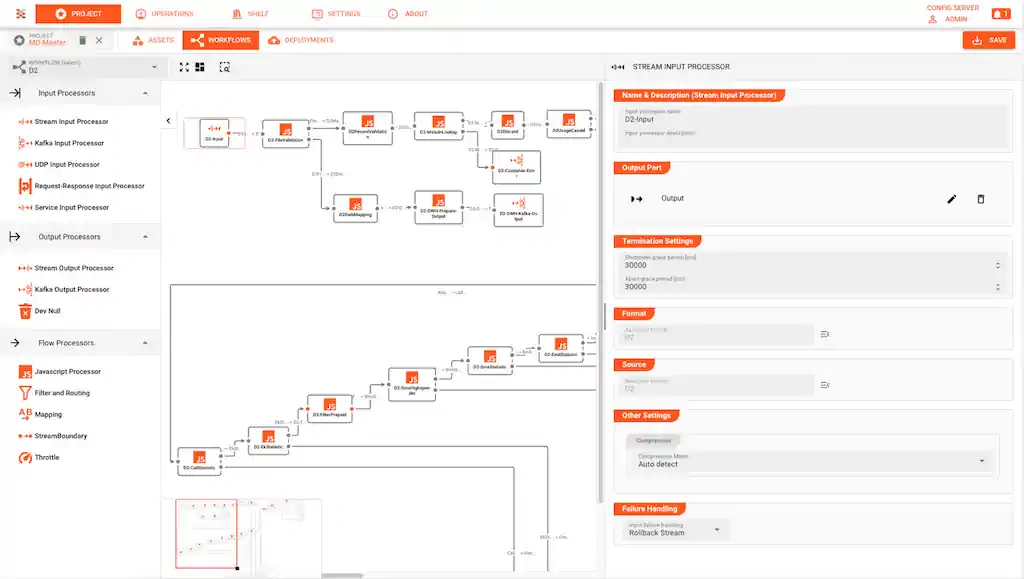
Come lo gestisce layline.io
Sembra che la soluzione alla sfida del back-pressure sia semplice. Ma in realtà è difficile da risolvere, poiché tutti i partecipanti in questa "danza" devono essere consapevoli della data-pressure, in entrambe le direzioni. La gestione dei flussi reattivi ha risolto questo problema, motivo per cui layline.io ne sfrutta appieno le potenzialità sotto il cofano. Tuttavia, non è per i deboli di cuore e comporta una curva di apprendimento e di esperienza piuttosto ripida. layline.io protegge i suoi utenti da questa complessità con una piattaforma facile da usare, che offre tutte le funzionalità necessarie per la produzione, come configurabilità low-code guidata da interfaccia utente, distribuzione con un solo clic, monitoraggio e molto altro.
Risorse
- Reactive Manifesto
- Leggi di più su layline.io qui.
- Contattaci a hello@layline.io.