Toutes les fonctionnalités dont vous avez besoin. Rien de ce que vous ne faites pas.
Des flux de travail visuels aux formats de données exotiques en passant par le déploiement de niveau opérateur,layline.io donne aux équipes d'ingénierie les outils nécessaires pour créer des pipelines de données en temps réel sans encombrement.
Construit pour Pipelines du monde réel
Tout ce dont vous avez besoin pour créer, déployer et surveiller des pipelines de données de production
Développement de flux de travail visuel
Créez des pipelines complexes avec la simplicité du glisser-déposer
Toile intuitive par glisser-déposer
Créez des flux de travail visuellement en connectant les processeurs: accélérez le développement avec une configuration sans code, passez à des scripts personnalisés si nécessaire
Validation en temps réel
Détectez les erreurs de configuration lors de la création, avant le déploiement
- Vérification instantanée de la syntaxe
- Validation du schéma
- Détection de dépendance
- Erreur de mise en évidence
Prêt pour le contrôle de version
Configurations stockées sous JSON et scripts: suivez les modifications, branchez, fusionnez avec n'importe quel système de contrôle de version
Assets réutilisables
Créez des composants modulaires et réutilisables qui peuvent être utilisés comme processeurs ou référencés par d'autres processeurs: construits une seule fois, utilisés partout
- Héritage d'Asset pour une maintenance facile
- Dérivez les Assets les uns des autres
- Partagé entre les flux de travail et les projets
Modèles personnalisés
Créez vos propres modèles de flux de travail et partagez-les entre les projets et les équipes
- Enregistrez les flux de travail sous forme de modèles réutilisables
- Partager entre les projets et les équipes
- Exportez des projets entiers ou des pièces pour les réutiliser
Créez une seule fois, déployez partout, dans les environnements et les équipes
Débogage connecté au navigateur
Attachez le débogueur de votre navigateur au code Python ou JavaScript et utilisez toute la puissance des outils de développement modernes
- Exécution pas à pas et points d'arrêt conditionnels
- Surveiller les expressions, les étendues et les piles d'appels
- Inspection des messages à chaque étape avec des variables en direct
- Traces de pile d'erreurs avec mappage de source
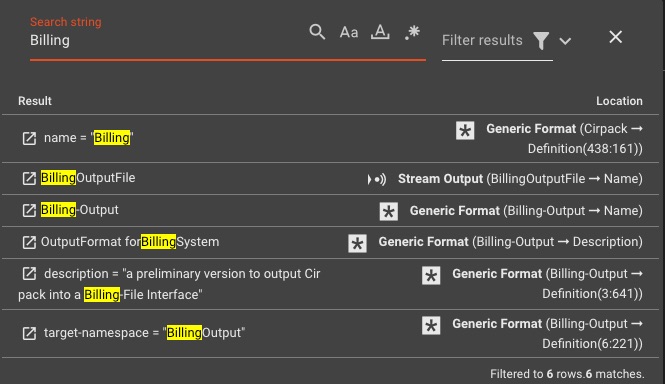
Recherche et navigation dans le flux de travail
Recherchez et parcourez rapidement les processeurs, les configurations, les éléments de flux de travail et les scripts
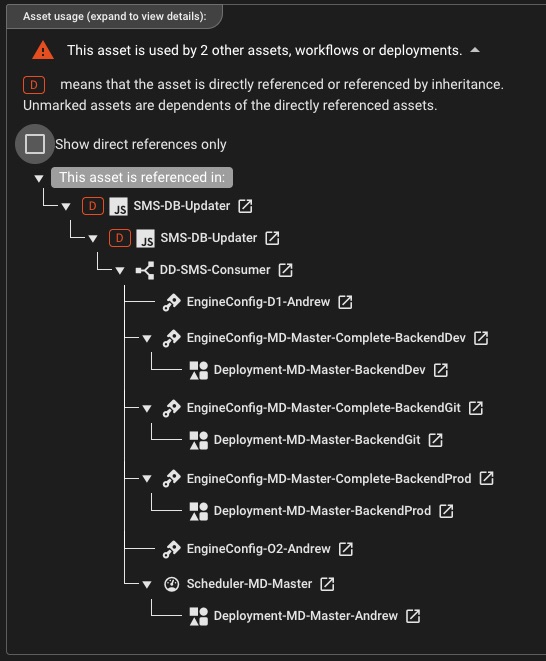
Visualisation des dépendances d'Asset
Comprendre comment les Assets, les flux de travail et les déploiements sont connectés tout au long de votre projet
Collaboration en équipe
Partagez des flux de travail et collaborez grâce au contrôle d'accès basé sur les rôles
- Contrôle d'accès granulaire
- Édition de projet simultanée
- Notifications de changement de projet
Connectivité universelle des données
Prise en charge du protocole universel pour toutes les sources et destinations de données
Plateformes de diffusion en continu
Kafka, AWS SQS & SNS, UDP, Azure Event Hubs, et bien plus encore, le tout avec une prise en charge native
- • Groupes de consommateurs
- • Sémantique « exactement une fois »
- • Traitement par lots
- • Flux de données Kinesis
- • Messagerie SQS & SNS
- • S3 notifications d'événements
Connecteurs de base de données
Lisez et écrivez dans n'importe quelle base de données avec prise en charge de la capture des données modifiées
- PostgreSQL, MySQL, SQL Server
- MongoDB, Cassandra, Redis
- Elasticsearch, DynamoDB
- AWS Keyspaces
- Hazelcast
- GCS
- Sharepoint
- plus...
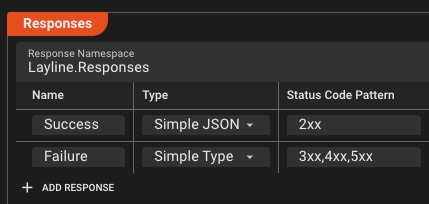
REST APIs et webhooks
Appelez n'importe quel point de terminaison HTTP avec nouvelle tentative, coupure de circuit et authentification intégrées
- OAuth 2.0, API touches, JWT
- GraphQL requêtes
Services cloud natifs
Intégration profonde avec AWS, Azure et Google Cloud
- S3, Azure Blob, GCS
- SNS/SQS, Service Bus
- CloudWatch & App Insights
- IAM & identités gérées
Enterprise Partage de fichiers
Accédez aux partages de fichiers d'entreprise et aux référentiels de documents cloud
- SMB/CIFS partages réseau
- NFS (Système de fichiers réseau)
- WebDAV prise en charge du protocole
- Abstraction du système de fichiers virtuel
Microsoft 365 Intégration
Intégration approfondie avec SharePoint, OneDrive et Microsoft Graph API pour la collaboration en entreprise
Protocoles réseau
Accès réseau de bas niveau pour les protocoles personnalisés et le streaming de données en temps réel
- TCP/UDP prise en charge des sources et récepteurs
- Gestion des sockets brutes
- Implémentation de protocole personnalisé
- Streaming de données binaires
Intégration de la messagerie
Déclenchez des flux de travail à partir d'e-mails et envoyez des notifications avec des pièces jointes
- IMAP/POP3 sources de courrier électronique
- SMTP envoi par e-mail
- Traitement des pièces jointes
- Surveillance multi-boîtes aux lettres
Minuterie et sources programmées
Déclenchez des workflows sur des plannings, des fenêtres horaires ou des intervalles récurrents pour le traitement par lots et les tâches périodiques
Modèles de planification complexes avec prise en charge complète de Cron
Déclenchement simple basé sur des intervalles de quelques secondes à plusieurs mois
Définir des plages horaires spécifiques pour le traitement par lots
Systèmes de fichiers et protocoles hérités
Traitez les fichiers à partir de disques locaux, de partages réseau, de serveurs FTP/SFTP ou de stockage cloud, avec interrogation automatique, correspondance de modèles et déplacement après traitement
Formats de données et analyse
Analysez n'importe quel format, de JSON aux anciens protocoles de télécommunications
Formats standards
Prise en charge native des formats de données que vous utilisez déjà
- ASN.1
- XML
- CSV, TSV, fichiers délimités
- Tous formats ASCII structurés, binaires ou mixtes
- Enregistrements à largeur fixe
Configuration du format universel
Définissez n'importe quel format de données personnalisé (CSV, hiérarchique ASCII, binaire ou structures mixtes) avec un puissant langage de configuration basé sur la grammaire.
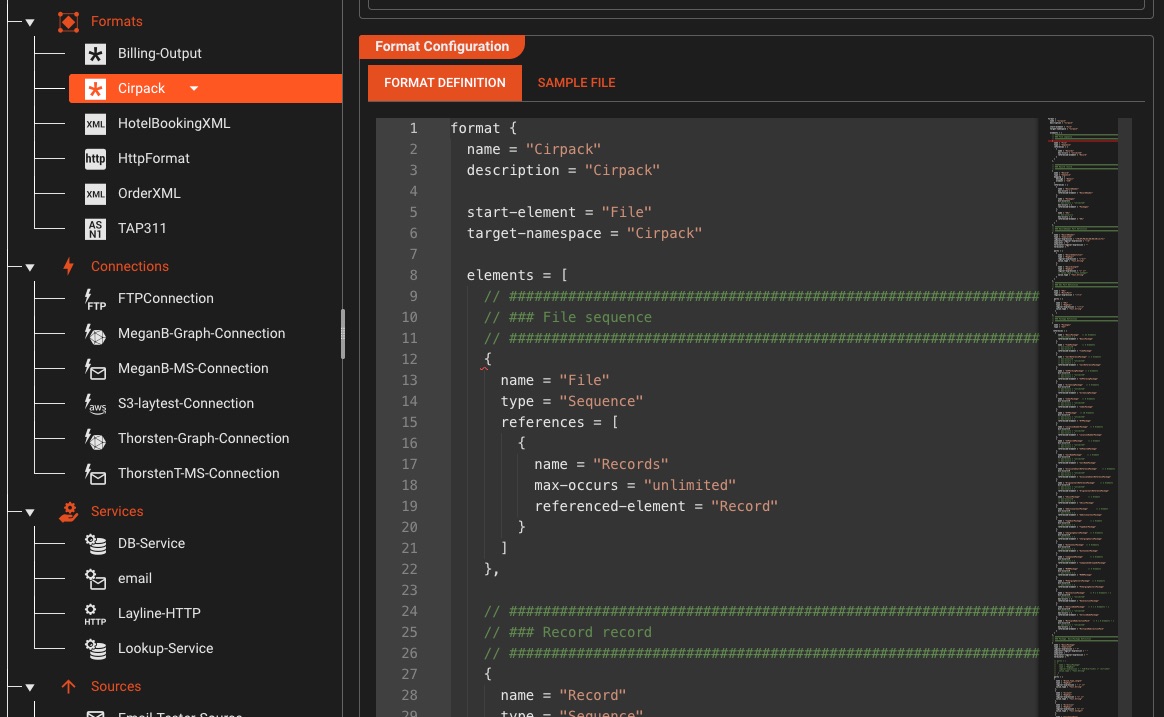
Définir des formats à l'aide d'expressions régulières et de structures hiérarchiques
Téléchargez des exemples de fichiers et testez votre grammaire en temps réel
Utilisez la même grammaire pour analyser l'entrée et générer la sortie
Validation de la syntaxe en temps réel et mise en évidence des erreurs dans l'éditeur
ASN.1 & Protocoles Télécom
Capacité uniqueAnalyse ASN.1 de pointe pour les télécommunications CDRs, SS7, TCAP, MAP et les protocoles existants: des fonctionnalités que vous ne trouverez pas dans les outils génériques ETL
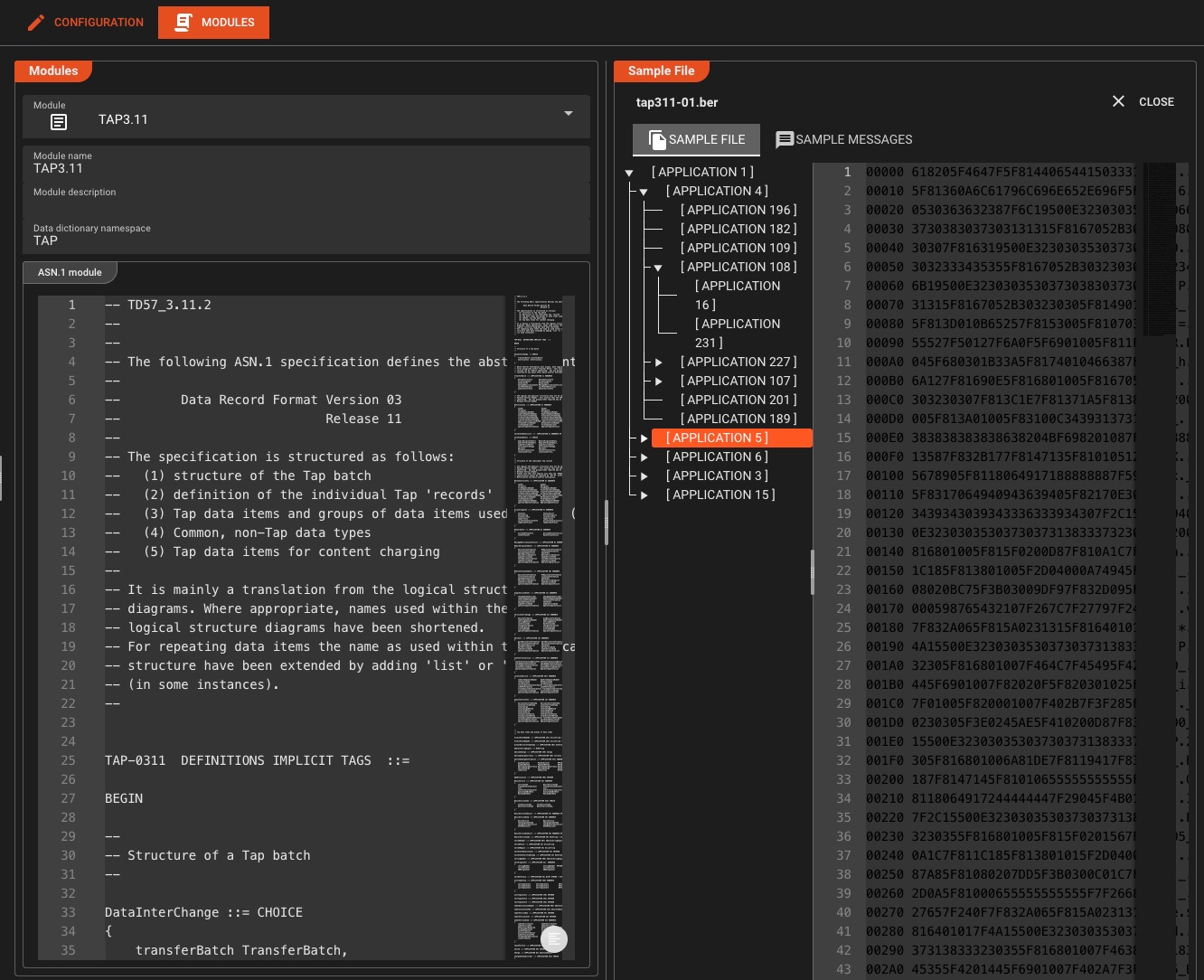
Normes prises en charge
Cas d'utilisation: Traitez quotidiennement des milliards de télécommunications CDRs avec une analyse en moins d'une milliseconde
Data Dictionary
Système de saisieDéfinissez des structures et des types de données personnalisés qui peuvent être réutilisés tout au long de vos flux de travail, avec une prise en charge complète de l'encodage/décodage vers des formats externes tels que JSON
Types personnalisés
Définir des séquences, des tableaux, des énumérations, des choix et des espaces de noms
Réutilisabilité du type
Types de référence dans tous les formats et flux de travail pour plus de cohérence
Augmentation des messages
Ajouter des données dérivées ou enrichies aux messages au moment de l'exécution
Intégration des formats
Types de référence à partir de n'importe quel format: générique, ASN.1 ou autres Data Dictionaries
Transformation de formats
Appliquer des transformations pour convertir entre n'importe quel format
- Cartographie et restructuration du terrain
- Conversions de types de données
Formats binaires personnalisés
Définissez vos propres analyseurs de structure binaire avec précision
- Extraction de champ au niveau du bit
- Structures imbriquées
- Analyse conditionnelle
Validation et qualité
Récupérez les données mal formées avant qu'elles ne corrompent votre pipeline
- Validation du schéma
- Règles de validation personnalisées
- Enrichissement des erreurs
Traitement du format natif
Changeur de jeuContrairement aux outils ETL traditionnels qui vous obligent à mapper des formats externes à des schémas internes fixes et inversement, layline.io fonctionne directement avec vos données dans leur format natif, éliminant ainsi les frais de transformation inutiles.
Systèmes traditionnels ETL
- •Mapper le format externe sur un schéma interne fixe lors de la lecture
- •Traiter les données dans une représentation interne générique
- •Mapper le schéma interne au format cible lors de l'écriture
- •Double surcharge et complexité de transformation
layline.io Approche
- Analyser les données directement dans la structure de format natif
- Travailler avec les données dans leur structure d'origine tout au long
- Data Dictionary créé dynamiquement à partir de vos formats
- Extension avec des structures personnalisées selon vos besoins – pas de mappage
Pourquoi c'est important
Logique métier et transformation
Intégrez une logique personnalisée pour l’enrichissement, le routage et les transformations complexes
Gestion des erreurs et nouvelle tentative
Gérez les échecs avec élégance grâce à des politiques de nouvelle tentative configurables et des files d'attente de lettres mortes
- Politiques de nouvelle tentative configurables
- Stratégies d'attente exponentielle
- Routage de la file d'attente des lettres mortes
- Modèles de disjoncteurs
- Catégorisation des erreurs
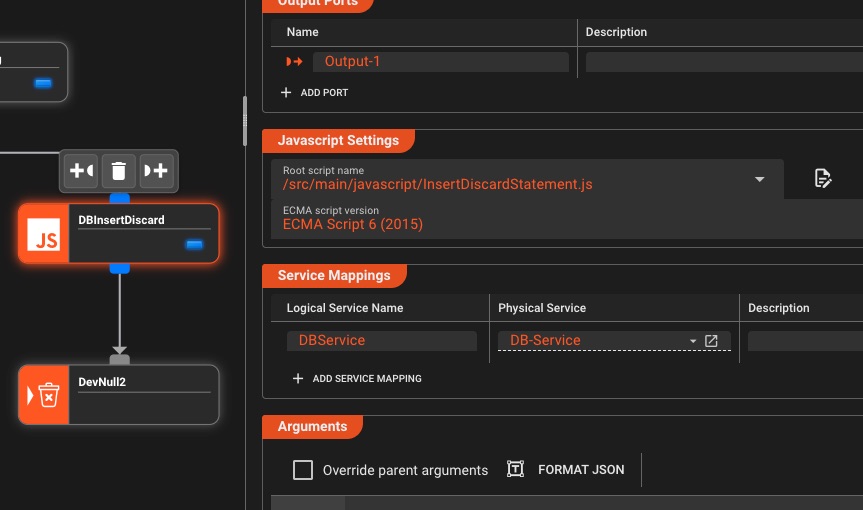
JavaScript & Python Scripts
Intégrez du code personnalisé directement dans vos flux de travail: prise en charge complète des langues, sans bac à sable limité
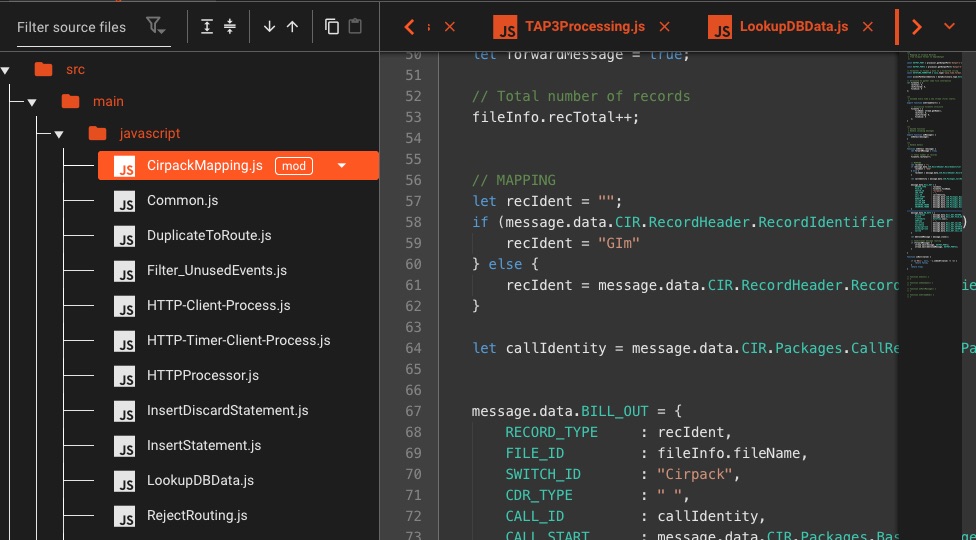
💡 Vous pouvez également utiliser votre IDE préféré à des fins de script
- Prise en charge asynchrone/attente
- Importation/Exportation
- Crochets de cycle de vie
- Utilisez Javascript/Python de manière interchangeable
Cartographie des champs
Transformer et mapper les champs de données entre différents formats et schémas
- Mappeur de champ visuel
- Accès aux champs imbriqués
- Mappages conditionnels
- Coercition de type
- Gestion des valeurs par défaut
Enrichissement des données
Augmentez les événements avec des données externes provenant de APIs, de bases de données ou de caches
- Accédez aux sources de services n’importe où dans le pipeline
Routage et filtrage
Définissez vos propres règles avec des conditions individuelles: un processeur très flexible adapté à la plupart, sinon à la totalité, des cas de routage et de filtrage. Si cela ne suffit pas, vous pouvez toujours recourir aux scripts.
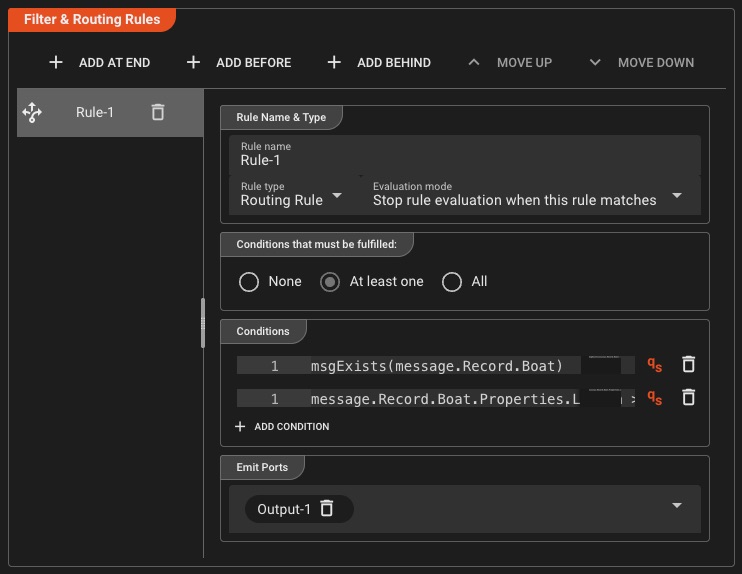
Routage basé sur des règles
- Définir plusieurs conditions par règle
- Routage multidirectionnel vers différents ports
- Combinaisons de conditions ET/OU
Filtrage flexible
- Règles de filtrage basées sur le contenu
- Comparaisons de valeurs de champ
- Revenir aux scripts si nécessaire
Limitation et limitation du débit
Contrôlez le flux des messages et évitez la surcharge du système grâce à une limitation intelligente
- Contrôle du débit des messages
- Gestion de backpressure
- Gestion des rafales
- Limitation dynamique
Traitement avec état
Maintenir l’état à travers les événements pour les flux de travail complexes
- Magasins d'état en mémoire
- Backends d’état persistants
- Des garanties ponctuelles
- Points de contrôle et récupération
- Sécurité transactionnelle
Suivez les sessions utilisateur, comptez les événements ou maintenez les totaux cumulés sur des millions de flux
Agrégation et fenêtres temporelles
Traitez les flux avec des fenêtres de basculement, de glissement ou de session pour des analyses en temps réel
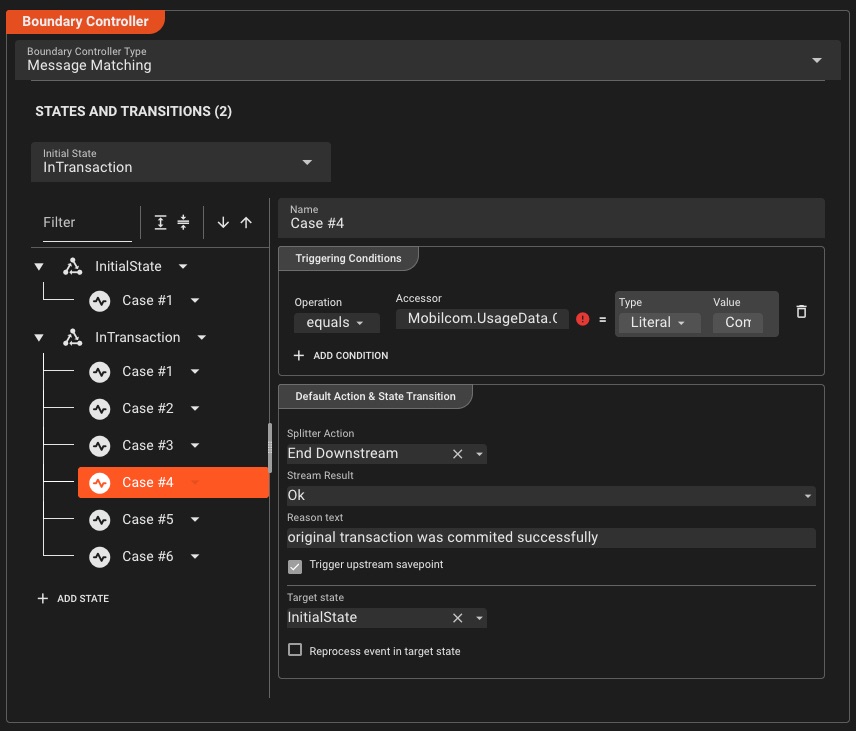
Fenêtres qui tombent
Tranches de temps de taille fixe et sans chevauchement
Toutes les 5 minutesFenêtres coulissantes
Fenêtres superposées pour les moyennes mobiles
Fenêtre de 10 minutes, diapositive de 1 minuteFenêtres de session
Regroupement basé sur les activités avec délai d'attente
Intervalle d'inactivité de 30 secondesFlexibilité illimitée
En utilisant JavaScript ou Python, vous pouvez définir tout type de logique de traitement en fonction des messages circulant dans vos processeurs. Chaînez un ou plusieurs processeurs pour mettre en œuvre des systèmes complets: détection de fraude, calcul de prix, filtrage, transformation ou tout ce qui vous vient à l'esprit. Enrichissez les données provenant de sources externes, branchez et acheminez vers des destinations spécifiques en fonction de votre logique métier. Vous pouvez même utiliser votre propre IDE au lieu de compter sur Configuration Center pour écrire vos scripts.
Détection de fraude
Analysez les modèles de transactions en temps réel pour identifier et bloquer les activités frauduleuses
Tarification dynamique
Calculez les prix à la volée en fonction de la demande, des stocks et des conditions du marché
Transformation des données
Filtrez, remodelez et enrichissez les données provenant de plusieurs sources dans des formats unifiés
Analyse en temps réel
Regroupez et calculez des métriques sur les données en streaming pour des informations instantanées
Alerte intelligente
Détectez les anomalies et déclenchez des notifications en fonction de règles métier personnalisées
Orchestration d'événements
Coordonner des flux de travail complexes en plusieurs étapes sur des systèmes distribués
Ce ne sont que des exemples. Le système ne se limite pas à ces cas d'utilisation: implémentez tout ce dont votre entreprise a besoin avec une prise en charge complète du langage de programmation et des hooks de cycle de vie pour les flux, les transactions et les messages.
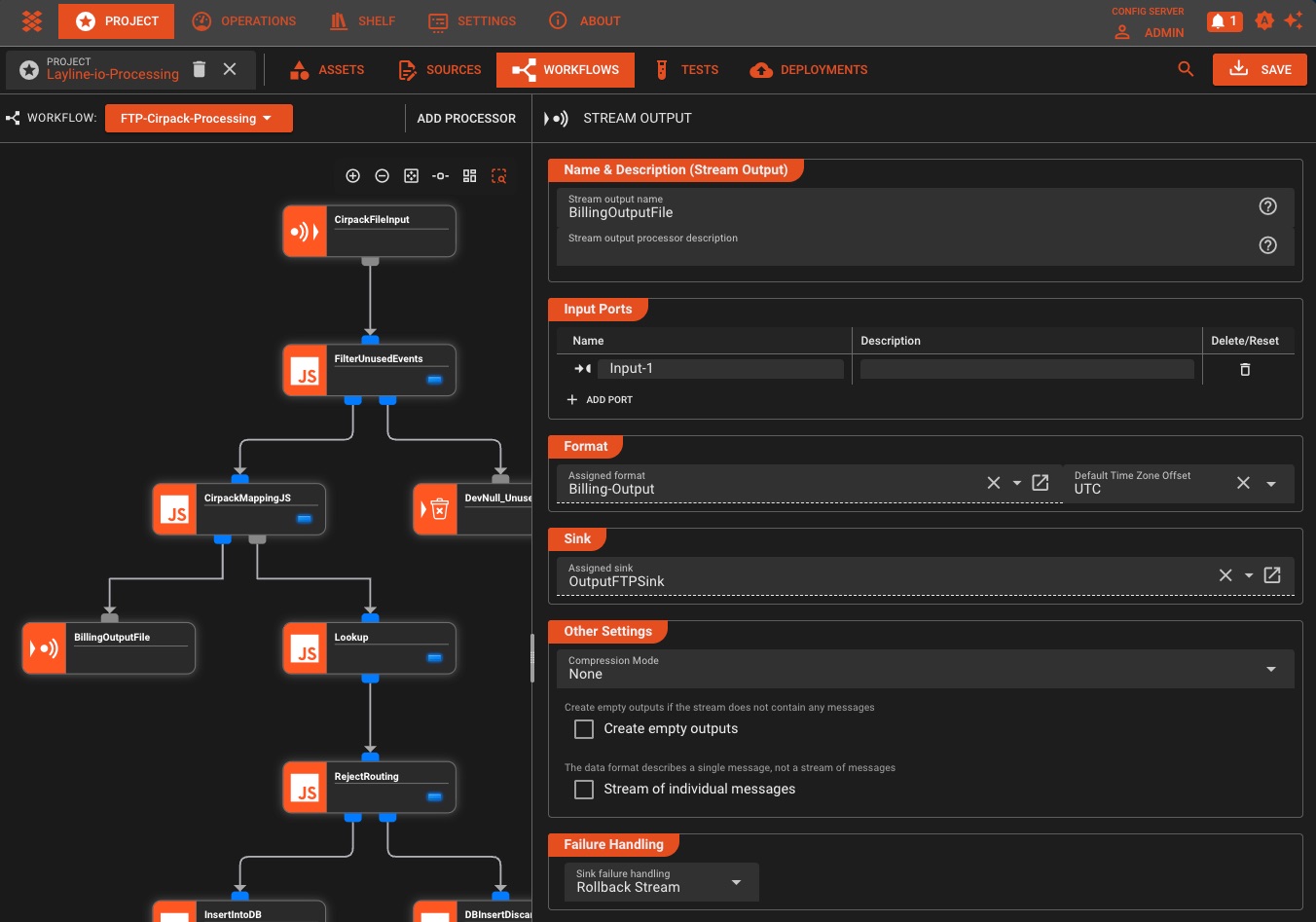
Déploiement et orchestration
Déployez n'importe où: cloud, périphérie ou sur site avec des mises à jour sans temps d'arrêt
Déploiement de cluster en un clic
Déployez sur n'importe quel cluster en un seul clic: pas de ligne de commande, pas de configuration complexe, juste une gestion visuelle intuitive du déploiement
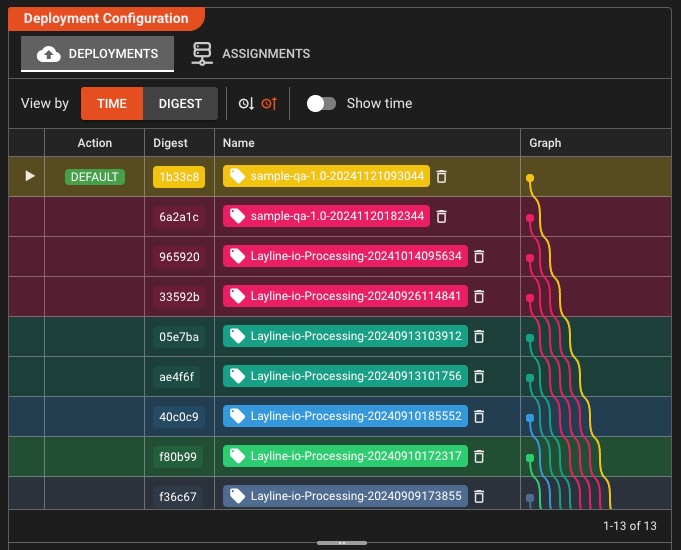
Déploiement simplifié
- Déploiement en un clic sur n'importe quel cluster
- Propagation automatique des configurations à l'échelle du cluster
- Aucune ligne de commande ni configuration complexe nécessaire
- Conseils de déploiement visuel
- Attribuer des déploiements à des nœuds de cluster spécifiques
Gestion des versions
- Historique de déploiement complet stocké dans le cluster
- Basculement fluide et sans temps d'arrêt entre les versions
- Retour instantané à tout déploiement précédent
- Mises à jour incrémentielles des déploiements existants
Docker Conteneurs
Packager les flux de travail sous forme de conteneurs légers
- Docker Compose prise en charge
- Images multi-arcades (x86/ARM)
- Images de base minimales
Maillage multirégion
Clusters géo-distribués avec basculement automatique
- Réplication interrégionale
- Basculement automatique
- Équilibrage de charge
- Localité des données
Enterprise: Déployez sur tous les continents avec une latence de synchronisation <10ms
CI/CD Intégration de pipelines
Déployez à partir de CLI avec une automatisation scriptable pour une intégration transparente CI/CD
- Déploiements à une seule commande avec indicateurs
- Scriptable par Shell pour l'automatisation
- Codes de sortie pour l'intégration du pipeline
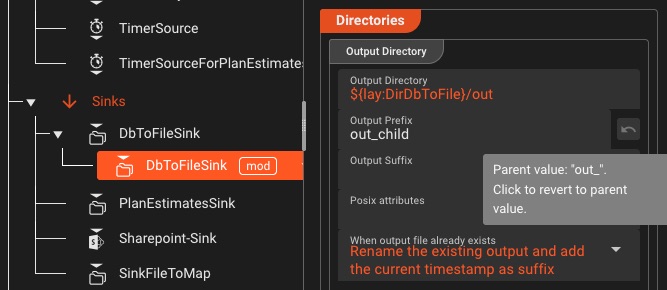
Configurations de déploiement granulaire
Créez une fois, configurez plusieurs: créez des compositions de déploiement réutilisables adaptées à chaque environnement sans dupliquer les flux de travail.
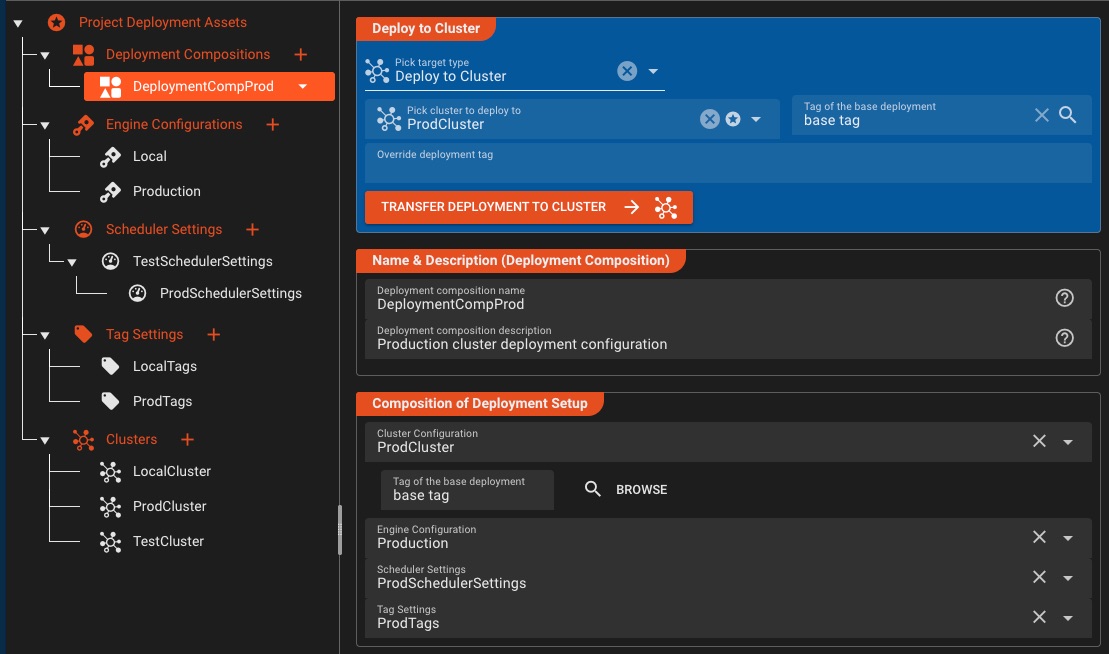
Configurations composables
- Configurations du moteur par environnement
- Paramètres du planificateur pour le contrôle de l'instance
- Paramètres de balise pour le ciblage du déploiement
- Les compositions de déploiement combinent toutes les configurations
Flexibilité de l'environnement
- Remplacer les secrets par environnement
- Remplacements de variables spécifiques à l'environnement
- Choisir le cluster de destination à la demande
- Gérer les configurations de test, de développement et de production de manière indépendante
Déployez avec précision: Mélangez et faites correspondre les configurations de moteur, les paramètres du planificateur et les configurations de balises pour créer des compositions de déploiement qui s'adaptent parfaitement à chaque environnement, sans duplication de flux de travail.
Planification dynamique du flux de travail
Faites évoluer les instances de workflow à la demande et répartissez intelligemment la puissance de traitement sur votre cluster.
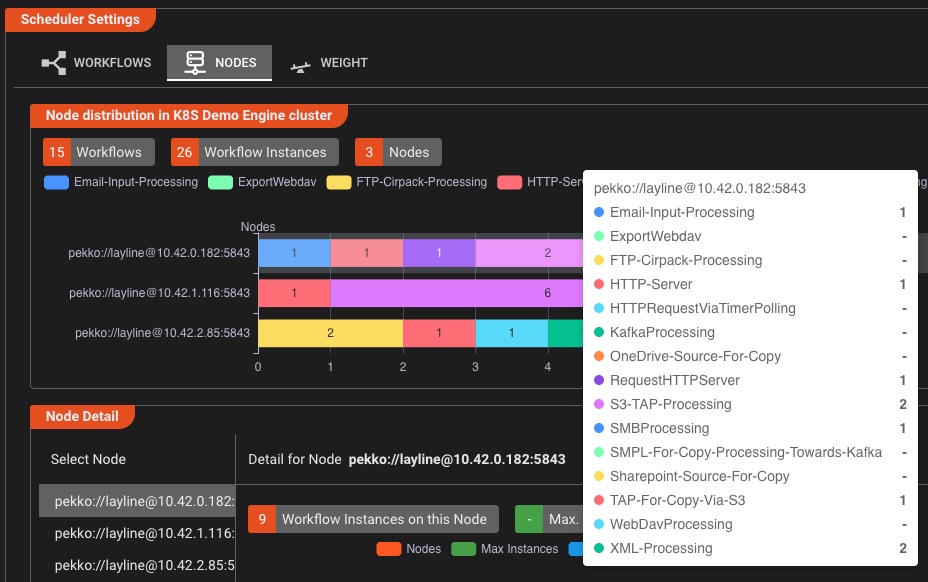
Mise à l'échelle intelligente
- Ajustez les instances de workflow en un seul clic
- Définir les limites min/max des instances
- Définir la priorité de la puissance de traitement par workflow
- Mise à l'échelle en temps réel sans temps d'arrêt
Répartition des clusters
- Visualisez la répartition de la charge sur les nœuds
- Épingler des workflows à des nœuds de cluster spécifiques
- Équilibrez automatiquement les charges de travail
- Surveiller la distribution des instances en temps réel
Évoluez en toute confiance: Augmentez ou réduisez les instances de flux de travail à la volée, attribuez des charges de travail spécifiques à des nœuds dédiés et optimisez l'allocation de la puissance de traitement, le tout à partir d'une interface visuelle intuitive.
Enterprise Sécurité et cryptage
Sécurité Zero Trust avec chiffrement à clé publique-privée: protégez les secrets des développeurs tout en maintenant un accès sécurisé
- Chiffrement à clé publique-privée
- Stockage de sécurité centralisé
- Certificats d'identité et de confiance
- Accès secret basé sur les rôles
- Authentification du système tiers
- plus...
Zéro confiance dès la conception: Seuls ceux qui disposent de clés privées peuvent déchiffrer les secrets: les développeurs restent productifs sans être exposés à des informations d'identification sensibles.
Mises à jour sans temps d'arrêt et changement de version instantané
Mettez à jour les workflows en cours sans supprimer un seul événement: le cluster conserve toutes les versions de déploiement, passez à n'importe laquelle en un seul clic.
Changement de version
Le cluster stocke toutes les versions: passez à n'importe laquelle en un seul clic
Sorties Canaries
Acheminer 5 % du trafic à tester avant le déploiement complet
Restauration instantanée
Revenir à la version précédente en moins d'une seconde
Bilans de santé
Validation automatique avant le changement de trafic
Observabilité et débogage
Visibilité complète sur vos pipelines de données avec surveillance et débogage en temps réel
Tableaux de bord de surveillance en temps réel
Mesures de performances en direct et informations visuelles pour chaque flux de travail
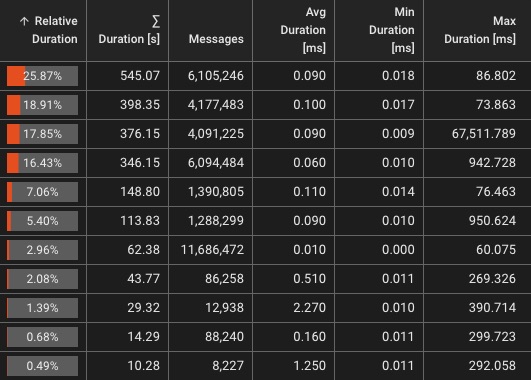
Métriques en direct
- Débit (événements/s)
- Taux et types d'erreurs
- Métriques des messages
Visualisations
- Répartition de la charge du flux de travail
- Diagrammes de flux en direct
- Débit par processeur
Message Sniffing
Inspectez les données en direct circulant dans vos pipelines
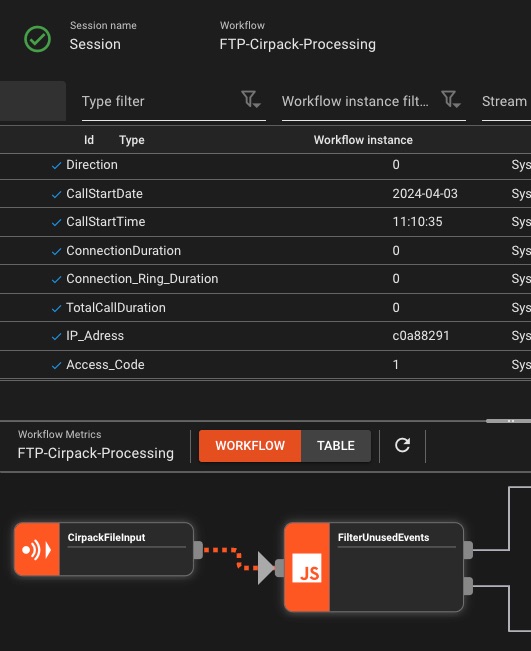
- Capture de messages en temps réel
- Filtrer par contenu/métadonnées
- Affichage compatible avec le format
- Exporter des échantillons
Conseil de pro: Sniff à n'importe quel processeur pour voir les transformations en action
Prometheus Métriques & OpenTelemetry
Observabilité conforme aux normes de l'industrie qui s'intègre à votre pile existante
Inspecteur d'état du moteur en direct
Explorez les ports du cluster jusqu'aux ports de processeur individuels: voyez exactement ce qui est déployé et en cours d'exécution, sans fichiers sources
- Vue de déploiement hiérarchique
- Distribution du flux de travail aux nœuds
- Nombre d'instances par nœud
- Inspection d'état au niveau du processeur
- Visibilité des configurations
- État de la connexion et du service
Transparence de la production: Inspectez ce qui s'exécute réellement en production, des flux de travail jusqu'aux ports individuels, même sans fichiers sources du projet. Parfait pour le dépannage et la vérification du déploiement.
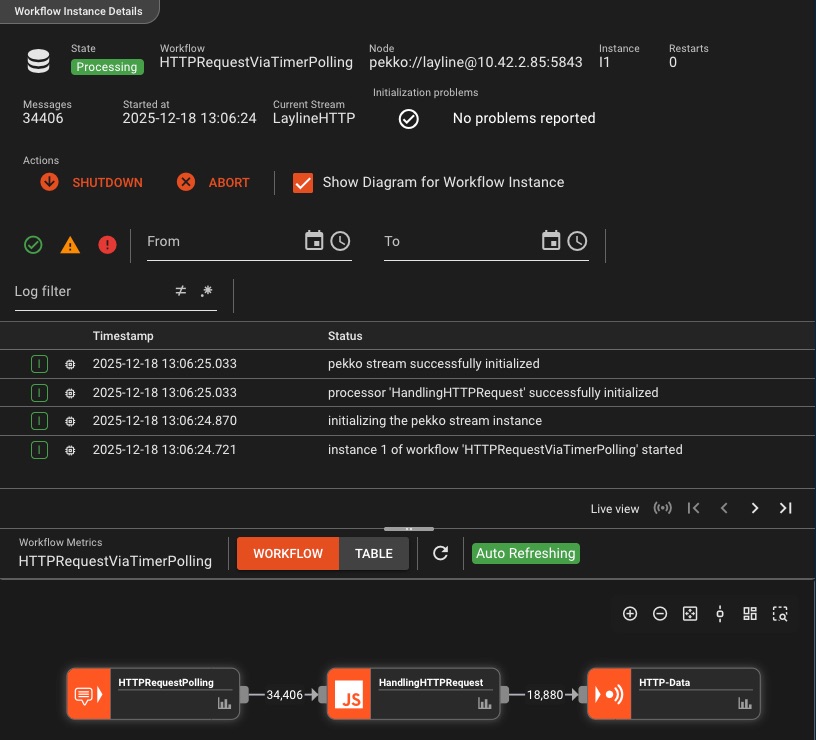
Journalisation complète et piste d'audit
Chaque action, chaque événement, chaque erreur, entièrement journalisé et traçable avec une visibilité granulaire par instance
Visibilité granulaire
- Journalisation d'instance par workflow
- Détails d'exécution au niveau du flux
- Suivi du statut et de l'état
- Contexte d'erreur et traces de pile
Contrôle et personnalisation
- Messages de journalisation personnalisés
- Démarrer/arrêter les instances de workflow
- Filtrer par gravité et source
- Historique complet des audits
Ne perdez jamais le contexte: De l'initialisation à l'arrêt, chaque action du flux de travail est enregistrée avec des horodatages précis, permettant un dépannage rapide et une transparence opérationnelle totale.
Débogage de scripts en direct en production
Déboguez les workflows en cours d'exécution sur n'importe quel nœud de cluster avec des points d'arrêt, une exécution pas à pas et une manipulation des variables d'exécution, tout comme le DevTools de votre navigateur.
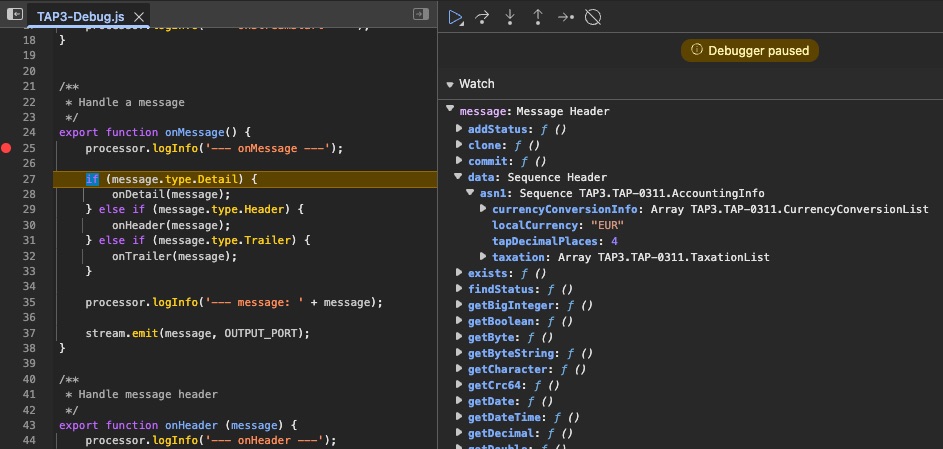
Débogage interactif
- Définir des points d'arrêt dans n'importe quel script
- Parcourez le code ligne par ligne
- Suspendre le flux de travail au point d'arrêt
- Reprendre ou accéder à des fonctions
Inspection et manipulation du temps d'exécution
- Inspecter toutes les variables et données de message
- Modifier les valeurs au moment de l'exécution
- Testez les cas extrêmes à la volée
- Déboguer sur n'importe quel nœud de cluster
Débogage de niveau production: Connectez-vous aux flux de travail en direct, définissez des points d'arrêt et inspectez les messages réels à mesure qu'ils circulent dans votre pipeline, sans redéploiement. Modifiez les variables à la volée pour tester les correctifs instantanément.
Tests de fonction de service interactif
Testez les fonctions du service de manière isolée: exécutez des requêtes de base de données, envoyez des e-mails ou appelez APIs directement depuis le tableau de bord sans exécuter de workflows.
- Exécuter des fonctions de manière interactive
- Remplissez les paramètres à la volée
- Validation instantanée des résultats
- Testez les requêtes DB en direct
- Valider n'importe quelle fonction de service
- Aucun flux de travail requis
Testez plus intelligemment, pas plus difficile: Pourquoi reconstruire et redéployer des flux de travail entiers simplement pour vérifier une requête de base de données ou toute autre fonction de service? Testez les fonctions du service de manière indépendante, itérez rapidement et expédiez en toute confiance.
Alertes et notifications intelligentes
Soyez averti lorsque les choses tournent mal, avant que vos utilisateurs ne le remarquent
Alertes de seuil
Déclenchement sur latence, taux d'erreur, anomalies de débit
Santé du flux de travail
État du flux, échecs d'instance, disponibilité des nœuds
Cibles dynamiques
Définir des cibles d'alarme à la volée: email, Teams, etc.
Règles d'alerte personnalisées
Créer des modèles, des règles et des groupes cibles
S'intègre avec Votre pile
Intégration basée sur des normes avec des outils et protocoles populaires
Explorer Plus loin
En savoir plus sur les cas d'utilisation, les tarifs et comment layline.io répond à vos besoins
Présentation du produit
Découvrez l'architecture réactive, les capacités de la plateforme et les fondements techniques de layline.io
Apprendre encore plusSolutions industrielles
Découvrez comment les équipes des secteurs de la finance, des télécommunications, du commerce électronique et bien d'autres encore utilisent layline.io
Explorer les solutionsPourquoi layline.io?
Comparez layline.io à d'autres plateformes et voyez comment nous nous situons
Voir la comparaisonPrêt à commencer?
Essayez Community Edition gratuitement ou planifiez une démo avec notre équipe
CommencerAnalyses approfondies des fonctionnalités et tutoriels
Découvrez comment tirer le meilleur parti des puissantes fonctionnalités de layline.io

L'écart de productivité de l'IA : Pourquoi les chiffres ne correspondent pas
Chaque tableau de bord d'entreprise affirme que l'IA transforme l'entreprise. Les chiffres réels de productivité racontent une histoire très différente — et comprendre pourquoi est important pour chaque équipe prenant des décisions d'investissement dans l'IA.

L'Ingénieur de Données IA : Ce qui a Vraiment Changé (Et Ce qui n'a Pas Changé)
Chaque blog concurrent publie 'L'IA change l'ingénierie des données.' Tout est exalté et vague. Voici l'inventaire honnête — ce que les outils LLM aident réellement, ce qu'ils ne peuvent toujours pas toucher, et pourquoi les affirmations de '80% d'automatisation' ne survivent pas au contact avec la production.

Les contrats de données sont la versionnage d'API dont votre Data Pipeline a besoin
La dérive de schéma continue de casser les pipelines parce que nous surveillons les changements au lieu d'appliquer des contrats. Voici pourquoi les contrats de données sont la couche manquante entre vos producteurs et consommateurs.