Du chaos des données
à des analyses en temps réel
Créez des pipelines de données réactifs avec un Visual Workflow Designer. Aucun code d'infrastructure, aucun enfermement propriétaire, juste un traitement des données rapide et fiable à grande échelle.
La réalité du ingénierie data
Construire des pipelines de données ne devrait pas exiger un doctorat en systèmes distribués. Pourtant, la plupart des ingénieurs data passent 80 % de leur temps à lutter avec l'infrastructure au lieu de résoudre des problèmes métier.
Complexité de l'infrastructure
Gestion de clusters Kafka, de déploiements Kubernetes et d'une supervision sur mesure sur plusieurs environnements. Votre équipe a besoin d'un ingénieur DevOps juste pour maintenir le service.
Leçons tirées de 50 post-mortems chez Uber, Netflix et Stripe ->
Cauchemars de verrouillage fournisseur
Des services spécifiques au cloud qui brillent en démonstration, mais vous enferment dans des écosystèmes propriétaires. La migration devient un projet à six chiffres.
Temps de mise en production
Des semaines ou des mois pour déployer un simple pipeline de transformation. Au moment de la mise en ligne, les besoins métier ont déjà changé deux fois.
Débogage de boîtes noires
Quand les pipelines tombent à 3 h du matin, vous plongez dans des systèmes d'agrégation de logs répartis sur des services distribués. Trouver la cause racine ressemble à de l'archéologie numérique.
Découvrez les 4 schémas de défaillance issus de 50 post-mortems ->
Goulots d'étranglement à l'échelle
Ce qui tient 1M d'événements ne se comporte pas du tout pareil à 10M d'événements. Vous réécrivez toute votre architecture de pipeline à chaque phase de croissance.
Comment les pics de charge ont provoqué 24 % des incidents à grande échelle ->
Collaboration d'équipe
Les analystes métier ne comprennent pas vos configurations Kafka. Les scientifiques des données ne peuvent pas déployer leurs modèles. Tout le monde travaille en silos.
Cela vous parle ?
Vous êtes devenu ingénieur data pour intégrer de l'intelligence aux processus métier, pas pour devenir ingénieur fiabilité site à plein temps. Il existe une meilleure approche.
Voir la solutionFlux de travail visuels.
Résultats concrets.
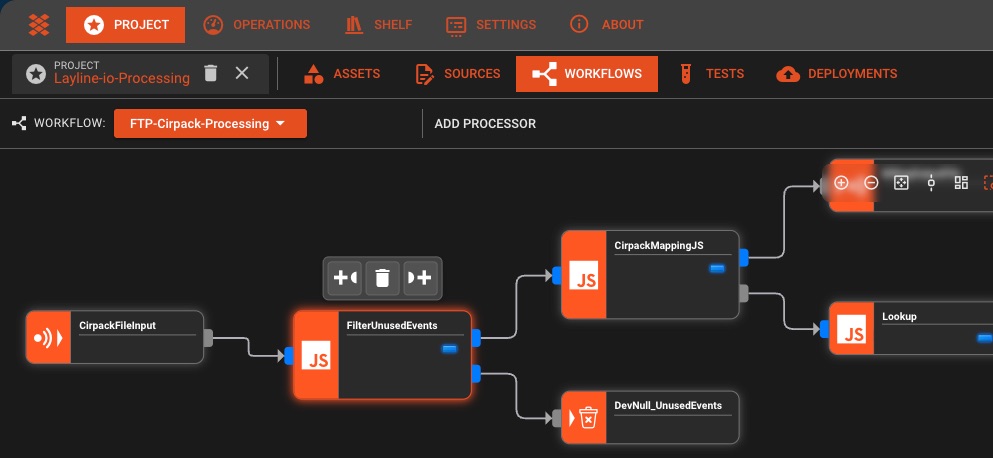
Créez des pipelines de données en reliant des blocs plutôt qu'en écrivant du YAML. Suivez vos données en temps réel grâce à une supervision et une gestion des erreurs intégrées.
Concepteur glisser-déposer
Création visuelle de pipelines avec processeurs configurables. Aucun code nécessaire, il suffit de relier les éléments.
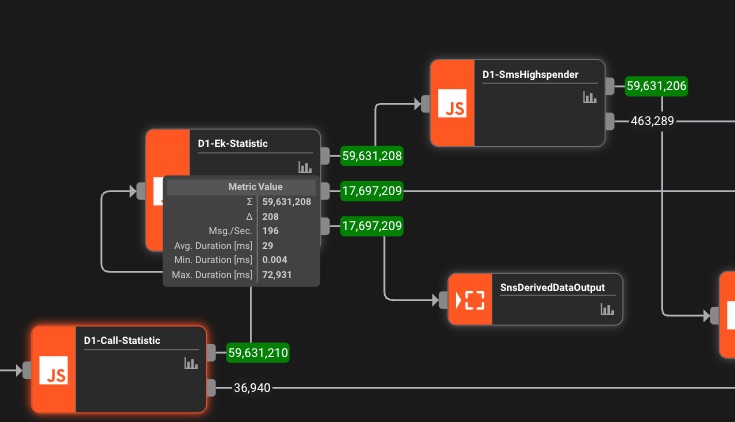
Supervision en temps réel
Métriques en direct, suivi des erreurs et analyses de performance. Voyez exactement ce qui se passe dans votre pipeline.
Zéro gestion d'infrastructure
Fonctionne sur votre infrastructure ou la nôtre. Mise à l'échelle automatique, haute disponibilité et exploitation sans maintenance.
La révolution du
ingénierie data
Arrêtez de combattre l'infrastructure. Commencez à construire des solutions qui comptent vraiment.
Déployez en quelques minutes
Évitez des mois de mise en place d'infrastructure. Notre concepteur visuel vous permet de créer des pipelines de production plus vite qu'en écrivant un consommateur Kafka.
Dormez tranquille
Supervision intégrée, nouvelles tentatives automatiques et gestion des files de rejet. Vos pipelines s'auto-réparent pendant que vous vous concentrez sur la logique métier.
Montez en charge sans effort
Du prototype à l'échelle production. Gérez les pics de trafic sans réécrire de code ni provisionner de serveurs.
En résumé
Cessez de lutter contre l'infrastructure. Concentrez-vous sur ce qui fait réellement avancer votre entreprise.
"Enfin, une plateforme de données qui fonctionne vraiment."

Voyez layline.io
en action
De vraies solutions conçues par de vraies équipes d'ingénierie data dans tous les secteurs
Tableau de bord analytique en temps réel
Une entreprise e-commerce traite plus de 50 000 événements par seconde issus des clics web, achats et changements d'inventaire pour alimenter des tableaux de bord en direct et des moteurs de personnalisation.

Questions de ingénieurs data
Questions fréquentes sur la mise en œuvre du traitement de données en temps réel avec layline.io.
La plupart des ingénieurs data font traiter à layline.io leurs premiers flux de données en moins de 10 minutes. Notre constructeur visuel de pipelines et nos connecteurs prêts à l'emploi éliminent des semaines de développement spécifique.
layline.io se connecte aux bases de données, APIs REST, files de messages, systèmes de fichiers, plateformes de streaming et protocoles personnalisés. Il gère JSON, XML, ASCII, binaire, ASN.1, HTTP et bien plus via une configuration visuelle.
layline.io est conçu pour l'échelle entreprise et traite des millions d'événements par seconde grâce à la mise à l'échelle horizontale. Notre architecture distribuée garantit des performances constantes même pendant les pics de trafic, avec gestion intégrée de la backpressure.
Oui. Déployez sur site, dans n'importe quel cloud ou en hybride. layline.io fonctionne avec vos bases de données, data lakes, entrepôts de données et outils analytiques existants sans exiger de changement d'architecture.
Nous proposons support technique, documentation, tutoriels vidéo et accompagnement d'onboarding. Notre équipe aide les équipes d'ingénierie data à optimiser leurs pipelines en matière de performance et de fiabilité.
La tarification de layline.io évolue avec votre usage. Vous ne payez que ce que vous traitez, avec une structure prévisible qui grandit avec votre activité. Les offres entreprise incluent un support dédié et des SLA personnalisés.
Créez votre premier pipeline en quelques minutes
Téléchargez layline.io gratuitement et commencez à créer des pipelines de données réactifs sans la complexité habituelle. Aucune carte bancaire requise.
Ressources pour les ingénieurs data
Études de cas, guides techniques et bonnes pratiques pour construire des pipelines de données

L'écart de productivité de l'IA : Pourquoi les chiffres ne correspondent pas
Chaque tableau de bord d'entreprise affirme que l'IA transforme l'entreprise. Les chiffres réels de productivité racontent une histoire très différente — et comprendre pourquoi est important pour chaque équipe prenant des décisions d'investissement dans l'IA.

L'Ingénieur de Données IA : Ce qui a Vraiment Changé (Et Ce qui n'a Pas Changé)
Chaque blog concurrent publie 'L'IA change l'ingénierie des données.' Tout est exalté et vague. Voici l'inventaire honnête — ce que les outils LLM aident réellement, ce qu'ils ne peuvent toujours pas toucher, et pourquoi les affirmations de '80% d'automatisation' ne survivent pas au contact avec la production.

Les contrats de données sont la versionnage d'API dont votre Data Pipeline a besoin
La dérive de schéma continue de casser les pipelines parce que nous surveillons les changements au lieu d'appliquer des contrats. Voici pourquoi les contrats de données sont la couche manquante entre vos producteurs et consommateurs.