Ce que nous démontrons
Nous présentons un projet simple de layline.io qui lit des données à partir d'un fichier et envoie son contenu dans un topic Kafka.
Pour suivre cette démonstration dans un environnement réel, vous pouvez télécharger les ressources de ce projet dans la section Ressources en bas de page. Lisez ceci pour apprendre comment importer le projet dans votre environnement.
Configuration
Le Workflow
Aperçu
La configuration du workflow de cette démonstration a été réalisée à l'aide de l'éditeur de Workflow de layline.io et ressemble à ceci :
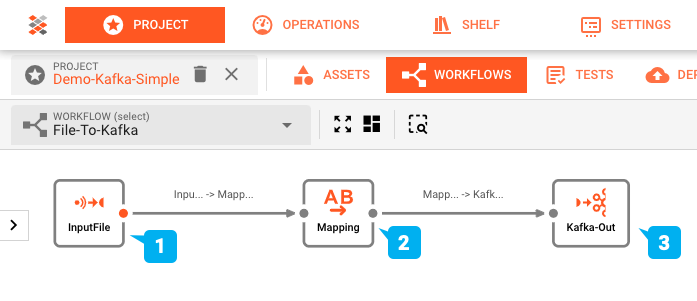
- (1) Input Processor : lecture d'un fichier d'entrée avec une structure en en-tête/détail/fin, puis
- (2) Flow Processor : mappage de ce fichier dans un format de sortie, qui est ensuite
- (3) Output Processor : écrit dans un topic Kafka.
Pour cette démonstration, nous utilisons un topic Kafka hébergé par Cloud Karafka. Ainsi, si vous exécutez la démonstration vous-même, vous n'avez pas besoin de votre propre installation Kafka.
Configuration des Assets sous-jacents
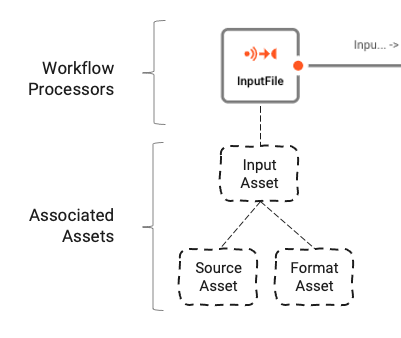
Le Workflow est basé sur un certain nombre d'Assets sous-jacents qui sont configurés à l'aide de l'Asset Editor. L'association logique entre le Workflow et les Assets peut être comprise comme suit :
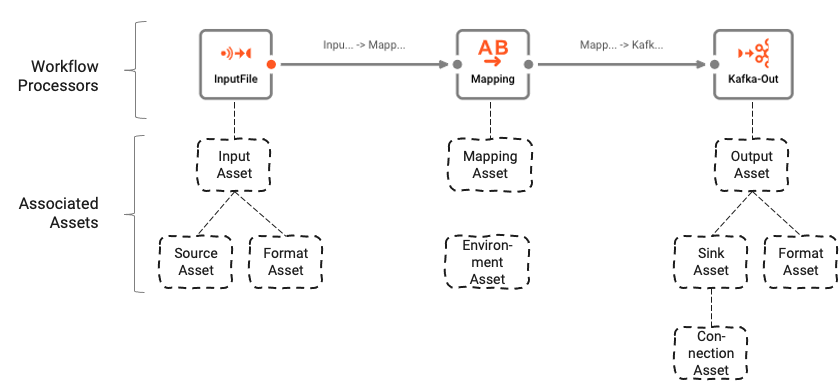
Les Workflows sont composés d'un certain nombre de Processors connectés par des liens.
Les Processors sont basés sur des Assets. Les Assets sont des entités de configuration qui appartiennent à une classe et un type spécifiques. Dans l'image ci-dessus, nous voyons un Processor nommé "InputFile", qui appartient à la classe Input Processor et au type Stream Input Processor. Il repose à son tour sur deux autres Assets, "Source Asset" et "Format Asset", qui sont respectivement de type File System Source et Generic Format.
En résumé :
- Un Workflow est composé de Processors interconnectés
- Les Processors dépendent d'Assets qui les définissent
- Les Assets peuvent dépendre d'autres Assets
Environment Asset : "My-Environment"
Premièrement : layline.io peut aider à gérer plusieurs environnements différents à l'aide des Environment Assets. Cela est très utile lorsque le même projet est utilisé dans des environnements de test, de préproduction et de production qui peuvent nécessiter des répertoires, connexions, mots de passe, etc., différents. Nous utilisons un Environment Asset (2) dans ce projet.
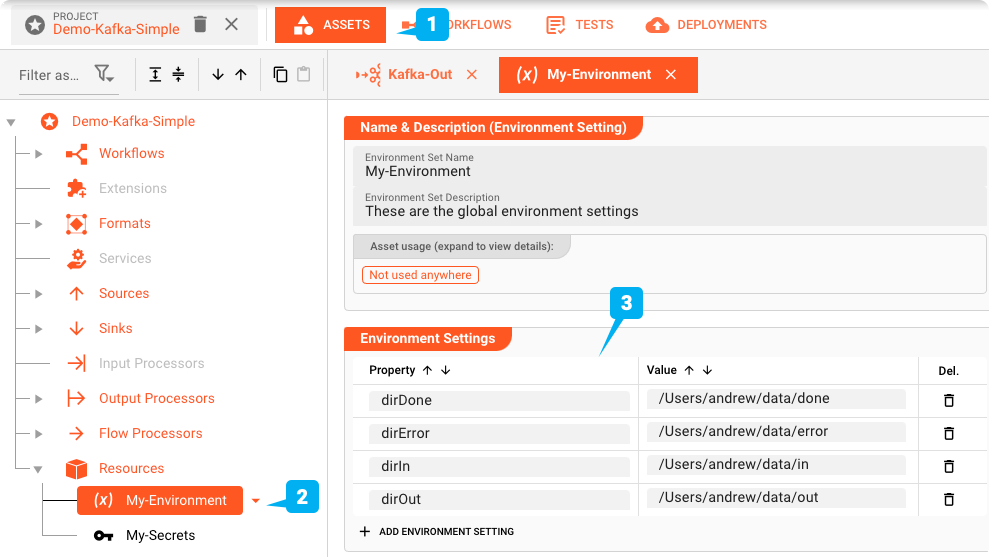
Des variables comme celles-ci peuvent être utilisées dans tout le projet en utilisant une macro comme ${lay:dirIn}. Les variables d'environnement du système d'exploitation ou de Java sont préfixées par env: ou sys: respectivement, au lieu de lay:.
Stream Input Processor : "InputFile"
Le Input Processor (nom : InputFile / type : Stream Input Processor) s'occupe de lire les fichiers d'entrée et de transmettre les données en aval dans le Workflow.
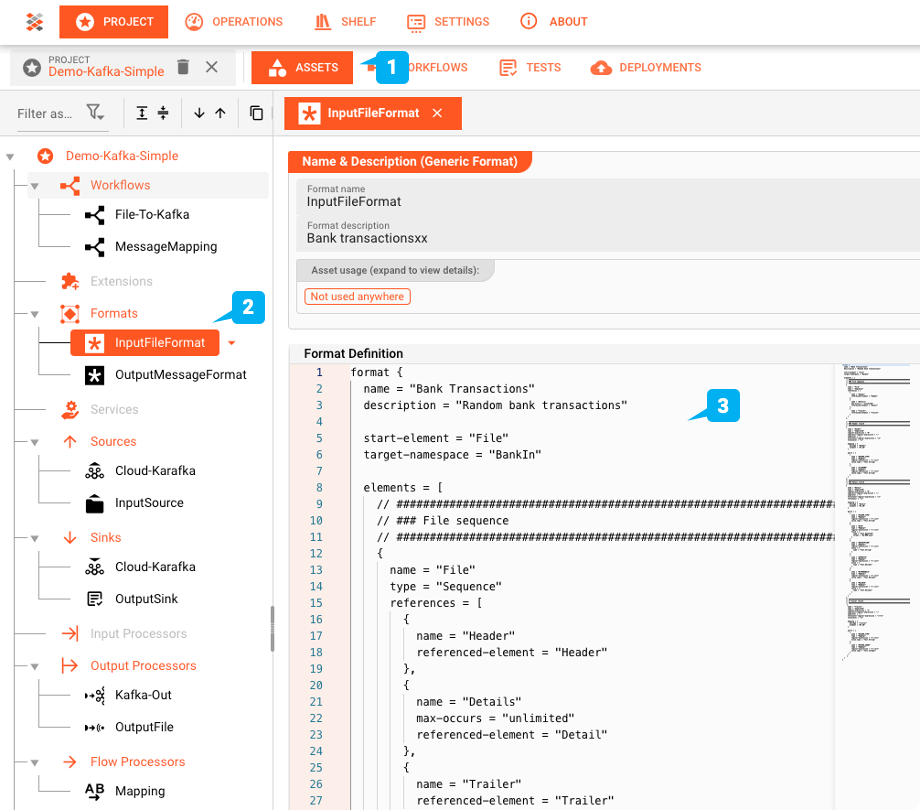
Generic Format Asset : "InputFileFormat"
layline.io fournit les moyens de définir des structures de données complexes avec son propre langage de grammaire. Le fichier dans notre exemple est un échantillon de transactions bancaires. Il contient un enregistrement d'en-tête avec deux champs, un certain nombre d'enregistrements de détail contenant les détails des transactions, et enfin un enregistrement de fin.
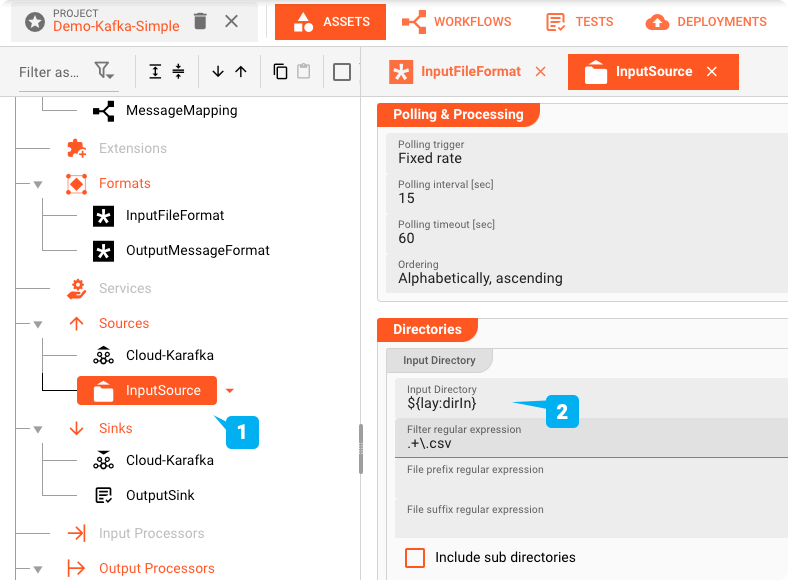
File-System-Source Asset : "InputSource"
L'Asset "InputSource" est un Asset de type File System Source qui est utilisé pour définir l'emplacement de lecture du fichier.
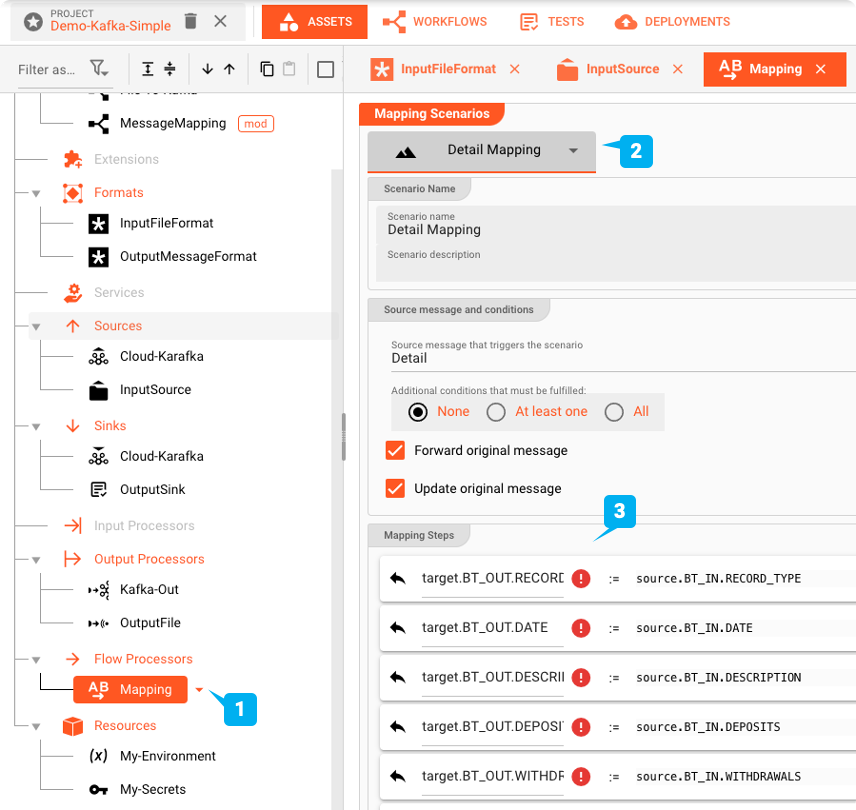
Flow Processor : Map
Le Mapping Asset permet de mapper les valeurs du format d'entrée au format de sortie.
Stream Output Processor : Kafka
Le dernier Processor du Workflow est l'Output Processor "Kafka-Out".
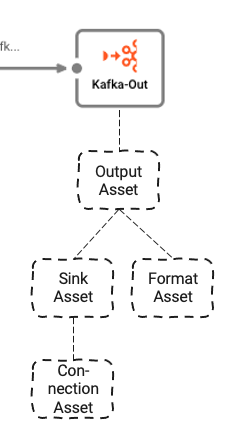
Il dépend de trois Assets sous-jacents :
- Output Asset : Définit les topics Kafka et partitions auxquels nous écrivons
- Kafka Sink Asset : Le Sink que l'Output Asset peut utiliser pour envoyer des données
- Generic Format Asset : Définit le format dans lequel écrire les données dans Kafka
- Kafka Connection Asset : Définit les paramètres physiques de connexion à Kafka
Kafka Connection Asset : "Cloud-Karafka-Connection"
Pour écrire dans Kafka, nous devons d'abord définir un Kafka Connection Asset.
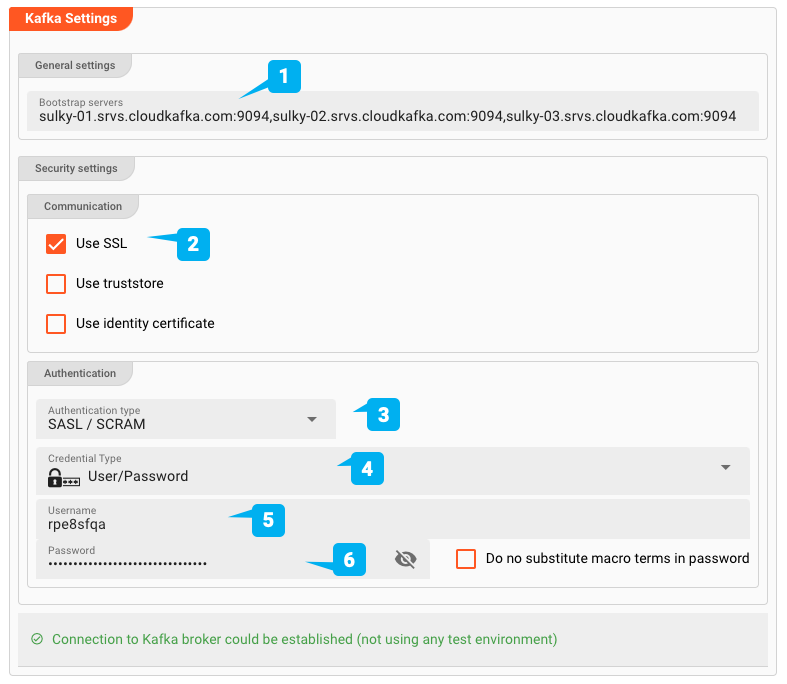
- (1) Bootstrap servers : Les adresses d'un ou plusieurs serveurs Bootstrap
- (2) Utiliser SSL : Définit si la connexion est SSL
- (3) Type d'authentification : SASL / Plaintext, ou SASL / SCRAM
- (4/5/6) Identifiants : Nom d'utilisateur/mot de passe
Déploiement et exécution
Transfert du déploiement
Pour déployer, nous passons à l'onglet DEPLOYMENT du projet :
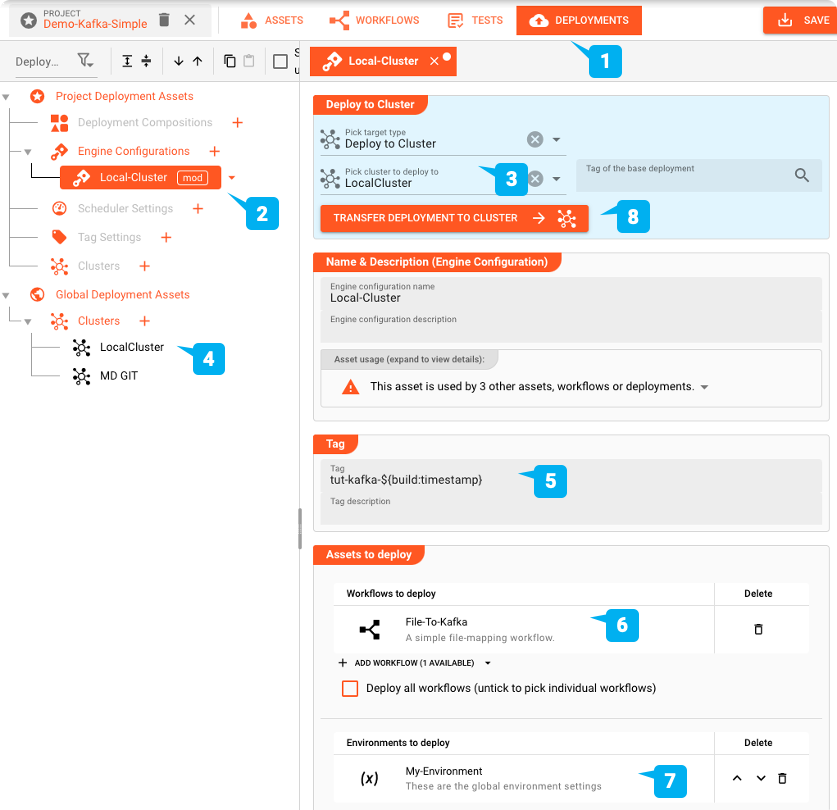
Nous créons une Configuration Engine pour déployer le projet. Cela définit les parties du projet que nous souhaitons déployer.
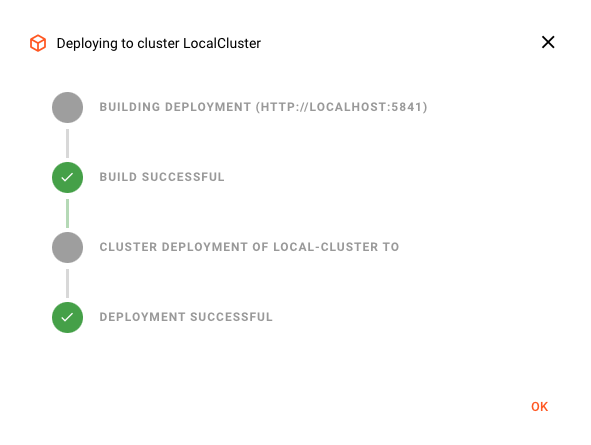
Activation du déploiement
Nous passons à l'onglet "CLUSTER" :
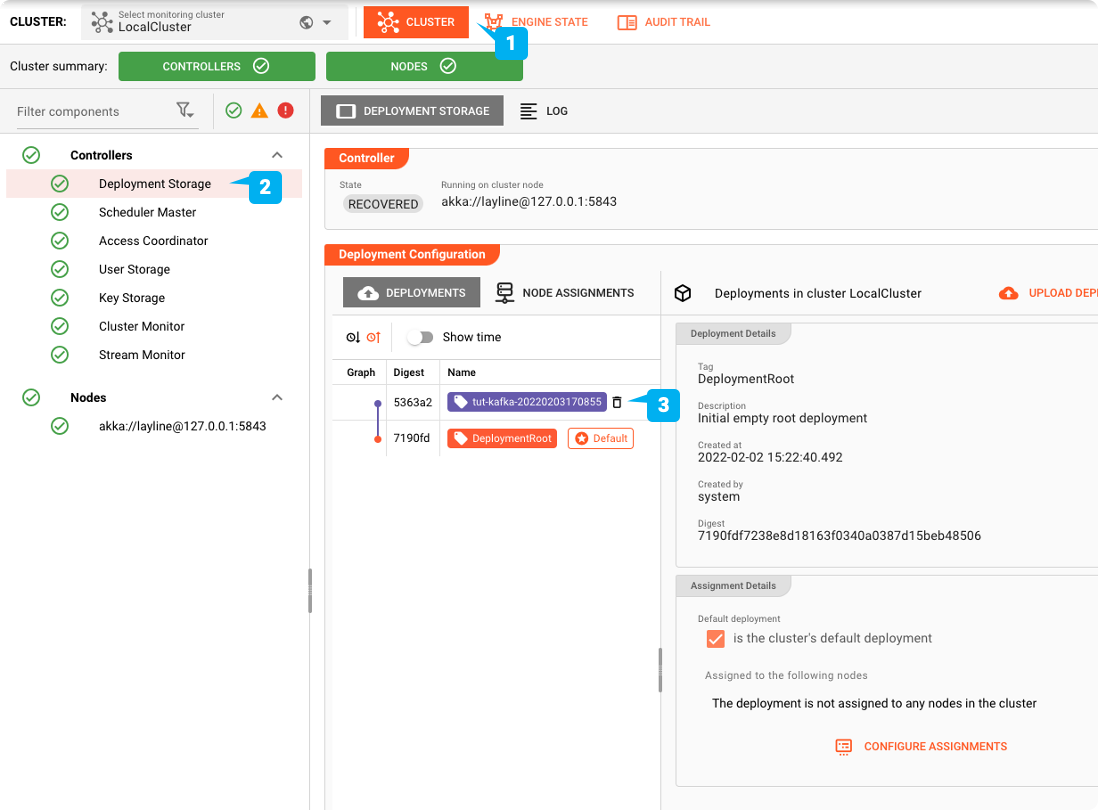
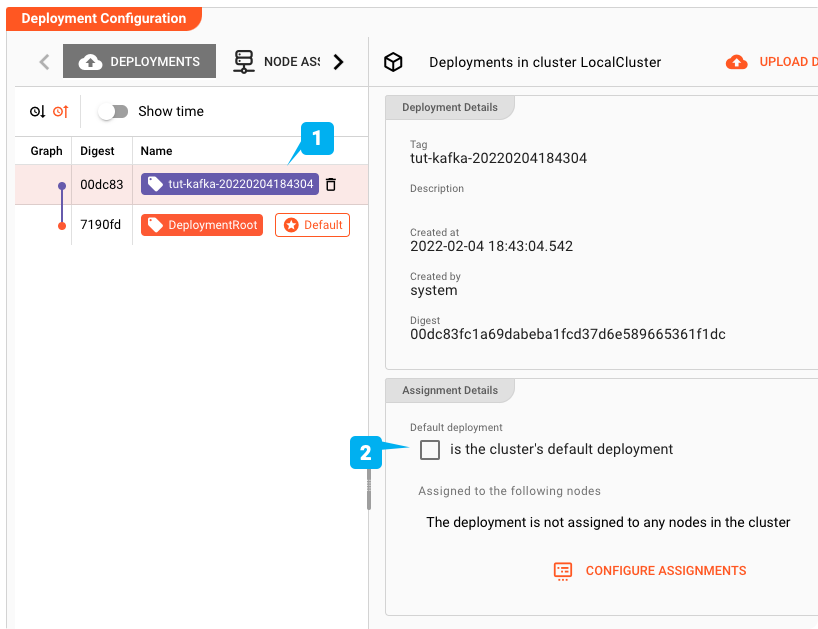
En faire le déploiement par défaut
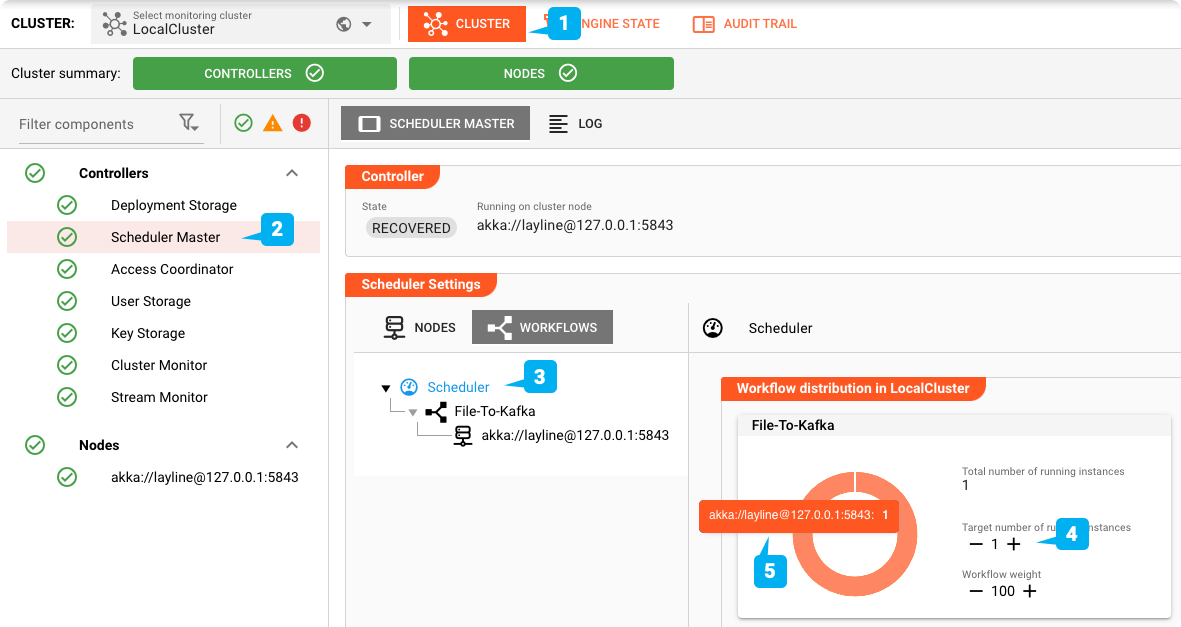
Planification
Statut de l'Engine
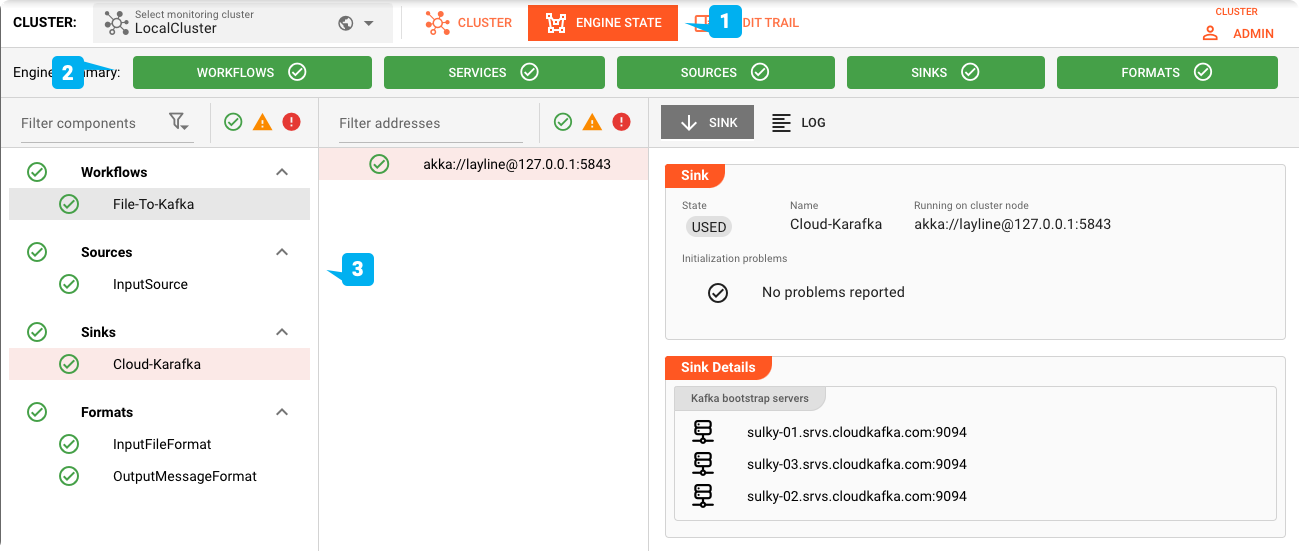
Alimentation du fichier de test
Pour tester, nous plaçons notre fichier de test dans le répertoire d'entrée que nous avons configuré.
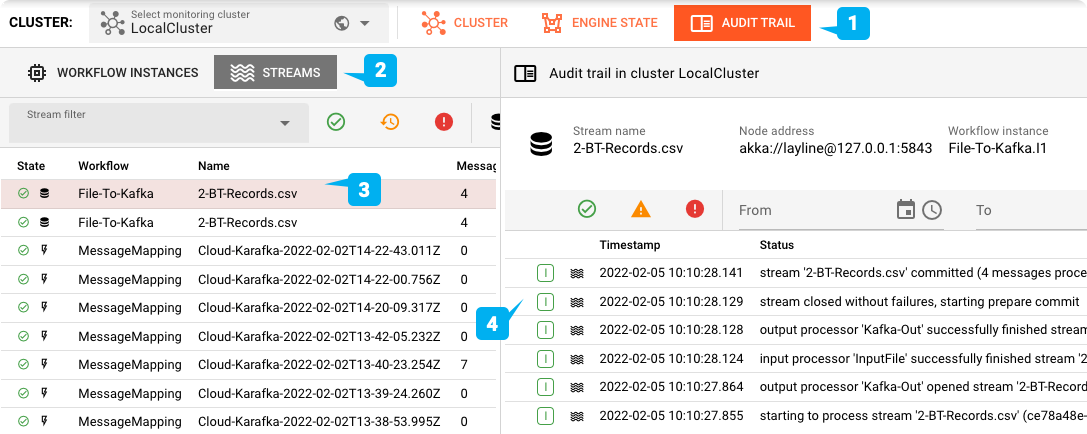
Vous pouvez vérifier le topic Cloud Karafka à l'aide de l'outil de votre choix :

Résumé
Cette démonstration met en évidence comment vous pouvez créer un Workflow File-to-Kafka à la volée sans difficulté. Et vous obtenez bien plus que cela dès la sortie de la boîte :
- Réactif — Adopte le paradigme de traitement réactif
- Haute scalabilité — S'adapte au sein d'une instance d'engine et au-delà
- Résilience — Tolérance aux pannes dans des environnements distribués
- Déploiement automatique — Déployez les configurations modifiées en un clic
- Temps réel et batch — Exécutez les deux sur la même plateforme
- Métriques — Génération automatique de métriques pour la surveillance (par exemple Prometheus)
Ressources
| # | Description |
|---|---|
| 1 | Github : Simple Kafka Project |
| 2 | fichiers de test d'entrée dans le répertoire _test_files du projet |
| 3 | Identifiants Cloud Karafka dans le fichier cloud-karafka-credentials.txt |
| # | Documentation |
|---|---|
| 1 | Getting Started |
| 2 | Importing a Project |
| 3 | What are Assets, etc? |
- En savoir plus sur layline.io ici.
- Contactez-nous à hello@layline.io.