
Comment layline.io se compare-t-il à Kafka ?
C'est une question que nous entendons de temps en temps. Nous nous demandons pourquoi. Pour mieux comprendre, examinons ce qu'est Kafka :
Qu'est-ce que Kafka ?
Voici comment AWS le décrit :
"Apache Kafka est un magasin de données distribué optimisé pour l'ingestion et le traitement de données en streaming en temps réel. Les données en streaming sont des données générées en continu par des milliers de sources de données, qui envoient généralement les enregistrements de données simultanément. Une plateforme de streaming doit gérer cet afflux constant de données et traiter les données de manière séquentielle et incrémentale.
Kafka fournit trois fonctions principales à ses utilisateurs :
- Publier et s'abonner à des flux d'enregistrements.
- Stocker efficacement les flux d'enregistrements dans l'ordre dans lequel les enregistrements ont été générés.
- Traiter les flux d'enregistrements en temps réel.
Kafka est principalement utilisé pour construire des pipelines de données en streaming en temps réel et des applications qui s'adaptent aux flux de données. Il combine la messagerie, le stockage et le traitement de flux pour permettre le stockage et l'analyse des données historiques et en temps réel."
Notre point de vue sur Kafka
Il y a un peu de jargon technique dans la description ci-dessus que nous devons aborder. Elle parle de traitement en streaming, de temps réel, etc. Que signifie tout cela dans le contexte de Kafka ?
- Kafka est d'abord une solution de stockage de données. Il doit être considéré comme un type spécial de base de données dans laquelle les données sont stockées dans des files d'attente (sujets). Il existe diverses manières d'écrire dans ces files d'attente (publier) et de les lire (s'abonner). Les files d'attente suivent le principe FIFO (premier entré, premier sorti). Certains soutiennent que Kafka n'est pas un magasin mais un processeur d'événements en streaming, mais cela est trompeur selon nous. Kafka est conçu pour stocker des données et permettre aux consommateurs de lire ces données rapidement. Il est conçu pour se débarrasser des données stockées après une période de rétention préconfigurée, que les données aient été consommées ou non. En ce sens, c'est un magasin de données temporaire avec quelques fonctionnalités très spéciales, bien que utiles.
- Les processus individuels peuvent publier dans des files d'attente (Producteurs) ou s'abonner à des files d'attente (Consommateurs). Si aucun des connecteurs prêts à l'emploi (voir ci-dessous) ne suffit comme producteur/consommateur pour votre besoin (probable), alors vous devez en coder un vous-même (la plupart utilisent Java, mais il existe d'autres options).
- Kafka peut fonctionner dans un environnement distribué natif du cloud, offrant résilience et évolutivité.
Confluent (l'entreprise) a ajouté quelques fonctionnalités supplémentaires à Kafka, telles que des "Connecteurs" préfabriqués. Les connecteurs sont des types spéciaux de producteurs et de consommateurs qui peuvent lire/écrire des types spéciaux de sources de données/éviers vers/depuis les sujets Kafka. Ils sont assez limités et spécialisés dans ce qu'ils peuvent faire.
En plus de cela, ils ont créé la capacité de "filtrer, router, agréger et fusionner" les données en utilisant "ksql". Cela suggère que vous pouvez filtrer et router les informations en temps réel à partir des sujets Kafka. Cela semble génial. Cependant, ce n'est qu'un autre type de consommateur qui lit les données d'un sujet Kafka, puis filtre, agrège, fusionne et route les résultats vers un autre sujet pour qu'un autre consommateur les lise. La meilleure façon de comparer cela logiquement est d'utiliser l'analogie d'une base de données pilotée par table (par exemple Oracle) dans laquelle vous copiez des données d'une table à une autre, en utilisant SQL ; sauf qu'avec Kafka, c'est beaucoup plus compliqué.
Kafka a quelques capacités, mais aucune capacité significative pour transformer les données. Un des grands obstacles ici est que Kafka n'a pas de capacité inhérente à analyser les données, et donc à pouvoir travailler dessus. Il ne prend en charge que très peu de formats de données limités. Tout ce qui sort de l'ordinaire (probable) nécessite un codage personnalisé des producteurs et des consommateurs pour faire le travail. Cela ressemble encore à toute autre base de données qui se soucie principalement des internes, pas des externes. Dans l'ensemble, il est juste de dire que Kafka ne traite pas réellement les données. Il se contente de stocker les données. Tout autre scénario implique de chaîner des sujets atomiques avec des producteurs et des consommateurs.
Kafka est également connu pour être plutôt difficile à utiliser. Il n'y a pas d'interface utilisateur complète. Pratiquement tout est configuré dans des fichiers de configuration et opéré à partir de la ligne de commande.
Résumé
L'utilisation principale de Kafka est pour :
- Stockage rapide de données
- Pour de grands volumes
- Qui sont à la fois produits et consommés rapidement
Nous aimons Kafka pour cet usage. C'est génial, et nous l'utilisons fréquemment dans les implémentations, même s'il existe plusieurs autres solutions pour atteindre cet objectif également.
Qu'est-ce que layline.io ?
layline.io est un processeur de données d'événements rapide, évolutif et résilient. Il peut ingérer, traiter et sortir des données en temps réel. Le traitement signifie "faire" quelque chose avec les données, contrairement à ce que fait Kafka (stocker). Une différence majeure avec Kafka, par exemple, est que dans layline.io tout tourne autour de la notion de "Workflows". Les Workflows reflètent une logique axée sur les données qui ressemble généralement à une orchestration complexe de données.
Cela se traduit par :
- interpréter les données,
- les analyser,
- décider et potentiellement les enrichir en consultant d'autres sources en temps réel
- créer des statistiques
- les filtrer,
- les router,
- intégrer des sources de données et des éviers autrement disparates.
et faire tout cela en :
- temps réel,
- transactionnellement sécurisé (option),
- sans surcharge de stockage,
- configurable,
- piloté par l'interface utilisateur
- et bien plus encore
Exemple de Workflow :
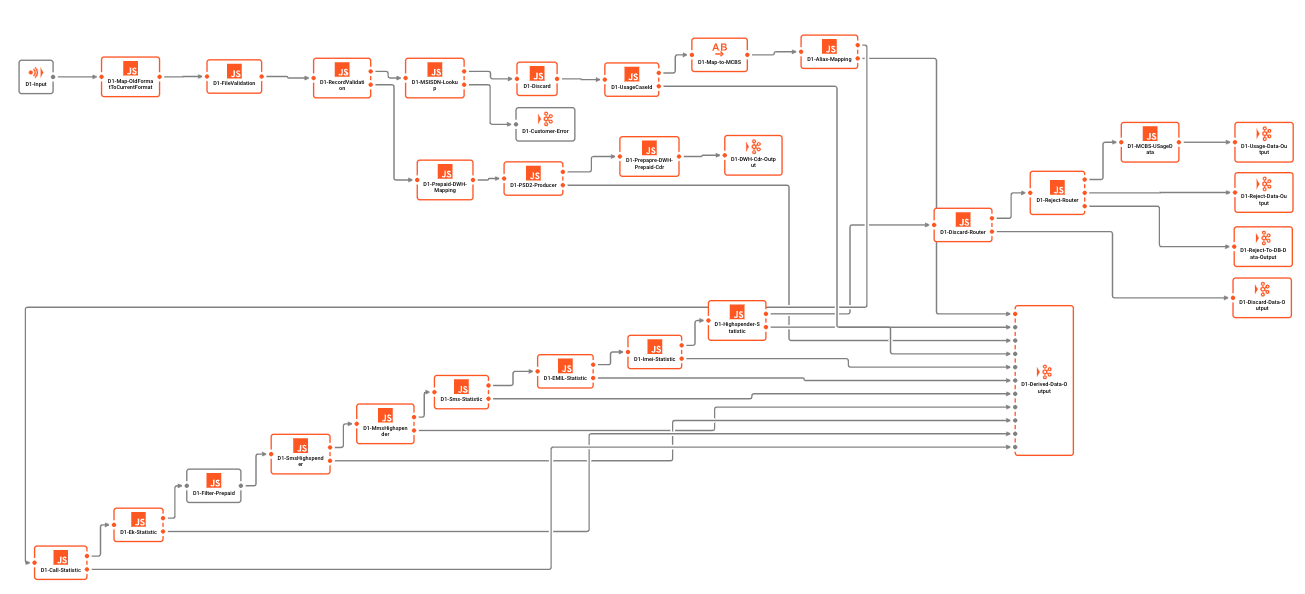
Kafka ne prend pas en charge les Workflows par conception. Tout ce qui peut être interprété comme un Workflow dans Kafka est plutôt une tentative de "vendre" un chaînage de files d'attente Kafka et de consommateurs / producteurs comme un Workflow. Notez cependant que chacun de ceux-ci est une entité individuelle qui n'est pas consciente des autres. Il n'y a pas de contrôle (transactionnel) global, ni de véritable support pour les Workflows au sein de Kafka.
Combiner Kafka et layline.io
Du point de vue de Kafka, cela signifie que layline.io est vu comme un producteur (écriture) ou un consommateur (lecture). Du point de vue de layline.io, Kafka est vu comme un magasin de données d'événements, comparable à d'autres magasins de données comme les bases de données SQL, les bases de données NOSQL, ou même le système de fichiers. C'est une excellente combinaison, selon le cas d'utilisation. layline.io dans ce contexte agit comme l'élément d'orchestration de données entre un nombre théoriquement illimité de sujets Kafka, et d'autres sources et éviers en dehors de la sphère Kafka.
Sous cet angle, Kafka et layline.io sont extrêmement complémentaires, pas compétitifs. Le chevauchement est minimal. Nous ne voyons pas de scénario significatif où un client potentiel choisirait entre l'un ou l'autre, mais plutôt pour l'un et l'autre.
Comment les utilisateurs de Kafka s'en sortent-ils aujourd'hui ?
L'utilisateur typique de Kafka aujourd'hui utilise Kafka pour ce qu'il est : Un type spécial de magasin de données d'événements. Pour écrire et lire des données vers/depuis celui-ci. Il code principalement sur mesure des consommateurs et des producteurs. Ces parties codées sur mesure doivent alors contenir les points 1 à 6 ci-dessus (indice : elles ne le feront pas). De plus, elles ne garantissent pas la résilience, l'évolutivité, le reporting, la surveillance et tout le reste qui devrait être attendu de tels composants. Elles sont souvent construites en utilisant des outils de script simples comme Python jusqu'à utiliser des frameworks de microservices plus sophistiqués comme Spring Boot et autres.
Au lieu de cela, ils pourraient simplement utiliser layline.io et obtenir tout ce qui précède.
Exemple de déploiement réel
Ce client réel utilise layline.io pour s'occuper du traitement de toutes les données d'utilisation des clients (métadonnées de communication).
Avant la mise en œuvre de layline.io, ils étaient dans une situation qui ressemblait beaucoup au scénario décrit dans le paragraphe précédent. Plusieurs files d'attente Kafka étaient alimentées par des processus codés sur mesure. D'autres processus de ce type lisaient à partir de ces files d'attente et écrivaient des données vers d'autres cibles dans d'autres formats et avec une certaine logique appliquée. Une architecture désordonnée et sujette aux erreurs, coûteuse à maintenir et presque impossible à gérer.
Après la mise en œuvre de layline.io, dans laquelle la logique métier et les processeurs précédents ont été remplacés, l'architecture ressemblait à ceci :
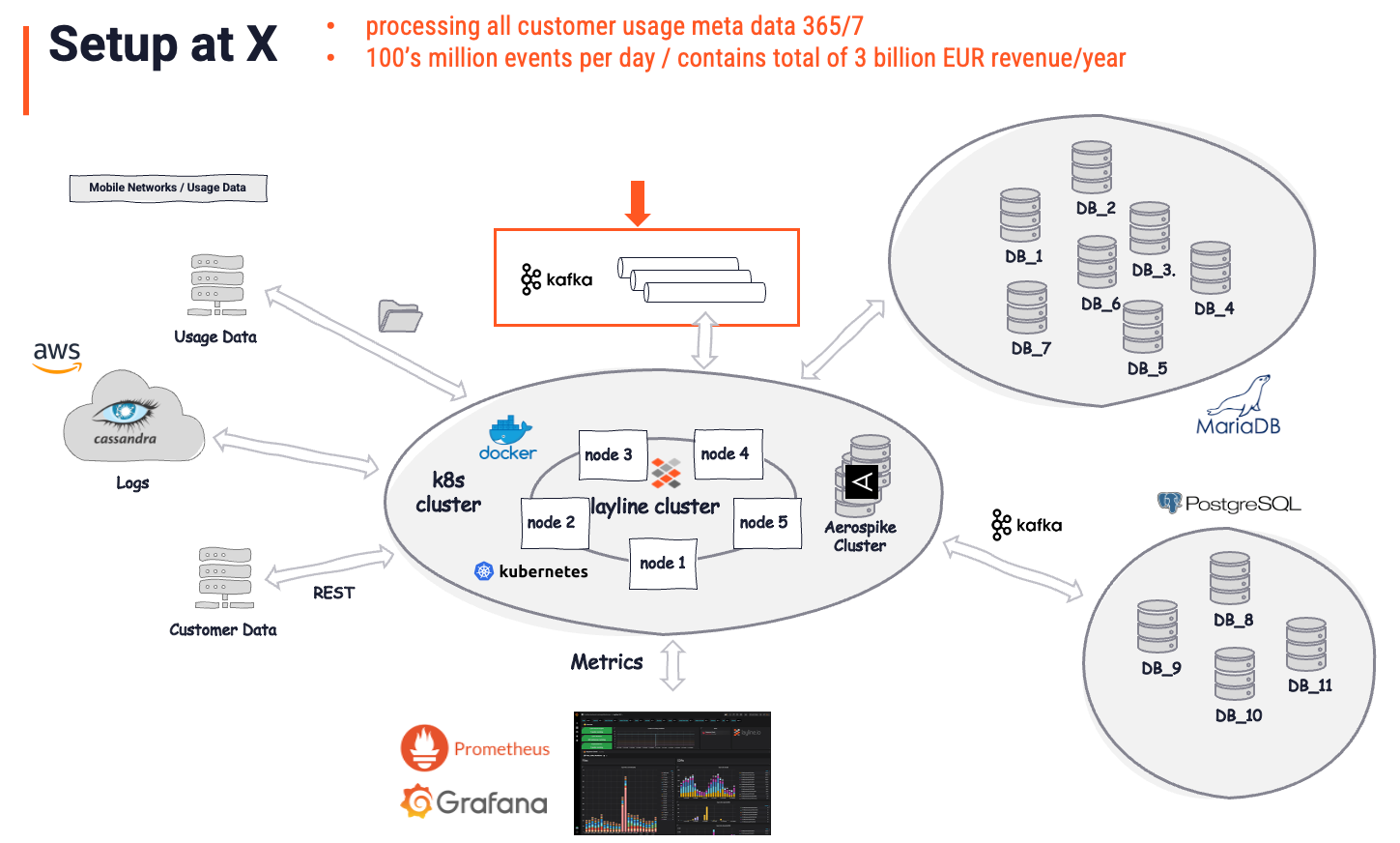
L'image globale est considérée comme la "Solution". Il est important de comprendre que layline.io est reconnu comme la véritable solution, tandis que Kafka n'est qu'un autre magasin (important). Kafka était là avant layline.io. Il joue un rôle comparativement petit (flèche et boîte rouges) dans la solution globale, cependant. Il sert de magasin de données intermédiaire, ce qui est exactement ce qu'il est par définition. Toute l'analyse intelligente des données, l'enrichissement, le filtrage, la transformation, le routage, la logique métier complexe, et bien plus encore est géré par layline.io. Une tâche à un niveau qui serait impossible à accomplir en utilisant Kafka. En demandant quelle part de cela est due à Kafka, la réponse du client serait probablement : "5% de la solution globale".
Conclusion
Kafka est largement considéré comme un bus de messages, mais il s'agit en réalité de données au repos facilitant d'autres applications pour mettre les données en mouvement. Dans ce contexte, l'application réelle du point de vue d'un utilisateur est quelque chose qui est alimenté par des données de Kafka en utilisant une API client. layline.io, au contraire, forme une partie intégrante de la logique de votre application, si ce n'est l'application elle-même (voir exemple). Vous pouvez imaginer layline.io comme le système circulatoire plus la logique, tandis que Kafka est juste un réservoir externe bien organisé. Le chevauchement entre Kafka et layline.io est donc minimal.
Un client qui utilise Kafka ne se demandera pas si layline.io pourrait avoir du sens "en plus de Kafka". De même, nous ne remettrions pas en question l'utilisation de Kafka comme magasin de données, seulement si ce serait le bon magasin de données pour le but. Les clients se demanderaient plutôt comment ils résolvent les problèmes (que Kafka n'aborde pas) en utilisant layline.io. Ils peuvent faire quelque chose de nouveau, ou remplacer des processus existants (par exemple, des microservices) qui ont été codés sur mesure dans une certaine mesure dans le passé.
Annexe : Comparaison rapide layline.io <> Kafka
Ce n'est pas une comparaison complète, mais cela aide :
| Aspect | Kafka | layline.io |
|---|---|---|
| Type | File de messages | Plateforme de concurrence |
| Support des Workflows | Pas vraiment. Juste un magasin. | Partie inhérente de la solution |
| Magasin de données | Oui | Non |
| Support des formats de données | Pas de compréhension des formats de données par défaut. Seulement dans le contexte avec ksql un support limité pour des formats tels que CSV, JSON, Avro, ProtoBuf. | Compréhension complète du contenu des données. Typé fortement. Support pour des formats de données extrêmement complexes, tels que ASCII et binaire, structures hiérarchiques, ASN.1 etc. |
| Logique métier | Pas de support | Support complet. C'est une différence majeure entre un magasin et une solution de traitement de données. |
| Enrichissement des données | Non supporté. Aucun tiers ne peut être consulté pour l'enrichissement des données. | Support complet. |
| Temps réel | Kafka est un magasin. Cela ne peut être aussi temps réel que ce qui lit les données du magasin (tampon). | Complet. Aussi temps réel que possible. Pas de stockage intermédiaire. Les données sont traitées et sorties instantanément. |
| Métriques personnalisées | Pas de métriques personnalisées spécifiques à votre cas d'utilisation | Tout type de métrique personnalisée (par exemple "4711 clients se sont inscrits au service y dans le dernier intervalle de temps") |
| Performance | Élevée | Élevée |
| Évolutif | Oui | Oui |
| Résilient / HA | Oui | Oui |
| Persistant | Oui. C'est le but de Kafka. | Non. Pas le but de layline.io, mais fonctionne bien avec les couches de persistance, telles que Kafka. |
| Configuration pilotée par l'interface utilisateur | Non | Oui |
| Intensité de la mémoire | Élevée | Faible |
| Empreinte matérielle | Élevée | Faible |
| Open Source | Oui, pour l'édition communautaire. Non pour la solution Confluent (par exemple ksql) | Pas encore. |
| Offre cloud prête | Oui, pour Confluent | Pas encore. |
- En savoir plus sur layline.io ici.
- Contactez-nous à hello@layline.io.


