Cosa stiamo dimostrando
Stiamo presentando un semplice progetto di layline.io che legge i dati da un file e ne esporta il contenuto in un topic Kafka.
Per seguire la dimostrazione in un ambiente reale, puoi scaricare le risorse di questo progetto dalla sezione Risorse in fondo. Leggi questo per imparare come importare il progetto nel tuo ambiente.
Configurazione
Il Workflow
Panoramica
La configurazione del workflow di questa dimostrazione è stata realizzata utilizzando il Workflow Editor di layline.io e appare così:
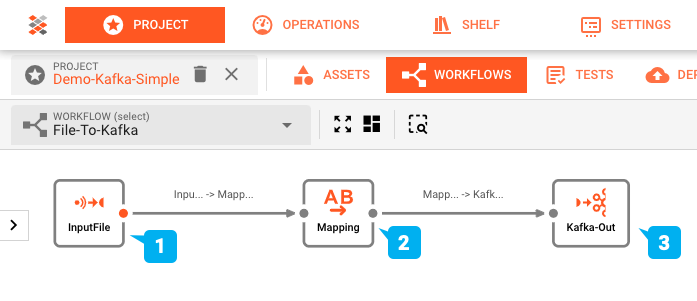
- (1) Input Processor: legge un file di input con una struttura header/dettaglio/trailer, poi
- (2) Flow Processor: mappa questi dati in un formato di output, che viene successivamente
- (3) Output Processor: scritto in un topic Kafka.
Per questa dimostrazione utilizziamo un topic Kafka ospitato da Cloud Karafka. Quindi, se esegui la dimostrazione da solo, non è necessaria una tua installazione di Kafka.
Configurazione degli Assets sottostanti
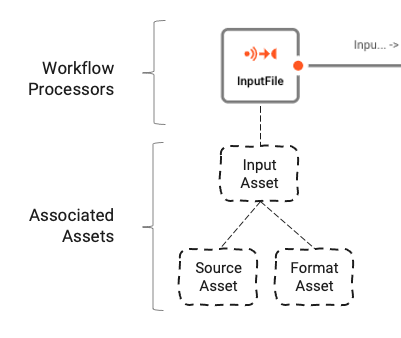
Il Workflow si basa su un numero di Assets sottostanti configurati utilizzando l'Asset Editor. L'associazione logica tra Workflow e Assets può essere compresa così:
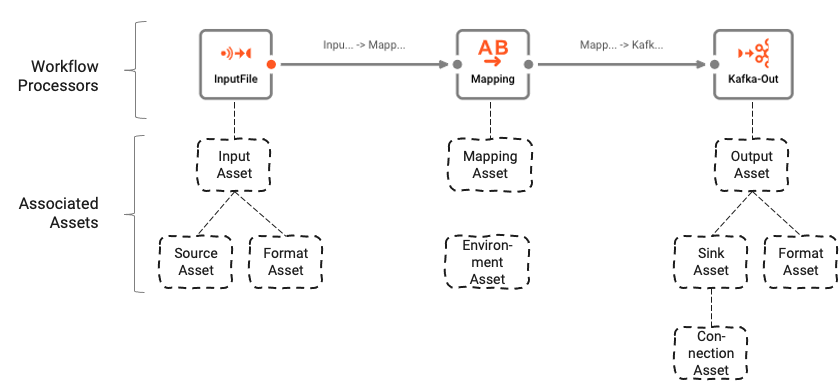
I Workflows sono composti da un numero di Processors collegati da Links.
I Processors si basano su Assets. Gli Assets sono entità di configurazione appartenenti a una specifica classe e tipo. Nell'immagine sopra possiamo vedere un Processor chiamato "InputFile", che appartiene alla classe Input Processor e al tipo Stream Input Processor. A sua volta si basa su altri due Assets "Source Asset" e "Format Asset" che appartengono rispettivamente al tipo File System Source e Generic Format.
In breve:
- Un Workflow è composto da Processors interconnessi
- I Processors si basano su Assets che li definiscono
- Gli Assets possono dipendere da altri Assets
Environment Asset: "My-Environment"
Per prima cosa: layline.io può aiutare a gestire diversi ambienti utilizzando le Environment Assets. Questo è di grande aiuto quando si utilizza lo stesso progetto in ambienti di test, staging e produzione che possono richiedere directory, connessioni, password, ecc. diverse. In questo progetto stiamo utilizzando una Environment Asset (2).
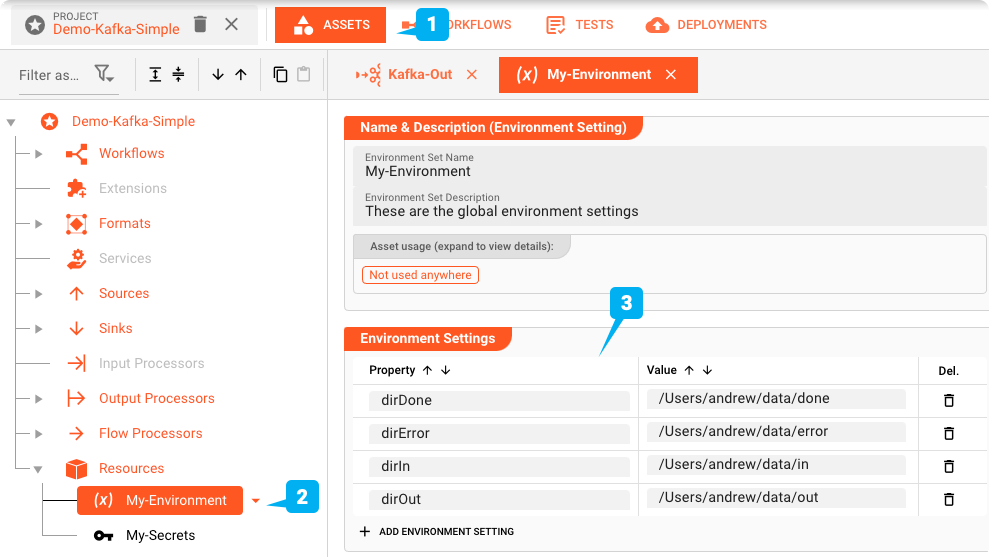
Variabili come queste possono essere utilizzate in tutto il progetto utilizzando una macro come ${lay:dirIn}. Le variabili di ambiente del sistema operativo o di sistema Java sono precedute rispettivamente da env: o sys: invece di lay:.
Stream Input Processor: "InputFile"
L'Input Processor (nome: InputFile / tipo: Stream Input Processor) si occupa di leggere i file di input e inoltrare i dati a valle all'interno del Workflow.
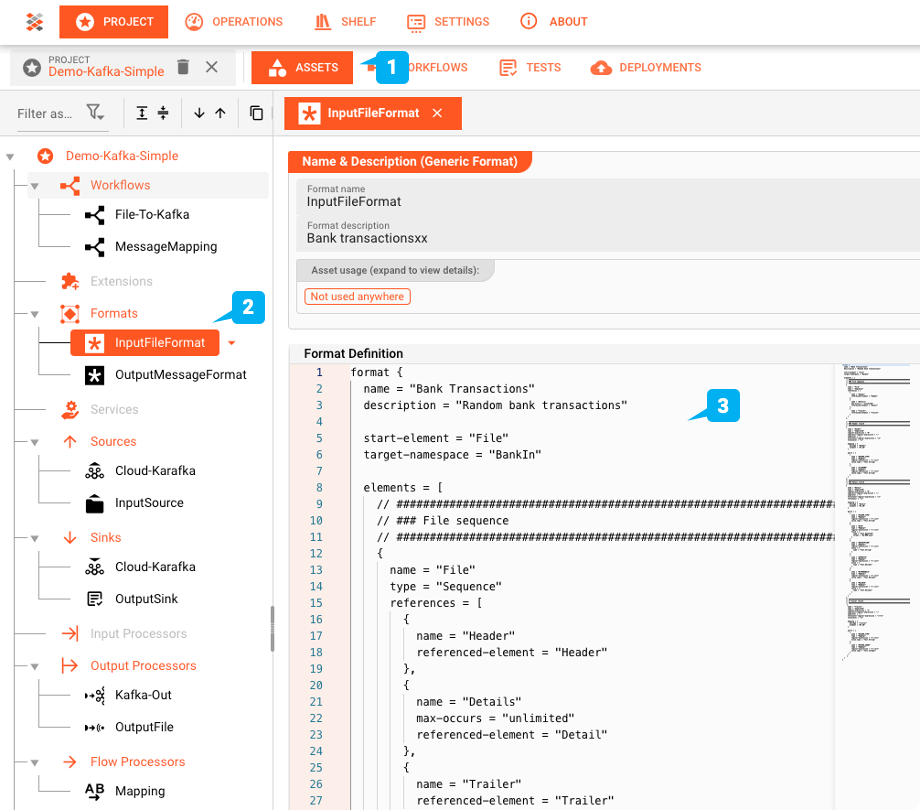
Generic Format Asset: "InputFileFormat"
layline.io fornisce gli strumenti per definire strutture dati complesse con il proprio linguaggio di grammatica. Il file nel nostro esempio è un campione di transazioni bancarie. Contiene un record di intestazione con due campi, un numero di record di dettaglio che contengono i dettagli delle transazioni e, infine, un record di chiusura.
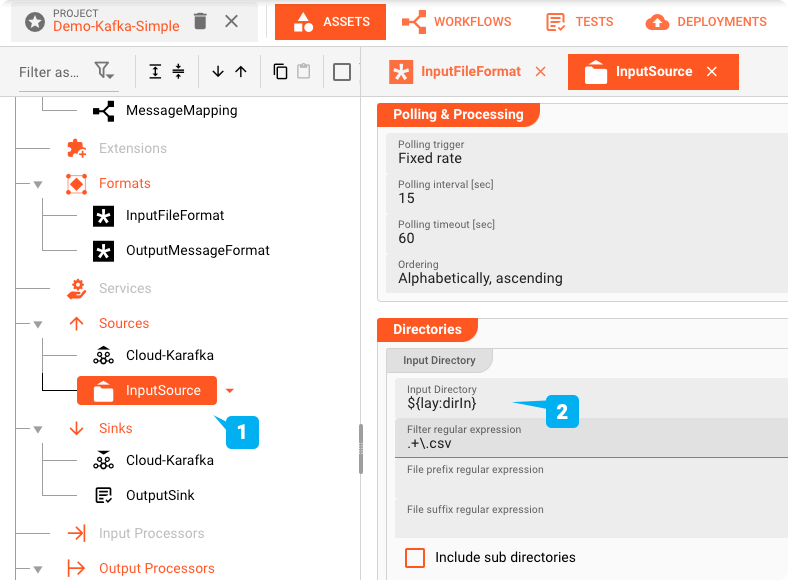
File-System-Source Asset: "InputSource"
L'"InputSource" è un Asset di tipo File System Source utilizzato per definire da dove viene letto il file.
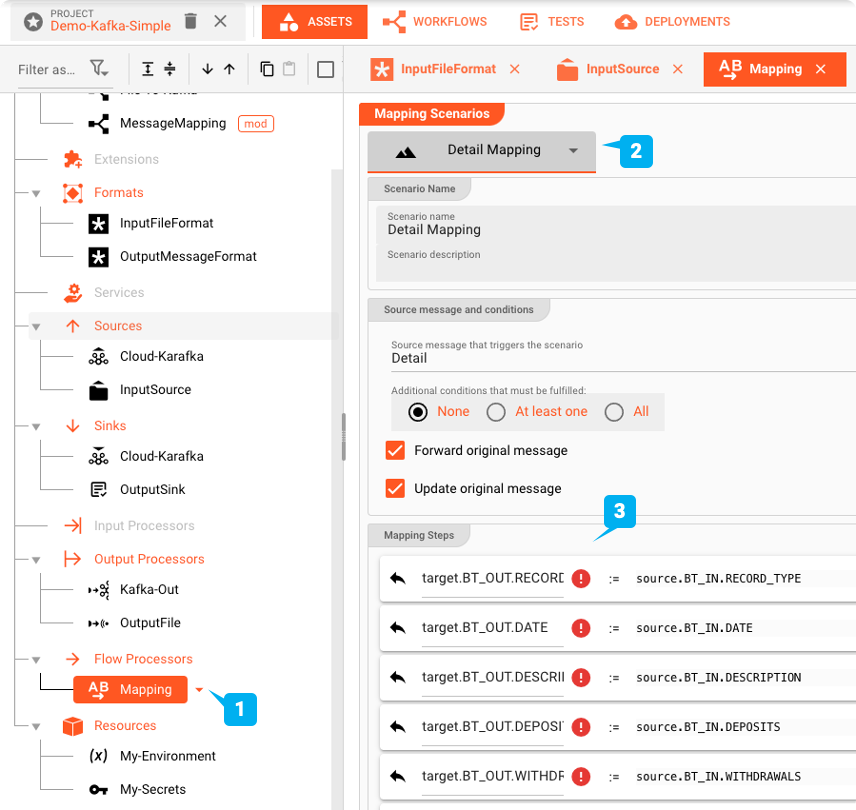
Flow Processor: Map
La Mapping Asset consente di mappare i valori dal formato di input al formato di output.
Stream Output Processor: Kafka
L'ultimo Processor nel Workflow è l'Output Processor "Kafka-Out".
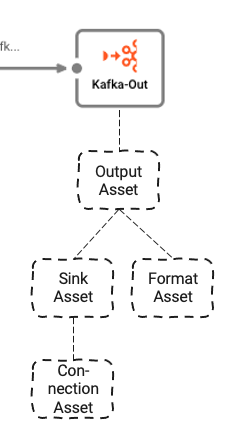
Dipende da tre Assets sottostanti:
- Output Asset: Definisce i topic Kafka e le partizioni a cui scriviamo
- Kafka Sink Asset: Il Sink che l'Output Asset può utilizzare per inviare dati
- Generic Format Asset: Definisce in quale formato scrivere i dati su Kafka
- Kafka Connection Asset: Definisce i parametri fisici di connessione a Kafka
Kafka Connection Asset: "Cloud-Karafka-Connection"
Per esportare su Kafka dobbiamo prima definire una Kafka Connection Asset.
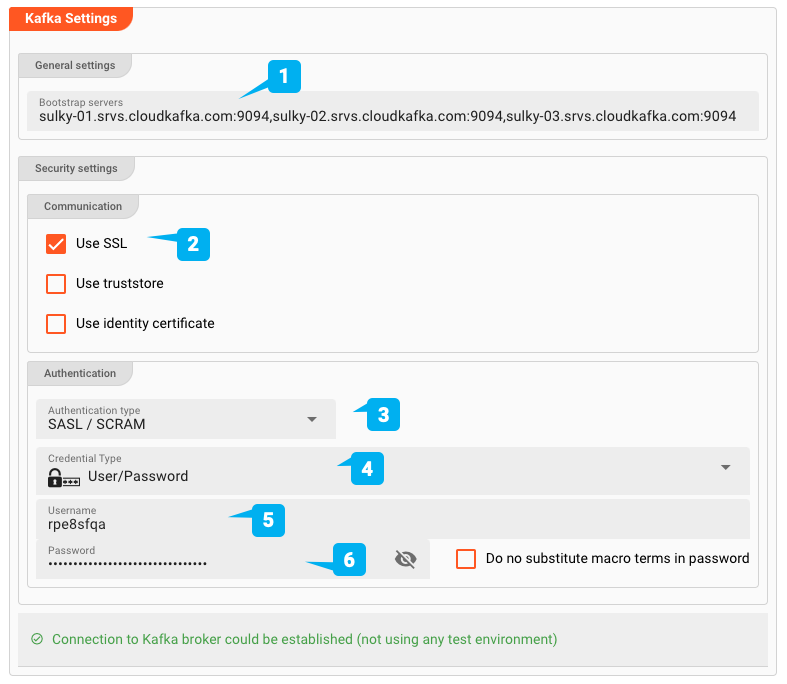
- (1) Bootstrap servers: Gli indirizzi di uno o più Bootstrap server
- (2) Use SSL: Definisce se si tratta di una connessione SSL
- (3) Authentication type: SASL / Plaintext, o SASL / SCRAM
- (4/5/6) Credentials: Nome utente/Password
Distribuzione ed esecuzione
Trasferimento della distribuzione
Per distribuire passiamo alla scheda DEPLOYMENT del progetto:
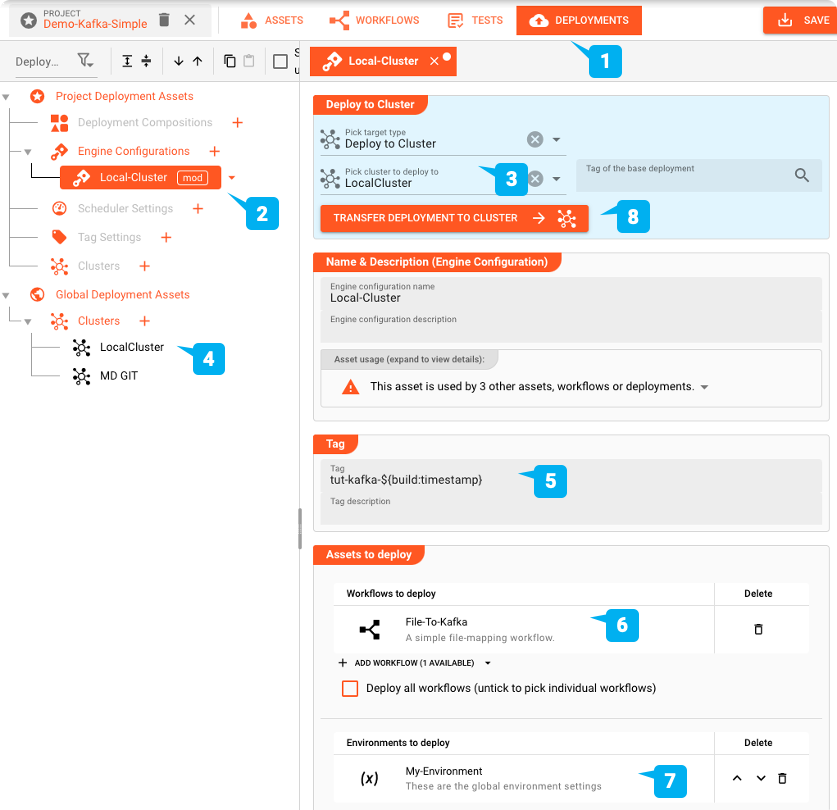
Creiamo una Engine Configuration per distribuire il progetto. Questo definisce le parti del progetto che desideriamo distribuire.
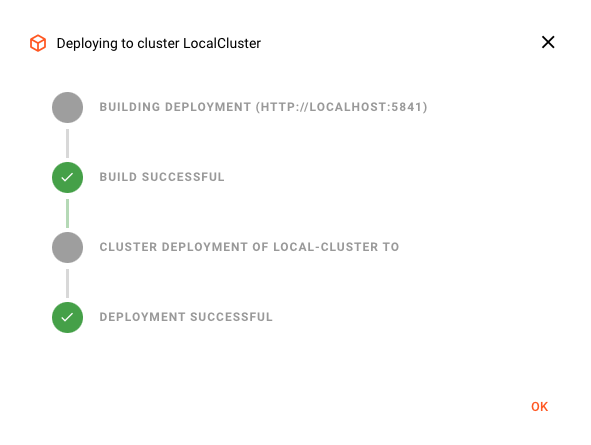
Attivazione della distribuzione
Passiamo alla scheda "CLUSTER":
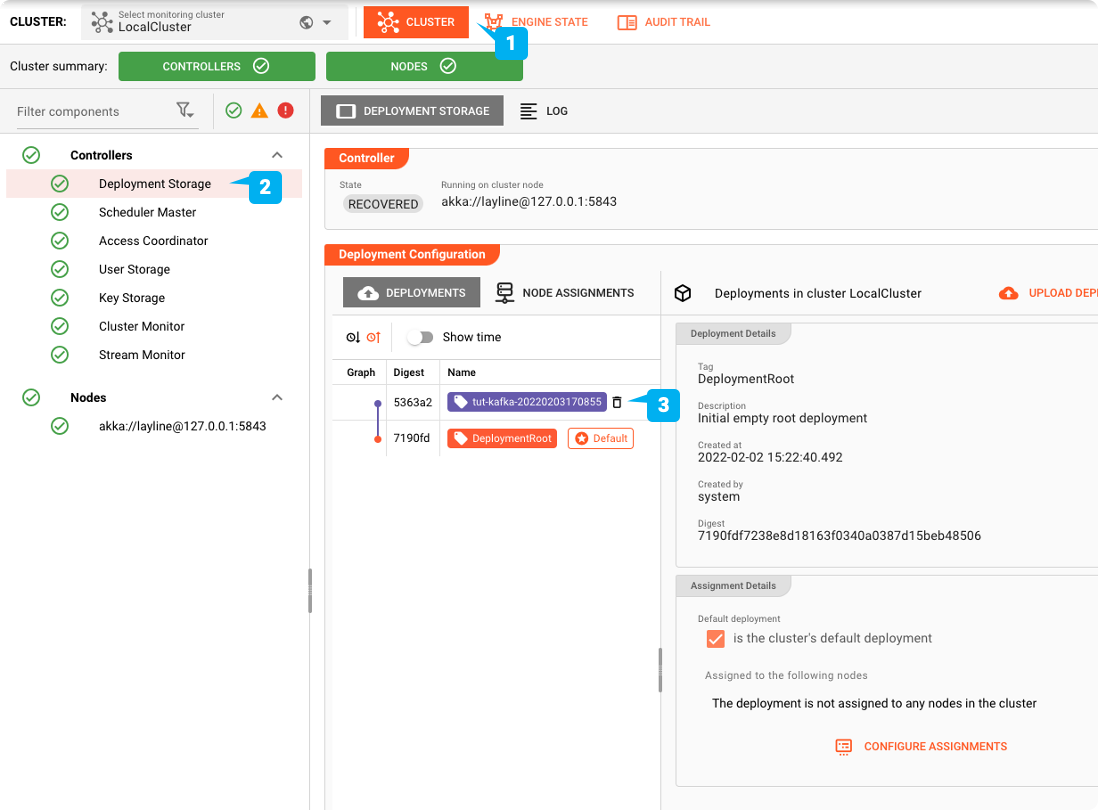
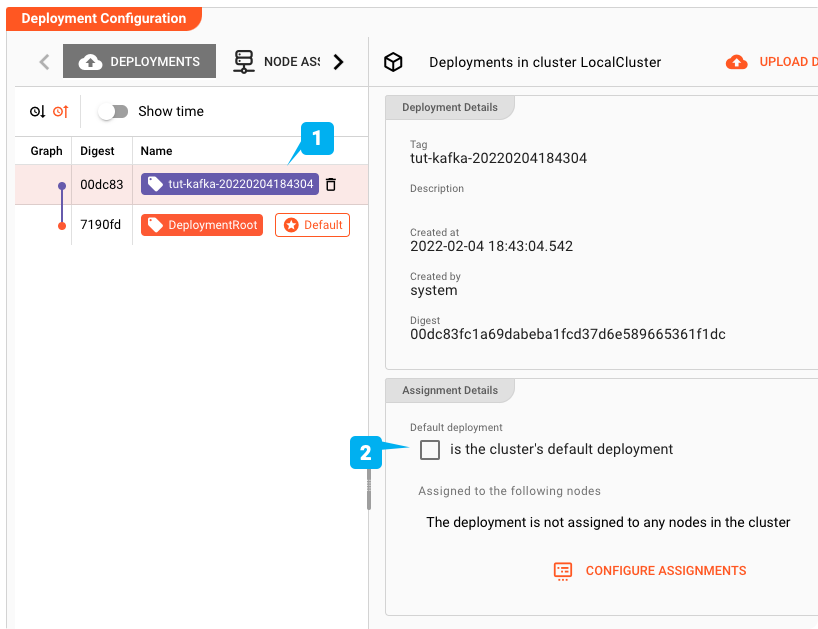
Impostarlo come distribuzione predefinita
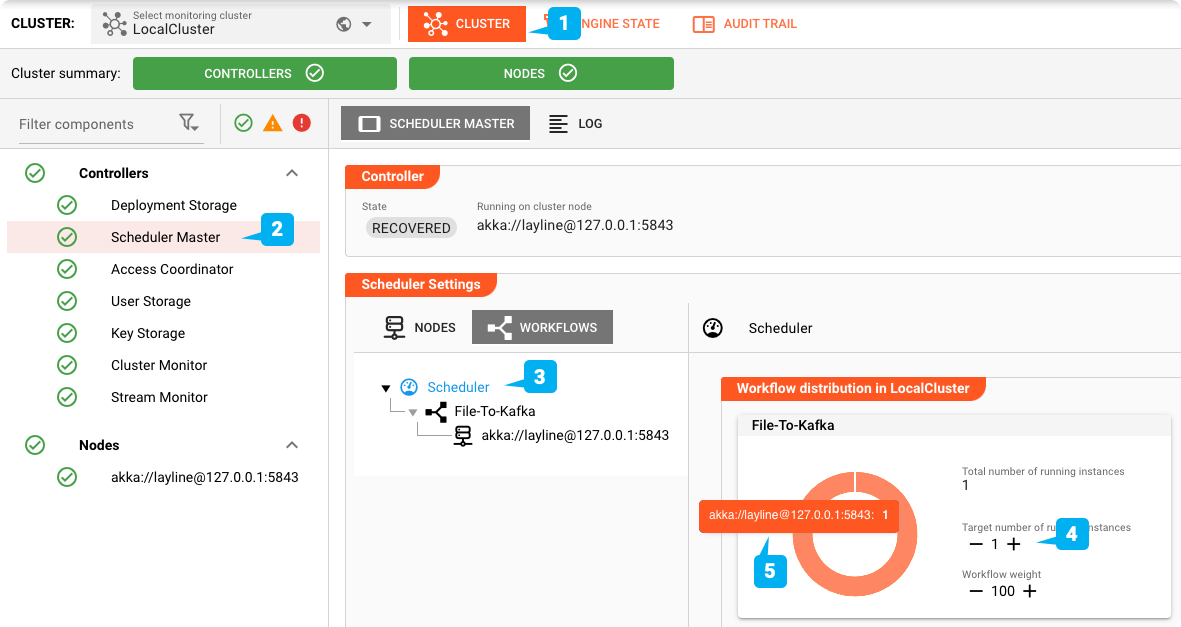
Pianificazione
Stato del motore
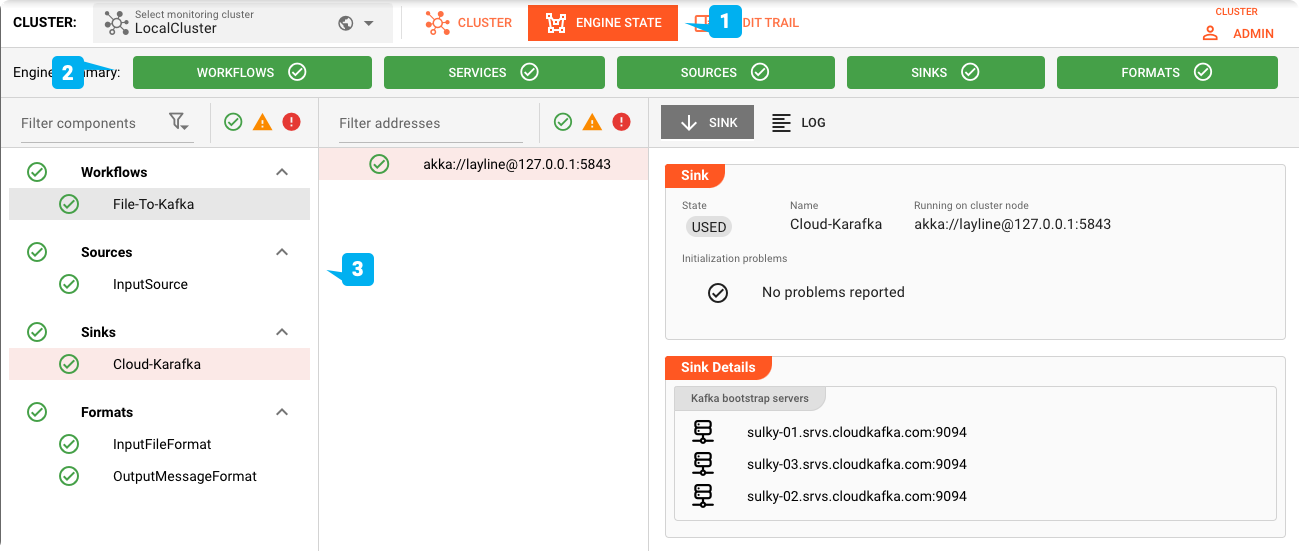
Alimentazione del file di test
Per testare, alimentiamo il nostro file di test nella directory di input che abbiamo configurato.
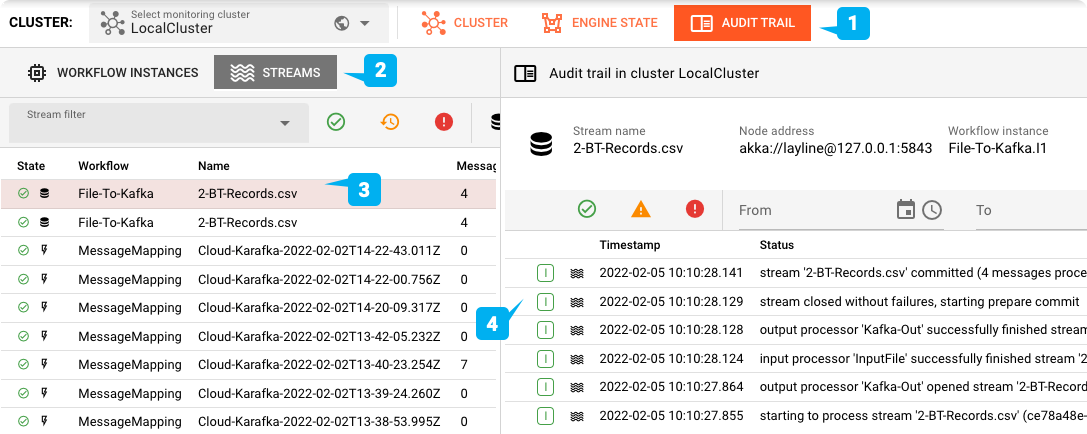
Puoi controllare il topic Cloud Karafka utilizzando uno strumento a tua scelta:

Riepilogo
Questa dimostrazione evidenzia come puoi creare un Workflow File-to-Kafka al volo senza difficoltà. E ottieni molto di più già pronto:
- Reactive — Abbraccia il paradigma di elaborazione reattiva
- Alta scalabilità — Si scala all'interno di un'istanza del motore e oltre
- Resilienza — Sicuro contro i guasti in ambienti distribuiti
- Distribuzione automatica — Distribuisci configurazioni modificate con un clic
- Real-time e batch — Esegui entrambi utilizzando la stessa piattaforma
- Metriche — Generazione automatica di metriche per il monitoraggio (es. Prometheus)
Risorse
| # | Descrizione |
|---|---|
| 1 | Github: Simple Kafka Project |
| 2 | file di test di input nella directory _test_files del progetto |
| 3 | credenziali Cloud Karafka trovate nel file cloud-karafka-credentials.txt |
| # | Documentazione |
|---|---|
| 1 | Getting Started |
| 2 | Importing a Project |
| 3 | What are Assets, etc? |
- Leggi di più su layline.io qui.
- Contattaci a hello@layline.io.