Das traditionelle Microservices-Modell auf Kubernetes/Docker hat einige Nachteile, die zu einer übermäßig komplexen Verwaltung und einem hohen Ressourcenverbrauch führen. In diesem Artikel erklären wir, wie layline.io Container- und Container-Orchestrierungstechnologie nutzt und gleichzeitig die genannten Herausforderungen mit einem besseren Ansatz löst.
Kurz erklärt: Kubernetes (K8S) & Docker
Container
Programme, die auf Kubernetes laufen, werden in Containern verpackt. Der Vorteil besteht darin, dass Software und Abhängigkeiten zusammengepackt werden. Das bedeutet weniger Sorgen und garantiert die Unabhängigkeit des Containers. Es gibt eine Vielzahl vorgefertigter Container, die von Portalen wie DockerHub heruntergeladen werden können und die unterschiedlichste Software enthalten.
Theoretisch können Sie viele Programme in einen Container packen, aber die Empfehlung und der Industriestandard lautet: ein Container = ein Prozess. Dies macht alles granularer, und Sie können einzelne Container (und damit Prozesse) leichter ersetzen.
Pods
Container laufen nicht eigenständig, sondern werden in einem weiteren „Container“ verpackt. Dieses Mal heißen sie Pods. Pods verwalten unter anderem virtuelle Ressourcen wie Netzwerk, Speicher, CPU usw. für die darin laufenden Container.
Es ist wichtig zu verstehen, dass Sie keine CPU-Leistung einem Container zuweisen, sondern einem Pod. Wenn Sie also mehr als einen Container in demselben Pod ausführen, müssen sich alle Container die dem Pod zur Verfügung stehenden Ressourcen teilen. Aus den gleichen Gründen, aus denen Sie nicht mehr als ein Programm in einen Container packen sollten, sollten Sie nicht mehr als einen Container in einen Pod packen, es sei denn, mehrere Container sind erforderlich, um den Zweck des Microservices zu erfüllen.
Ressourcenprobleme beim Skalieren in Kubernetes
In Kubernetes ist die Währung der Skalierbarkeit die Pods. Um mehr Rechenleistung zu erhalten, starten Sie mehr Pods, auch bekannt als Replikation.
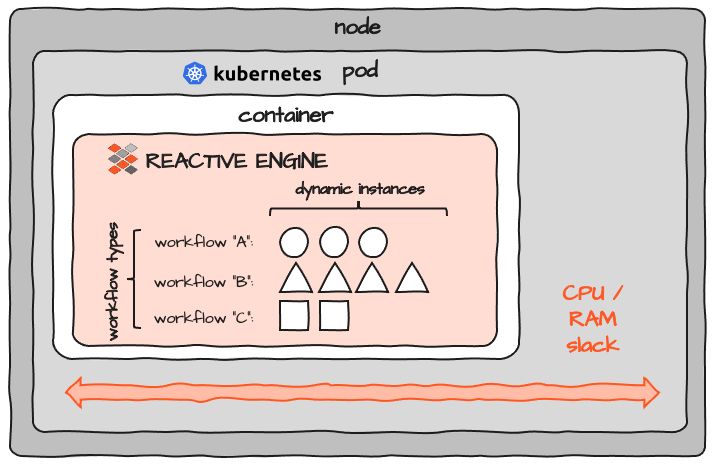
Wenn Sie sich dieses Design ansehen, ist ein Pod an sich ziemlich statisch. Wenn Sie die größtmögliche Flexibilität einhalten und in der Lage sein möchten, ein Programm durch ein anderes zu ersetzen, enthält Ihr Pod einen Container, der wiederum ein Programm enthält, das als ein Prozess ausgeführt wird.
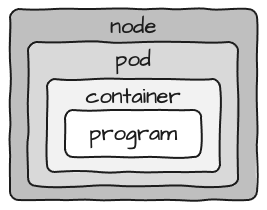
Wenn man bedenkt, dass die tatsächlich benötigten Ressourcen für den Container auf Pod-Ebene konfiguriert werden, sieht das Bild eher so aus:
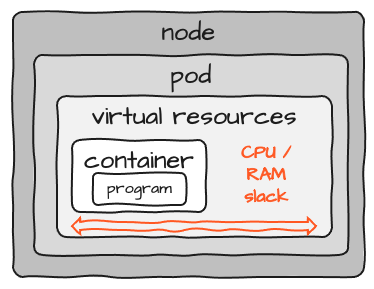
Beachten Sie den als „Slack“ markierten Bereich. Wenn Sie die Ressourcen für einen Container dimensionieren, müssen Sie eine gewisse Reserve an CPU und Speicher einplanen. Da es jedoch fast unmöglich ist, die notwendigen Ressourcen für ein Programm genau zu bestimmen, haben Sie in jedem Pod eine gewisse Reserve. Wenn Sie 100 davon betreiben, summiert sich der Slack 100-fach. Es gibt keine Ressourcenteilung zwischen Pods. Darüber hinaus gibt es für jeden Pod und jeden Node einen gewissen Overhead, der dem Cluster hinzugefügt wird. Während das Konzept von K8S insgesamt großartig ist, führt es auch zu einem erheblichen Ressourcen-Overhead.
Verteilung von Containern innerhalb eines Kubernetes-Clusters
Pods sind auch der kleinste Nenner, um Funktionalitäten innerhalb eines Kubernetes-Clusters zu verteilen. Angenommen, Sie haben die Microservices A, B und C und möchten sie ungleichmäßig innerhalb eines Clusters verteilen. Dann haben Sie entweder einzelne Pods, die jeweils A, B oder C enthalten, oder Sie benötigen eine Anzahl von Pods, um alle Permutationen von Pods zu erstellen, die die Container A, B und C enthalten (z. B. ein Pod mit A und B, ein Pod mit A und C usw.). Das sind viele Pods, die verwaltet werden müssen, und das kann schnell überwältigend und ineffizient werden.
Die Verteilung von Pods ist dann eine große Konfigurationsherausforderung innerhalb von Kubernetes und/oder Ihres bevorzugten CI/CD-Tools. Fügen Sie dazu die Verwaltung der automatisierten Skalierung und des Lastenausgleichs zwischen Nodes hinzu, und Sie haben eine große Herausforderung in Bezug auf Einrichtung und Überwachung.
Wie layline.io Skalierbarkeit, Ressourcen und Verteilung in einem Kubernetes-Cluster handhabt
Reactive Engine
layline.io führt die Reactive Engine ein. Die Engine dient als Ausführungskontext für Workflows, die so konfiguriert werden können, dass sie innerhalb einer Reactive Engine ausgeführt werden. Workflows sind mit Microservices vergleichbar, da sie spezifische Datenverarbeitungsaufgaben wie Datenaufnahme, Analyse und Anreicherung sowie das Beantworten von Abfrageanfragen usw. erfüllen. Workflows werden mit dem webbasierten Configuration Center konfiguriert:
Mehrere Reactive Engines bilden einen eigenen Reactive Cluster. Beim Einrichten von layline.io in einer Cluster-Umgebung wie Kubernetes richten Sie tatsächlich eine Anzahl von Nodes ein, die dann Reactive Engines enthalten, die in Containern gekapselt sind:
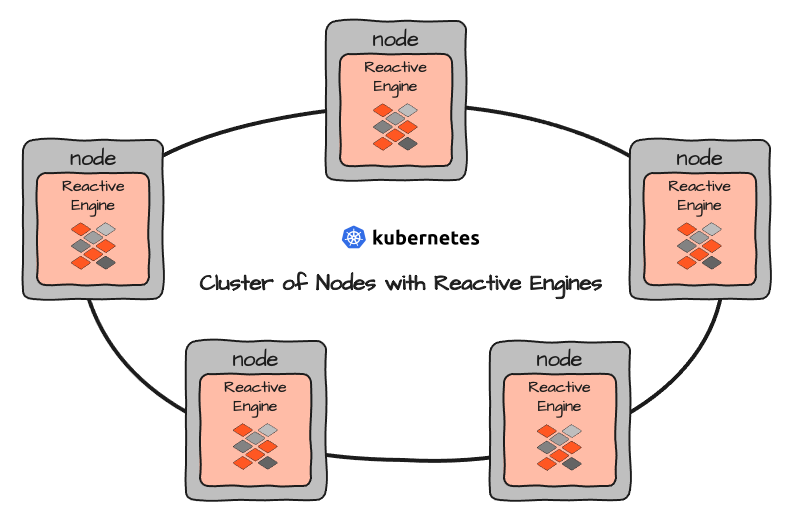
Alle Reactive Engines sind gleich. Sie dienen als Ausführungskontexte für Workflows. Vereinfacht gesagt können Sie Workflows als gleichwertig mit Microservices betrachten. Der Unterschied besteht darin, dass Workflows konfiguriert sind und daher eine Konfiguration und kein programmiertes Objektcode wie bei typischen Microservices darstellen.
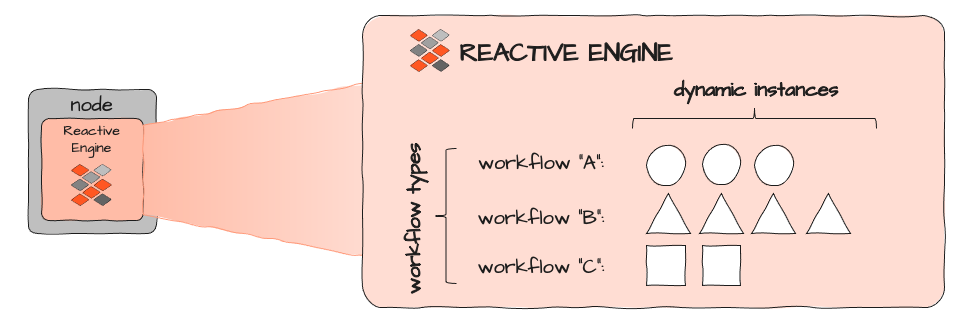
Jede Reactive Engine kann unterschiedliche Workflows (A, B und C oben) ausführen. Jeder Workflow kann dynamisch mehrfach instanziiert werden. Die Anzahl der Instanzen ist begrenzt durch die Ressourcen, die eine einzelne Workflow-Instanz verbraucht, und die verfügbaren und dem Ausführungskontext zugewiesenen Ressourcen, in dem die Reactive Engine selbst läuft. In einem Kubernetes-Cluster würde dies dem Bild eines entsprechenden Pods entsprechen:
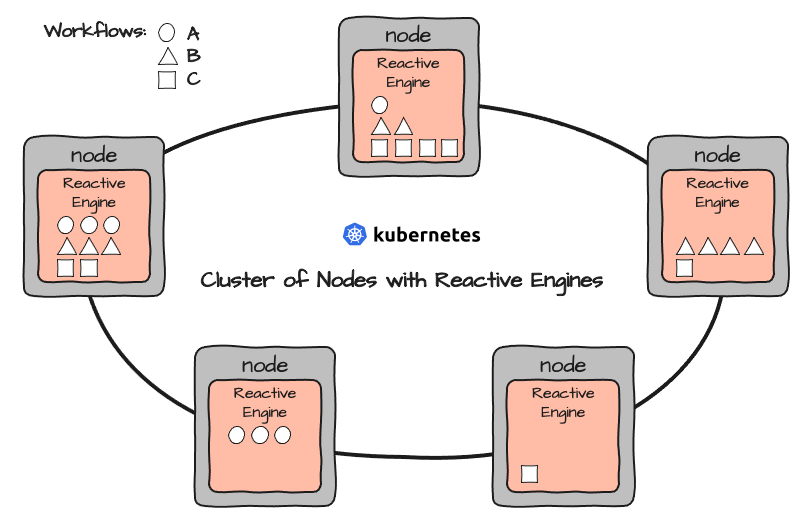
Jede Reactive Engine kann jeden Workflow ausführen. Workflows werden entweder direkt über das Configuration Center oder über Ihr bevorzugtes CI/CD-Tool (z. B. Bamboo usw.) bereitgestellt.
Dies könnte zu einer Einrichtung wie dieser führen:
Elastische Skalierung
Die Anzahl der Instanzen jedes Workflows kann dynamisch skaliert werden, entweder durch manuelle Eingriffe über das Config Center oder die Befehlszeile oder automatisch basierend auf dem Datenaufkommen.
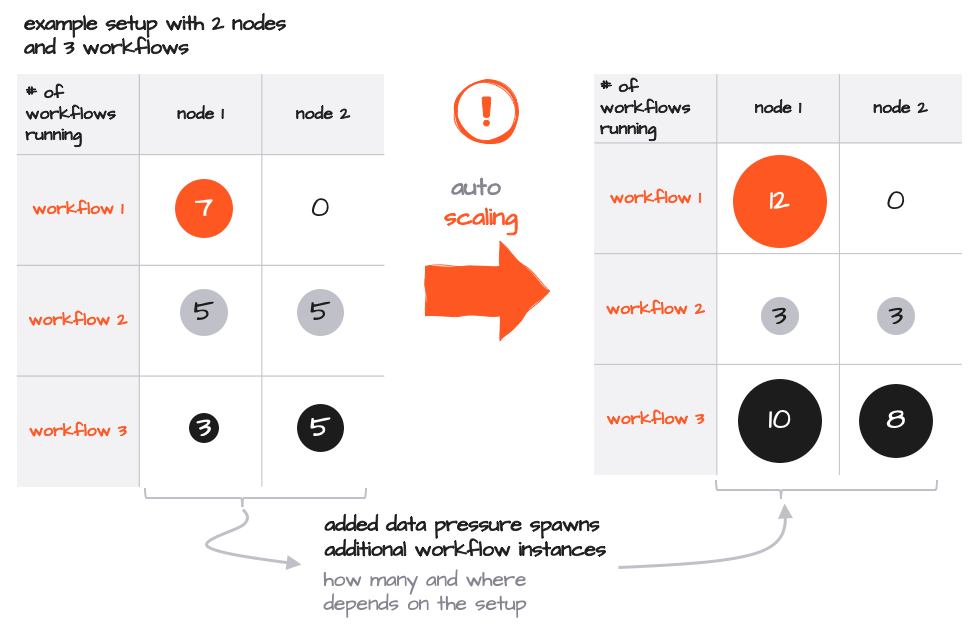
Während der Standard-Kubernetes-Weg, durch das Starten zusätzlicher Pods zu skalieren, weiterhin gültig bleibt, können Sie einfach zusätzliche Workflow-Instanzen innerhalb eines Pods starten. Beachten Sie, dass in diesem Beispiel keine zusätzlichen Pods aktiviert würden, da jeder Pod genügend Spielraum zum Skalieren enthält. Da alles innerhalb einer Reactive Engine skaliert wird, ist dieser Prozess extrem schnell und effizient, erfordert nur wenige zusätzliche Ressourcen pro Instanz und keine Eingriffe auf Kubernetes-Ebene.
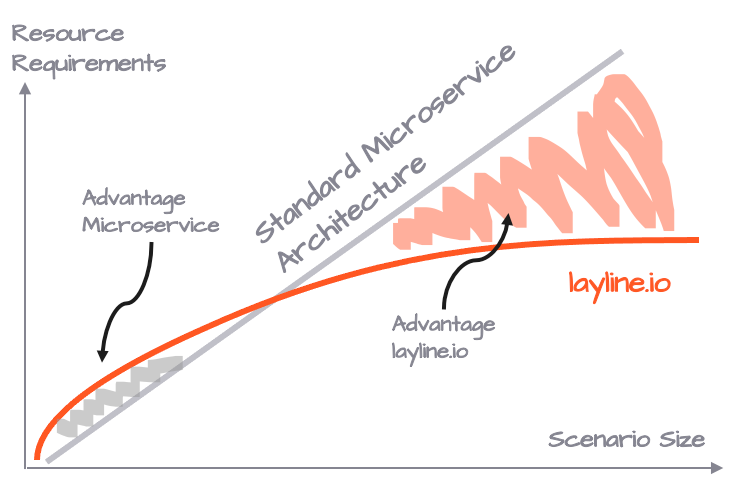
Vorteil Ressourcen
Es ist naheliegend zu denken, dass man die entsprechende CPU-Leistung und den RAM benötigt, unabhängig davon, ob man 30 Pods mit demselben Microservice auf drei Nodes verteilt oder drei Reactive Engines mit jeweils 10 Instanzen desselben Workflows auf drei Nodes. Aber das ist nicht der Fall.
Je nach Charakteristik des Microservices, der durch einen Workflow ersetzt wird, sparen Sie typischerweise zwischen 25-50 % der Ressourcen im Vergleich zur traditionellen Bereitstellung von Microservices. Es stimmt jedoch auch, dass eine Reactive Engine, die nur eine Workflow-Instanz ausführt, mehr Ressourcen benötigt als ein benutzerdefinierter Microservice, der nur einmal ausgeführt wird.
Es ist ein Kompromiss zwischen Flexibilität und Ressourcenanforderungen, der sich mit der Größe Ihres Verarbeitungsszenarios schnell zugunsten des layline.io-Modells wendet.
Vorteil Einrichtung
Die Einrichtung von layline.io in einem Kubernetes/Docker-Cluster bedeutet, dass derselbe Container auf jedem Node bereitgestellt wird. Jeder Container führt eine Reactive Engine aus, und es gibt keine anderen Containertypen mit unterschiedlichem Inhalt. Nur einen.
Damit eine Reactive Engine weiß, welche Workflows ausgeführt werden sollen, wird zur Laufzeit eine Konfiguration eingespeist. Da alle Reactive Engines einen eigenen Reactive Cluster bilden, reicht es aus, die Konfiguration in eine Reactive Engine einzuspeisen. Sie wird dann automatisch an alle anderen Engines im Cluster verteilt. Auch dies kann manuell oder automatisch über CI/CD-Tools ausgelöst werden.
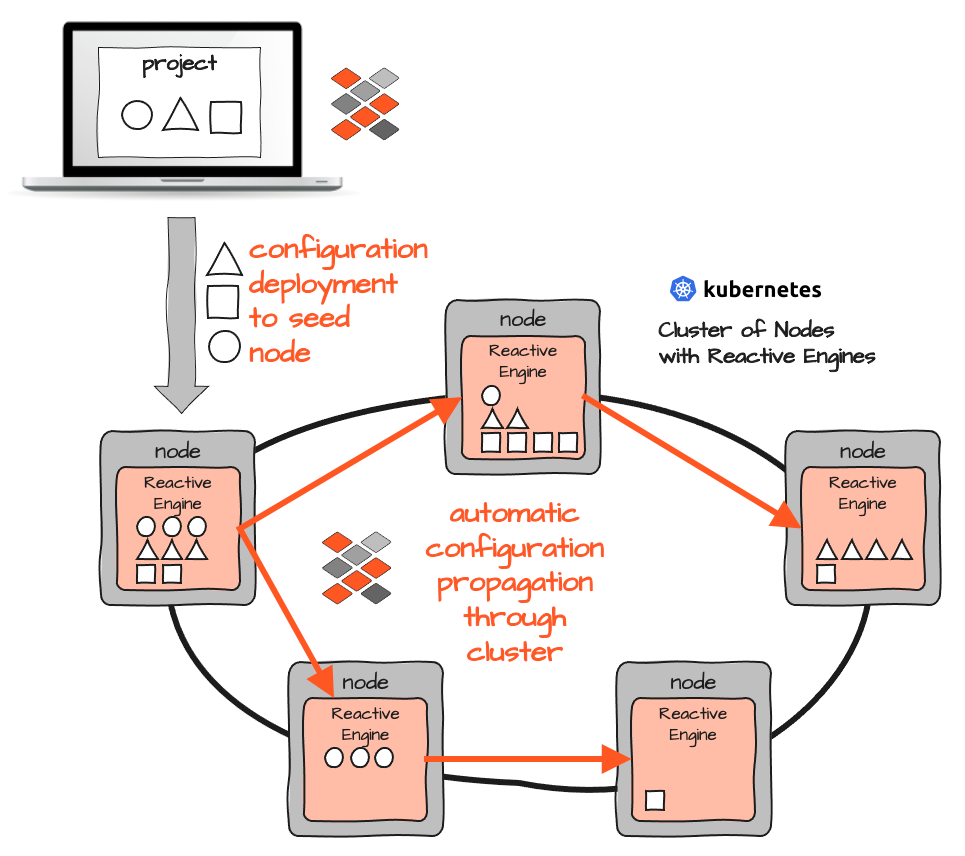
Im Gegensatz zum reinen Kubernetes/Docker-Konzept gibt es also keine Probleme mit verschiedenen Pods, die unterschiedliche Container enthalten, die bei jeder Änderung neu erstellt und dann aus Deployment-Sicht verwaltet werden müssen. Im Gegensatz zu Kubernetes müssen Sie sich nicht im Voraus Gedanken darüber machen, wo welcher Pod/Container ausgeführt werden soll, oder wie Sie Pods verschieben, falls Sie sie neu anordnen möchten. In layline.io können Sie einfach einen vorab geladenen Workflow in einer oder mehreren Reactive Engines aktivieren oder eine neue Workflow-Konfiguration in den Cluster bereitstellen, um diesen Workflow online zu bringen.
Zusammenfassung
| Aspekt | Kubernetes/Docker | layline.io |
|---|---|---|
| Skalierung | Skalierung über Pods | Skalierung innerhalb eines Pods über Workflow-Instanzen |
| Reaktionszeit der Skalierung | mittel | schnell |
| Ressourcenverbrauch | Besser bei kleinen Szenarien | Besser bei mittleren bis großen Szenarien |
| Einrichtung | Viele verschiedene Pods und Container | Konfigurationen, die in die Reactive Engine eingespeist werden |
Kubernetes ist großartig. Punkt. Aber es gibt Nachteile in Bezug auf Komplexität und Betrieb.
layline.io bietet eine viel bessere und schlankere Möglichkeit, nicht nur Services zu erstellen und zu verwalten, sondern sie auch in einer Cluster-Umgebung zu verwalten und zu verteilen. Für mittlere bis große Szenarien gibt es auch erhebliche Vorteile in Bezug auf Ressourcenmanagement und -verbrauch.
Sie können layline.io kostenlos hier herunterladen. Wenn Sie Fragen zu layline.io haben, zögern Sie nicht, uns zu kontaktieren!
Ressourcen
- layline.io herunterladen
- Probleme mit Microservices lösen
- Lesen Sie mehr über layline.io hier.
- Kontaktieren Sie uns unter hello@layline.io.