El modelo tradicional de Microservicios en Kubernetes/Docker tiene algunas desventajas que resultan en una gestión excesivamente compleja y un consumo elevado de recursos. En este artículo explicamos cómo layline.io adopta la tecnología de contenedores y orquestación de contenedores, mientras ayuda a resolver los desafíos mencionados con un enfoque mejorado.
Explicación rápida: Kubernetes (K8S) y Docker
Contenedores
Los programas que se ejecutan en Kubernetes están empaquetados en Contenedores. La ventaja es que el software y las dependencias están empaquetados juntos. Una cosa menos de qué preocuparse, garantizando la independencia del Contenedor. Hay toneladas de Contenedores listos para descargar desde portales como DockerHub, que empaquetan todo tipo de software.
En teoría, puedes empaquetar muchos programas en un solo Contenedor, pero la recomendación y el estándar de la industria es un Contenedor = un Proceso. Esto hace que todo sea más granular y permite reemplazar contenedores individuales (y, por lo tanto, procesos) de manera más sencilla.
Pods
Los contenedores no se ejecutan por sí solos, sino que están empaquetados en otro "contenedor". Esta vez se llaman Pods. Los Pods, entre otras cosas, gestionan recursos virtuales como red, memoria, CPU, etc., para los Contenedores que se ejecutan dentro de ellos.
Es importante entender que no asignas potencia de CPU a un Contenedor, sino a un Pod. Por lo tanto, si ejecutas más de un Contenedor en el mismo Pod, todos tienen que compartir los recursos disponibles para el Pod. Por las mismas razones por las que no deberías poner más de un programa en un Contenedor, no deberías poner más de un Contenedor en un Pod, a menos que varios Contenedores sean necesarios para cumplir con el propósito del Microservicio.
Problemas de recursos al escalar en Kubernetes
En Kubernetes, la unidad de escalabilidad son los Pods. Para tener más potencia de procesamiento, inicias más Pods, también conocido como replicación.
Si observas este diseño, un Pod en sí mismo es bastante estático. Si deseas adherirte a la máxima flexibilidad y poder reemplazar un programa con otro, entonces tu Pod contiene un Contenedor, que a su vez contiene un programa que se ejecutará como un proceso.
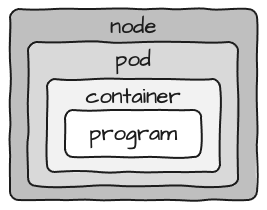
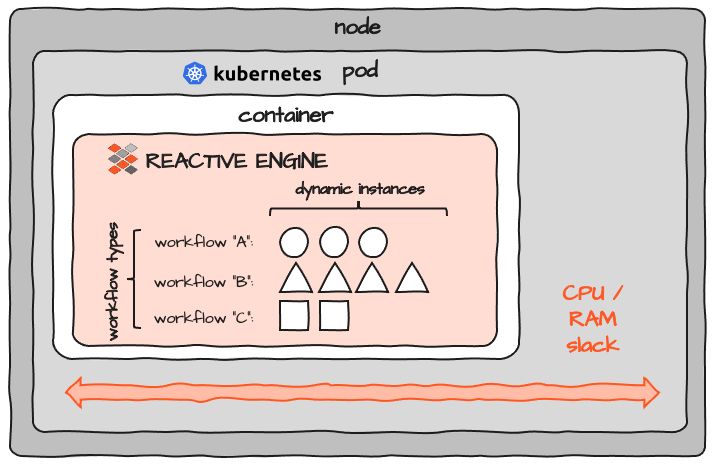
Considerando que los recursos reales requeridos para el contenedor se configuran a nivel de Pod, la imagen se ve más así:
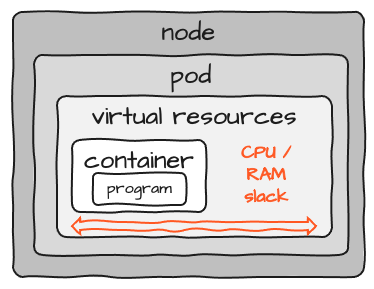
Observa el espacio marcado como "slack". Cuando dimensionas los recursos para un contenedor, debes considerar un margen en CPU y memoria. Pero debido a que es casi imposible determinar exactamente los recursos necesarios para un programa, terminas teniendo algo de reserva en cada pod. Si ejecutas 100 de estos, el margen se acumula 100 veces. No hay compartición de recursos entre Pods. Además, hay algo de sobrecarga para cada Pod y Nodo que se agrega al clúster. Por lo tanto, aunque el concepto general de K8S es excelente, también agrega una sobrecarga considerable de recursos en general.
Distribución de Contenedores dentro de un Clúster de Kubernetes
Los Pods también son el denominador más pequeño para distribuir funcionalidad dentro de un Clúster de Kubernetes. Supongamos que tienes Microservicios A, B y C y deseas distribuirlos de manera desigual dentro de un Clúster, ya sea que tengas Pods individuales que contengan A, B o C, o que tengas un número de Pods para formar todas las permutaciones de Pods que contengan los contenedores A, B y C (por ejemplo, un Pod con A y B, un Pod con A y C, etc.). Eso es un montón de Pods para gestionar y puede volverse rápidamente abrumador e ineficiente.
La distribución de Pods es entonces un gran desafío de configuración dentro de Kubernetes y/o tu herramienta de CI/CD preferida. Añade a esto la gestión del escalado automático y el balanceo de carga entre Nodos y terminas teniendo un gran dolor de cabeza de configuración y monitoreo.
Cómo layline.io aborda la escalabilidad, los recursos y la distribución en un Clúster de Kubernetes
Reactive Engine
layline.io introduce el Reactive Engine. El motor sirve como un contexto de ejecución para Workflows que pueden configurarse para ejecutarse dentro de un Reactive Engine. Los Workflows son comparables a los Microservicios en el sentido de que cumplen tareas específicas de procesamiento de datos, que van desde la ingestión, análisis y enriquecimiento, hasta responder a solicitudes de consulta, etc. Los Workflows se configuran utilizando el Configuration Center basado en la web:
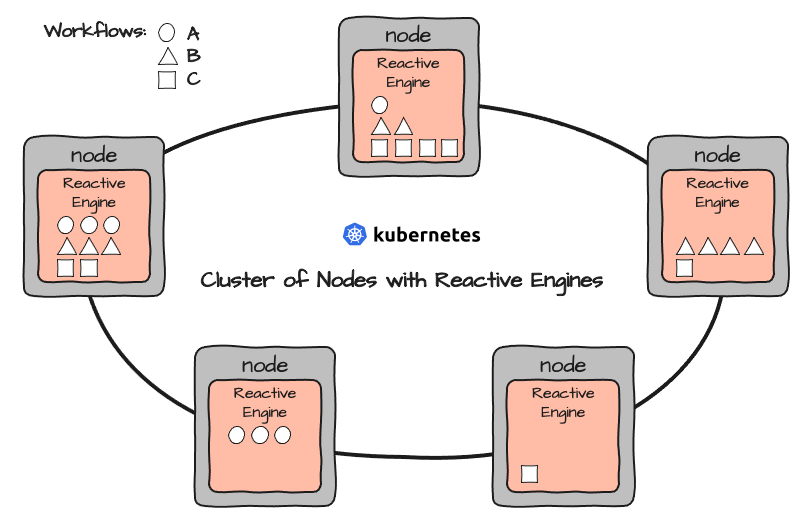
Múltiples Reactive Engines forman un Reactive Cluster propio. Al configurar layline.io en un entorno de Clúster como Kubernetes, en realidad configuras un número de Nodos que luego ejecutan Reactive Engines encapsulados en contenedores:
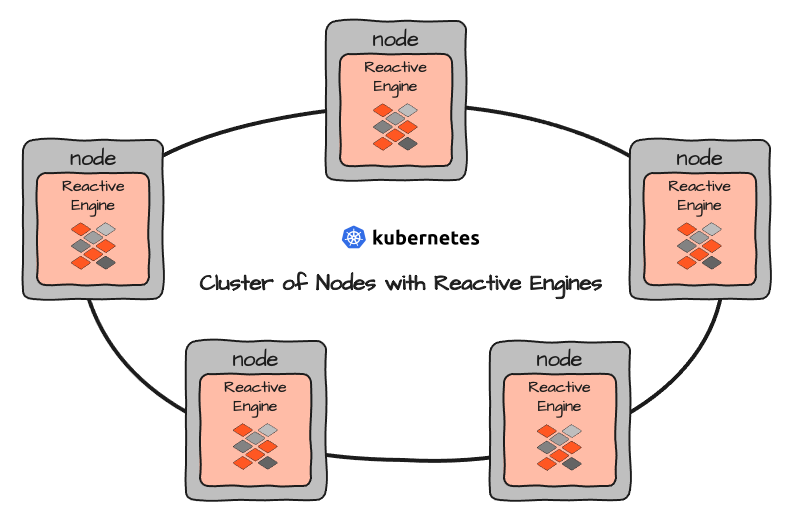
Todos los Reactive Engines son iguales. Sirven como contextos de ejecución para Workflows. Simplificando, puedes ver los Workflows como equivalentes a los Microservicios. La diferencia es que los Workflows son configurados y, por lo tanto, una Configuración, y no un código objeto programado como en los Microservicios típicos.
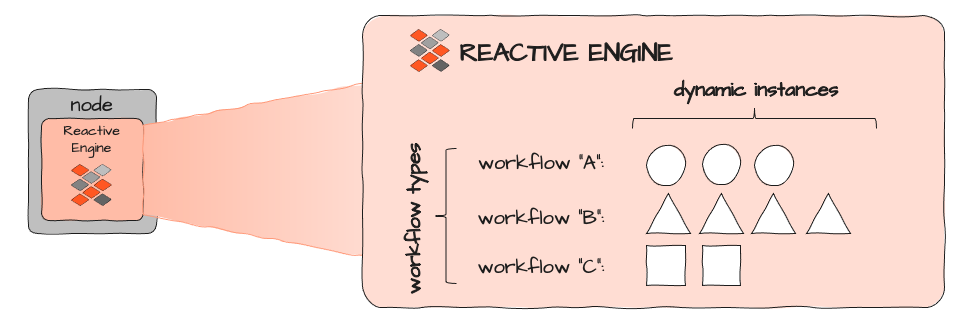
Cada Reactive Engine puede ejecutar diferentes Workflows (A, B y C arriba). Cada Workflow puede instanciarse dinámicamente varias veces. El número de instancias está limitado por cuántos recursos consume una sola instancia de Workflow y cuántos recursos están disponibles y asignados al contexto de ejecución en el que se ejecuta el Reactive Engine. En un Clúster de Kubernetes, esta sería la imagen de un Pod respectivo:
Cualquier Reactive Engine puede ejecutar cualquier Workflow. Los Workflows se implementan directamente a través del Configuration Center o mediante tu herramienta de CI/CD preferida (por ejemplo, Bamboo, etc.).
Esto podría resultar en una configuración como esta:
Escalado elástico
El número de instancias de cada Workflow puede escalarse hacia arriba y hacia abajo dinámicamente, ya sea mediante intervención manual desde el Config Center o la línea de comandos, o automáticamente en función de la presión de datos.
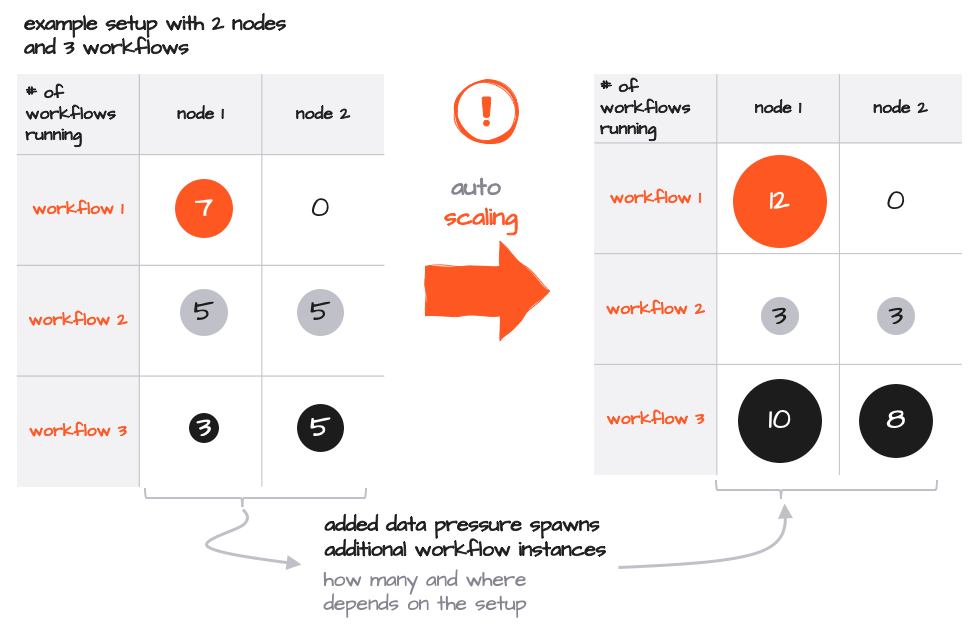
Aunque el método estándar de Kubernetes para escalar iniciando Pods adicionales sigue siendo válido, simplemente puedes iniciar instancias adicionales de Workflow dentro de un Pod. Ten en cuenta que no se activarían Pods adicionales en este ejemplo, dado que cada Pod contiene suficiente espacio para escalar. Debido a que todo se escala dentro de un Reactive Engine, este proceso es extremadamente rápido y eficiente, requiriendo solo unos pocos recursos adicionales por instancia y sin intervención a nivel de Kubernetes.
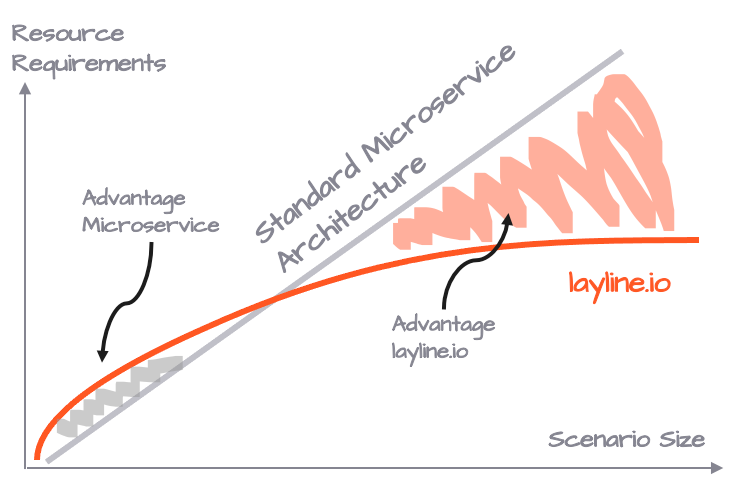
Ventaja en Recursos
Tiene sentido pensar que se requerirá la potencia de CPU y RAM respectiva independientemente de si distribuyes 30 Pods con el mismo Microservicio en tres Nodos, o tres Reactive Engines con 10 instancias del mismo Workflow cada uno en tres Nodos. Pero ese no es el caso.
Dependiendo de las características del Microservicio que es reemplazado por un Workflow, típicamente ahorras entre un 25-50% de recursos en comparación con la forma tradicional de implementar Microservicios. También es cierto, sin embargo, que un Reactive Engine ejecutando solo una instancia de Workflow requiere más recursos que un Microservicio personalizado que solo se ejecuta una vez.
Es un equilibrio entre flexibilidad y requisitos de recursos, que rápidamente se inclina a favor del modelo de layline.io con el tamaño de tu escenario de procesamiento.
Ventaja en Configuración
Configurar layline.io en un clúster de Kubernetes/Docker significa implementar el mismo contenedor en cada Nodo. Cada contenedor ejecuta un Reactive Engine y no hay otros tipos de contenedores con contenido diferente. Solo uno.
Para que un Reactive Engine sepa qué Workflows ejecutar, se inyecta una configuración en tiempo de ejecución. Debido a que todos los Reactive Engines forman un Reactive Cluster propio, es suficiente inyectar la Configuración en un solo Reactive Engine. Luego, se distribuye automáticamente a todos los demás Engines en el Clúster. Nuevamente, todo esto puede activarse manualmente o automáticamente a través de herramientas de CI/CD.
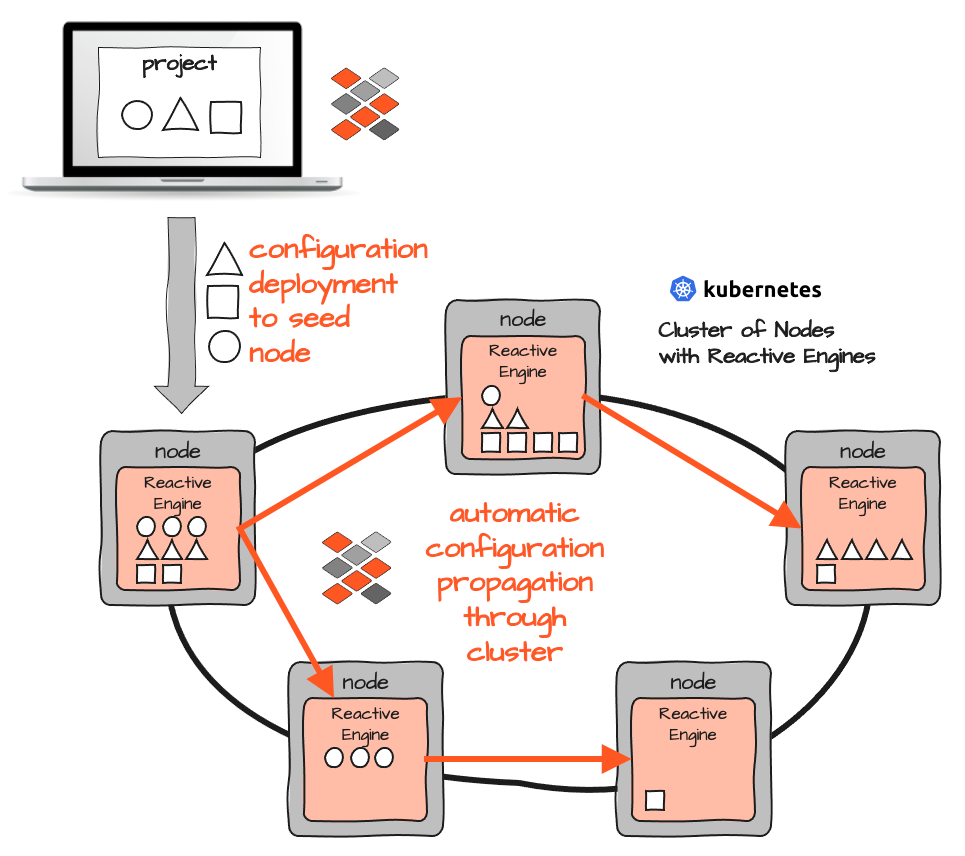
Así que, a diferencia del concepto puro de Kubernetes/Docker, no hay complicaciones con diferentes Pods que contienen diferentes contenedores que necesitan ser reconstruidos en cada cambio y luego gestionados desde un punto de vista de implementación. Contrario a Kubernetes, no tienes que pensar en dónde ejecutar cada Pod/Contenedor de antemano, o cómo reorganizar los Pods en caso de que quieras reubicarlos. En layline.io simplemente puedes activar un Workflow precargado en uno o más Reactive Engines, o implementar una nueva Configuración de Workflow en el Clúster para poner este Workflow en línea.
Resumen
| Aspecto | Kubernetes/Docker | layline.io |
|---|---|---|
| Escalado | Escalar mediante Pods | Escalar dentro del Pod mediante instancias de Workflow |
| Tiempo de reacción del escalado | medio | rápido |
| Consumo de recursos | Mejor en escenarios pequeños | Mejor en escenarios medianos a grandes |
| Configuración | Muchos Pods y Contenedores diferentes | Configuraciones inyectadas en el Reactive Engine |
Kubernetes es genial. Punto. Pero tiene desventajas en cuanto a complejidad y operación.
layline.io proporciona una forma mucho mejor y más eficiente no solo de crear y gestionar Servicios, sino también de gestionarlos y distribuirlos en un entorno de Clúster. Para escenarios medianos a grandes, también hay una ventaja significativa en cuanto a la gestión y el consumo de recursos.
Puedes descargar y usar layline.io de forma gratuita aquí. Si tienes alguna pregunta sobre layline.io, no dudes en contactarnos.
Recursos
- Descargar layline.io
- Solucionando lo que está mal con los Microservicios
- Lee más sobre layline.io aquí.
- Contáctanos en hello@layline.io.