Le modèle traditionnel des microservices sur Kubernetes/Docker présente certains inconvénients qui entraînent une gestion excessivement complexe et une consommation de ressources accrue. Dans cet article, nous expliquons comment layline.io adopte la technologie des conteneurs et de l'orchestration de conteneurs, tout en aidant à résoudre les défis susmentionnés grâce à une meilleure approche.
Explication rapide : Kubernetes (K8S) & Docker
Conteneurs
Les programmes exécutés sur Kubernetes sont empaquetés dans des conteneurs. L'avantage est que le logiciel et ses dépendances sont regroupés. Cela simplifie la gestion et garantit l'indépendance du conteneur. Il existe de nombreux conteneurs prêts à l'emploi téléchargeables sur des portails tels que DockerHub, contenant toutes sortes de logiciels.
En théorie, vous pouvez empaqueter plusieurs programmes dans un seul conteneur, mais la recommandation et la norme de l'industrie est un conteneur = un processus. Cela rend tout plus granulaire, et vous pouvez remplacer plus facilement les conteneurs individuels (et donc les processus) de cette manière.
Pods
Les conteneurs ne s'exécutent pas seuls, mais sont empaquetés dans un autre "conteneur". Cette fois, ils sont appelés Pods. Les Pods, entre autres, gèrent des ressources virtuelles telles que le réseau, la mémoire, le CPU, etc., pour les conteneurs qu'ils contiennent.
Il est important de comprendre que vous n'attribuez pas de puissance CPU à un conteneur, mais à un Pod. Par conséquent, si vous exécutez plusieurs conteneurs dans le même Pod, ils doivent tous partager les ressources disponibles pour le Pod. Pour les mêmes raisons que vous ne devriez pas mettre plus d'un programme dans un conteneur, vous ne devriez pas mettre plus d'un conteneur dans un Pod, sauf si plusieurs conteneurs sont nécessaires pour servir l'objectif du microservice.
Problèmes de ressources lors de la mise à l'échelle dans Kubernetes
Dans Kubernetes, la "monnaie" de l'évolutivité est le Pod. Pour avoir plus de puissance de traitement, vous lancez plus de Pods, également appelés répliques.
Si vous examinez cette conception, un Pod en soi est en réalité assez statique. Si vous voulez respecter une flexibilité maximale et être capable de remplacer un programme par un autre, alors votre Pod contient un conteneur, qui à son tour contient un programme qui s'exécutera comme un processus unique.
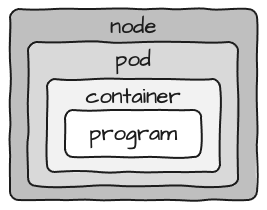
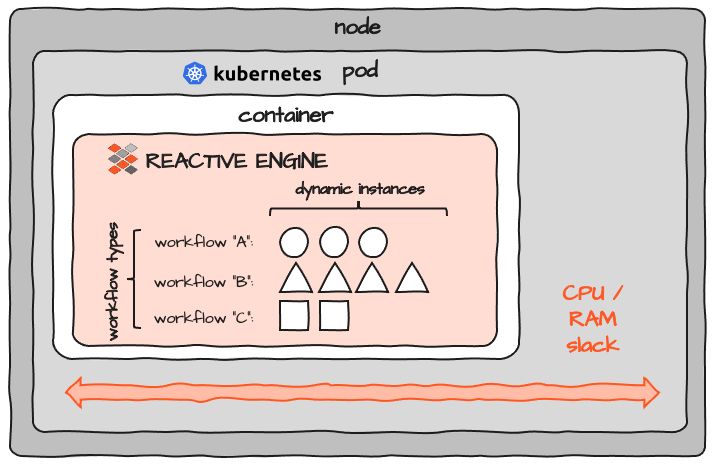
En considérant que les ressources réelles requises pour le conteneur sont configurées au niveau du Pod, l'image ressemble davantage à ceci :
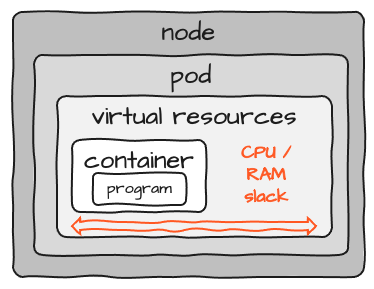
Regardez l'espace marqué comme "slack". Lorsque vous dimensionnez les ressources pour un conteneur, vous devez prévoir une certaine marge pour le CPU et la mémoire. Mais comme il est presque impossible de déterminer exactement les ressources nécessaires pour un programme, vous vous retrouvez avec une réserve dans chaque Pod. Si vous en exécutez 100, la marge s'additionne 100 fois. Il n'y a pas de partage de ressources entre les Pods. En plus de cela, il y a un certain surcoût pour chaque Pod et chaque Node qui s'ajoute au cluster. Ainsi, bien que le concept de K8S soit globalement excellent, il ajoute également un surcoût de ressources considérable.
Distribution des conteneurs au sein d'un cluster Kubernetes
Les Pods sont également le plus petit dénominateur pour distribuer des fonctionnalités au sein d'un cluster Kubernetes. Supposons que vous ayez les microservices A, B et C et que vous souhaitiez les distribuer de manière inégale dans un cluster, vous devez soit avoir des Pods individuels contenant chacun A, B ou C, soit avoir un certain nombre de Pods pour composer toutes les permutations de Pods contenant les conteneurs A, B et C (par exemple, un Pod avec A et B, un Pod avec A et C, etc.). Cela représente beaucoup de Pods à gérer et peut rapidement devenir accablant et inefficace.
La distribution des Pods devient alors un défi majeur de configuration dans Kubernetes et/ou votre outil CI/CD de choix. Ajoutez à cela la gestion de la mise à l'échelle automatique et de l'équilibrage de charge entre les Nodes, et vous vous retrouvez avec un casse-tête majeur en termes de configuration et de surveillance.
Comment layline.io gère l'évolutivité, les ressources et la distribution dans un cluster Kubernetes
Reactive Engine
layline.io introduit le Reactive Engine. Ce moteur sert de contexte d'exécution pour les Workflows qui peuvent être configurés pour s'exécuter dans un Reactive Engine. Les Workflows sont comparables aux microservices en ce qu'ils remplissent des tâches spécifiques de traitement des données allant de l'ingestion, l'analyse et l'enrichissement jusqu'à la réponse aux requêtes, etc. Les Workflows sont configurés à l'aide du Configuration Center basé sur le web :
Plusieurs Reactive Engines forment leur propre Reactive Cluster. Lors de la configuration de layline.io dans un environnement de cluster comme Kubernetes, vous configurez en réalité un certain nombre de Nodes qui exécutent ensuite des Reactive Engines encapsulés dans des conteneurs :
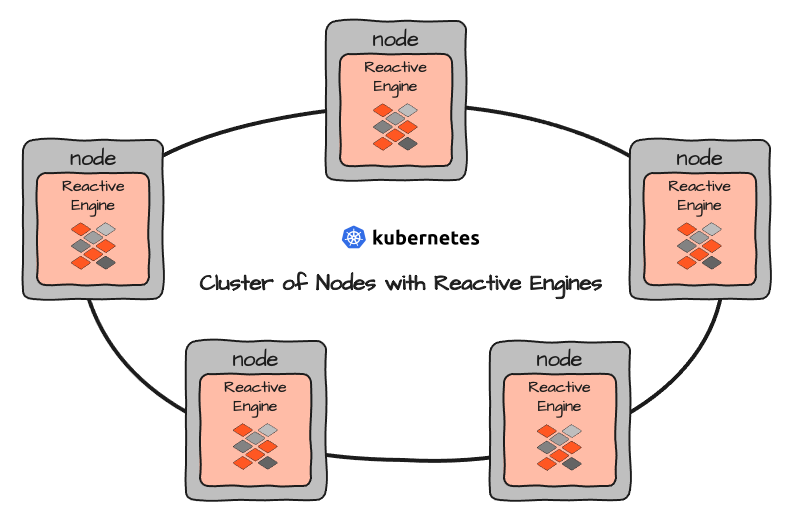
Tous les Reactive Engines sont créés égaux. Ils servent de contextes d'exécution pour les Workflows. En simplifiant, vous pouvez considérer les Workflows comme équivalents aux microservices. La différence réside dans le fait que les Workflows sont configurés et donc une configuration, et non un code objet programmé comme avec les microservices typiques.
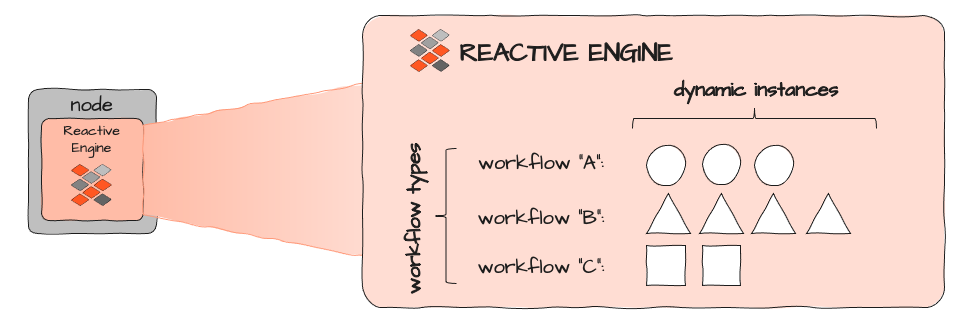
Chaque Reactive Engine peut exécuter différents Workflows (A, B et C ci-dessus). Chaque Workflow peut être instancié dynamiquement plusieurs fois. Le nombre d'instances est limité par la quantité de ressources qu'une seule instance de Workflow consomme et par la quantité de ressources disponibles et attribuées au contexte d'exécution dans lequel le Reactive Engine lui-même s'exécute. Dans un cluster Kubernetes, cela correspondrait à l'image d'un Pod respectif :
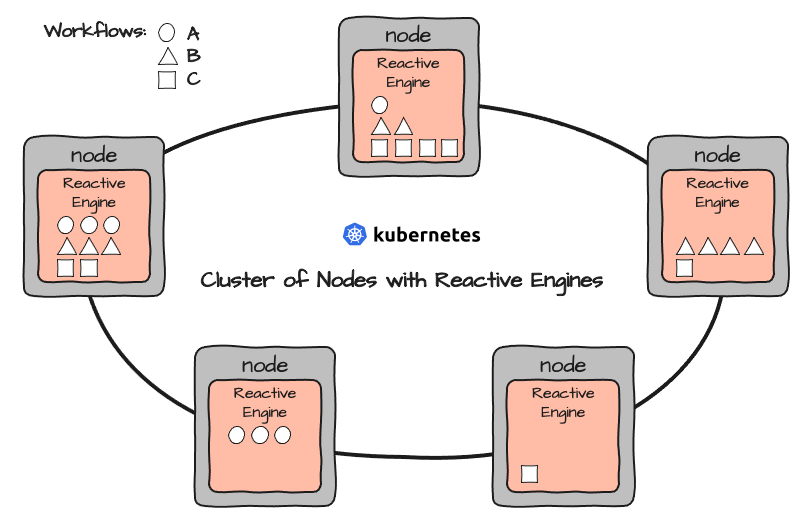
Tout Reactive Engine peut exécuter n'importe quel Workflow. Les Workflows sont déployés soit directement via le Configuration Center, soit via votre outil CI/CD préféré (par exemple Bamboo, etc.).
Cela pourrait aboutir à une configuration comme celle-ci :
Mise à l'échelle élastique
Le nombre d'instances de chaque Workflow peut être augmenté ou diminué dynamiquement, soit par intervention manuelle depuis le Config Center ou la ligne de commande, soit automatiquement en fonction de la pression des données.
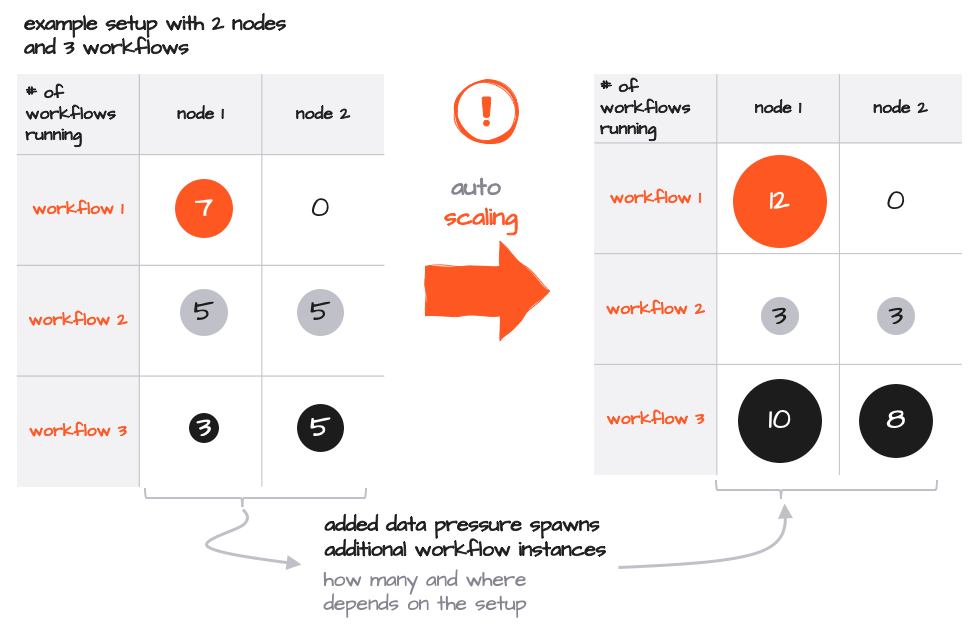
Bien que la méthode standard Kubernetes pour évoluer en lançant des Pods supplémentaires reste valide, vous pouvez simplement lancer des instances supplémentaires de Workflow au sein d'un Pod. Notez qu'aucun Pod supplémentaire ne serait activé dans cet exemple, étant donné que chaque Pod contient suffisamment de marge pour évoluer. Étant donné que tout est mis à l'échelle au sein d'un Reactive Engine, ce processus est extrêmement rapide et efficace, nécessitant seulement quelques ressources supplémentaires par instance et aucune intervention au niveau de Kubernetes.
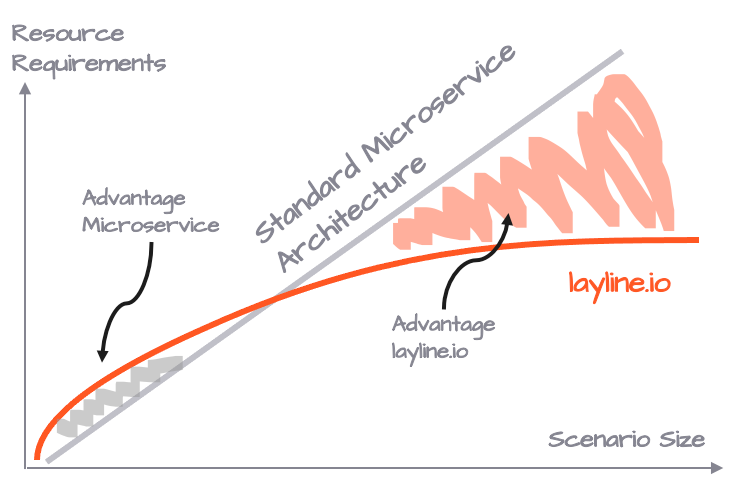
Avantage Ressources
Il est logique de penser qu'il faudra une puissance CPU et une RAM respectives, que vous distribuiez 30 Pods avec le même microservice sur trois Nodes, ou trois Reactive Engines avec 10 instances du même Workflow chacun sur trois Nodes. Mais ce n'est pas le cas.
Selon les caractéristiques du microservice remplacé par un Workflow, vous économisez généralement entre 25 et 50 % des ressources par rapport à la méthode traditionnelle de déploiement des microservices. Cependant, il est également vrai qu'un Reactive Engine exécutant une seule instance de Workflow nécessite plus de ressources qu'un microservice personnalisé exécuté une seule fois.
C'est un compromis entre flexibilité et exigences en ressources, qui penche rapidement en faveur du modèle layline.io avec la taille de votre scénario de traitement.
Avantage Configuration
Configurer layline.io dans un cluster Kubernetes/Docker signifie déployer le même conteneur sur chaque Node. Chaque conteneur exécute un Reactive Engine et il n'y a pas d'autres types de conteneurs avec un contenu différent. Juste un seul.
Pour qu'un Reactive Engine sache quels Workflows exécuter, une configuration est injectée au moment de l'exécution. Étant donné que tous les Reactive Engines forment leur propre Reactive Cluster, il suffit d'injecter la configuration dans un seul Reactive Engine. Elle est ensuite automatiquement distribuée à tous les autres Engines du Cluster. Encore une fois, tout cela peut être déclenché manuellement ou automatiquement via des outils CI/CD.
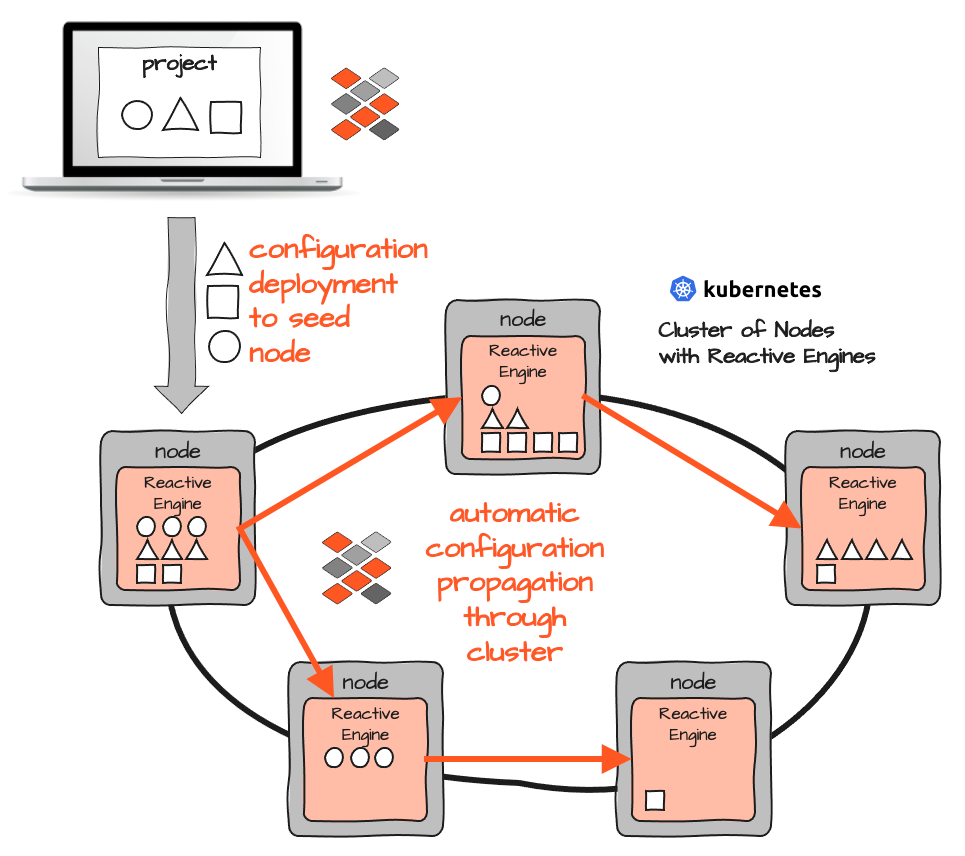
Ainsi, contrairement au concept Kubernetes/Docker pur, il n'y a pas de tracas avec différents Pods contenant différents conteneurs qui doivent être reconstruits à chaque changement, puis gérés du point de vue du déploiement. Contrairement à Kubernetes, vous n'avez pas à réfléchir à l'endroit où exécuter quel Pod/Conteneur à l'avance, ou comment réorganiser les Pods en cas de besoin de les réarranger. Dans layline.io, vous pouvez simplement activer un Workflow préchargé dans un ou plusieurs Reactive Engines, ou déployer une nouvelle configuration de Workflow dans le Cluster pour mettre ce Workflow en ligne.
Résumé
| Aspect | Kubernetes/Docker | layline.io |
|---|---|---|
| Mise à l'échelle | Mise à l'échelle via Pods | Mise à l'échelle au sein du Pod via des instances de Workflow |
| Temps de réaction de la mise à l'échelle | moyen | rapide |
| Consommation de ressources | Meilleure pour les petits scénarios | Meilleure pour les scénarios moyens à grands |
| Configuration | De nombreux Pods et Conteneurs différents | Configurations injectées dans le Reactive Engine |
Kubernetes est excellent. Point final. Mais il y a des inconvénients en termes de complexité et d'opérations.
layline.io offre une méthode bien meilleure et plus légère non seulement pour créer et gérer des Services, mais aussi pour les gérer et les distribuer dans un environnement de Cluster. Pour les scénarios moyens à grands, il y a également un avantage significatif en termes de gestion et de consommation des ressources.
Vous pouvez télécharger et utiliser layline.io gratuitement ici. Si vous avez des questions sur layline.io, n'hésitez pas à nous contacter !
Ressources
- Télécharger layline.io
- Réparer ce qui ne va pas avec les microservices
- En savoir plus sur layline.io ici.
- Contactez-nous à hello@layline.io.


