
デモンストレーション内容
今回は、ファイルからデータを読み取り、その内容をKafkaトピックに出力するシンプルなlayline.ioプロジェクトを紹介します。
実際のセットアップでこのデモを追うには、ページ下部のリソースセクションからこのプロジェクトのassetsをダウンロードできます。プロジェクトを環境にインポートする方法については、こちらをお読みください。
設定
ワークフロー
概要
このデモのワークフロー設定は、layline.ioのWorkflow Editorを使用して構成されており、以下のようになっています:
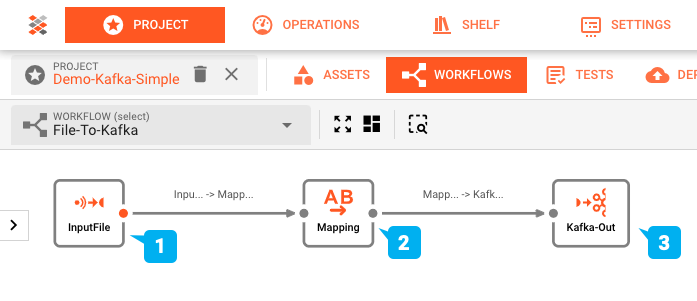
- (1) Input Processor: ヘッダー/詳細/トレーラー構造の入力ファイルを読み取り、
- (2) Flow Processor: これを出力フォーマットにマッピングし、その後
- (3) Output Processor: Kafkaトピックに書き込みます。
このデモの目的のために、Cloud KarafkaがホストするKafkaトピックを使用しています。そのため、デモを自分で実行する場合、自分のKafkaインストールは必要ありません。
基礎となるAssetsの設定
ワークフローは、Asset Editorを使用して設定された多くの基礎となるAssetsに基づいています。ワークフローとAssetsの論理的な関連性は以下のように理解できます:
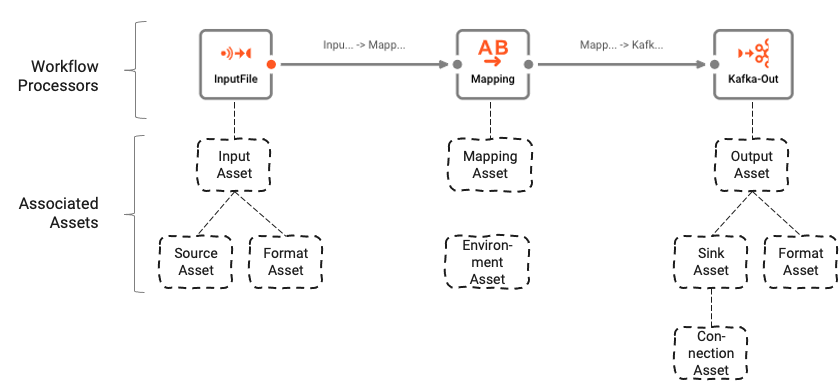
Workflowsは、リンクで接続された多数のProcessorsで構成されています。
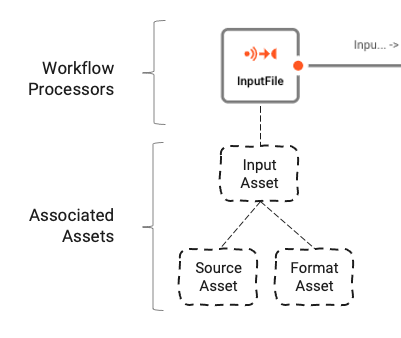
ProcessorsはAssetsに基づいています。Assetsは特定のクラスとタイプの構成エンティティです。上の画像では、「InputFile」という名前のProcessorが、クラスInput ProcessorでタイプStream Input Processorであることがわかります。これは、タイプFile System SourceとGeneric Formatの2つの他のassets「Source Asset」と「Format Asset」に依存しています。
要するに:
- ワークフローは相互に接続されたProcessorsで構成されています
- Processorsはそれを定義するAssetsに依存しています
- Assetsは他のAssetsに依存することがあります
環境Asset: "My-Environment"
まず、layline.ioはEnvironment Assetsを使用して複数の異なる環境を管理するのに役立ちます。これは、テスト、ステージング、本番環境で異なるディレクトリ、接続、パスワードなどが必要な場合に同じプロジェクトを使用する際に非常に役立ちます。このプロジェクトでは1つのEnvironment Asset (2)を使用しています。
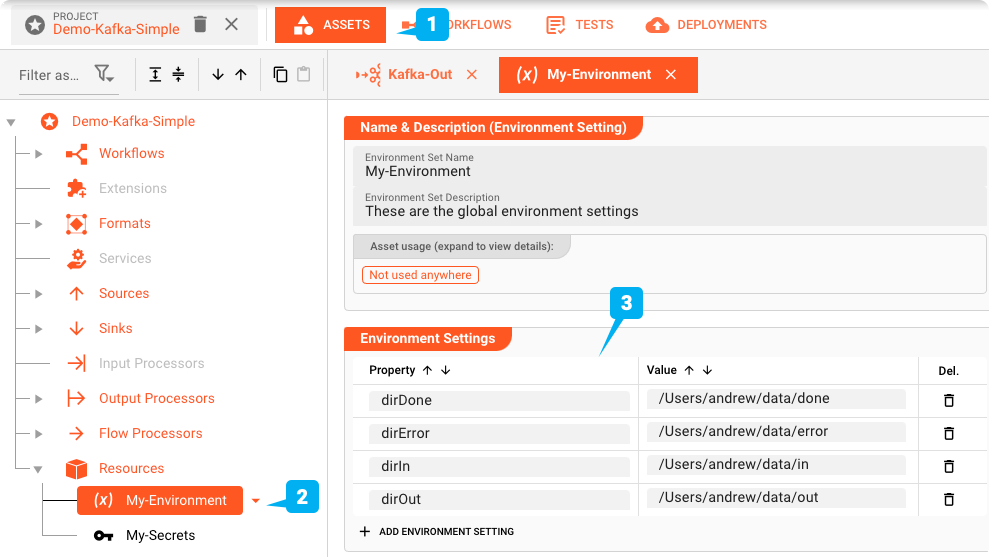
このような変数は、${lay:dirIn}のようなマクロを使用してプロジェクト全体で使用できます。OSまたはJavaシステム環境変数は、それぞれenv:またはsys:でプレフィックスされ、lay:の代わりに使用されます。
Stream Input Processor: "InputFile"
Input Processor(名前:InputFile / タイプ:Stream Input Processor)は、入力ファイルの読み取りとワークフロー内でのデータの下流への転送を担当します。
Generic Format Asset: "InputFileFormat"
layline.ioは独自の文法言語で複雑なデータ構造を定義する手段を提供します。この例のファイルは銀行取引のサンプルです。ヘッダーレコードには2つのフィールドがあり、取引の詳細を保持する多数の詳細レコードがあり、最後にトレーラーレコードがあります。
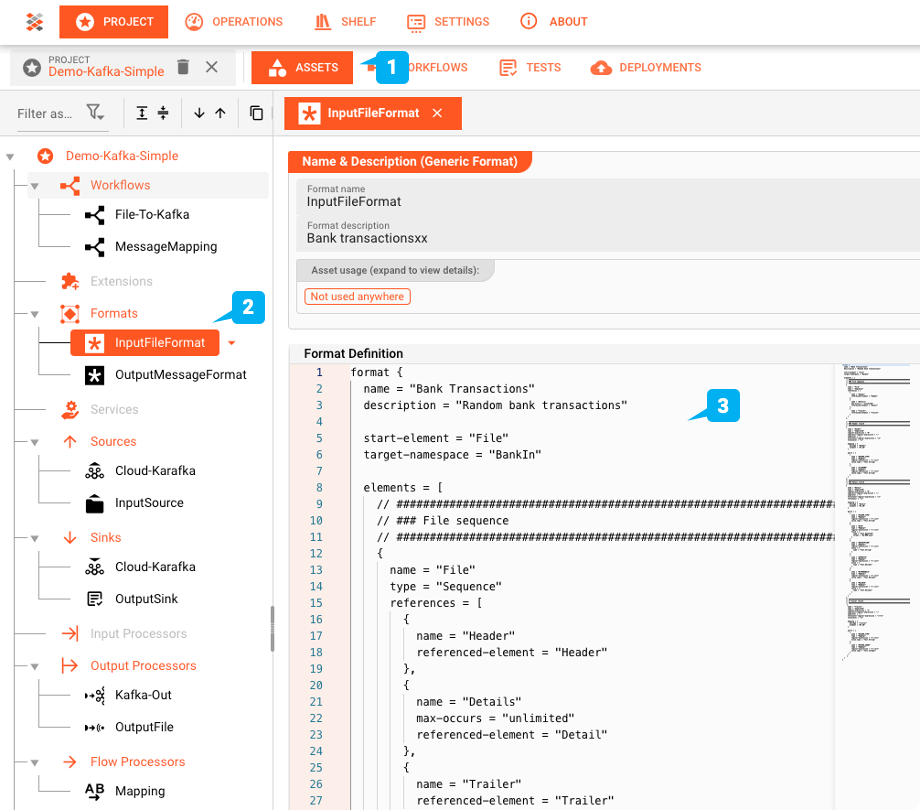
File-System-Source Asset: "InputSource"
"InputSource"は、ファイルが読み取られる場所を定義するために使用されるタイプFile System SourceのAssetです。
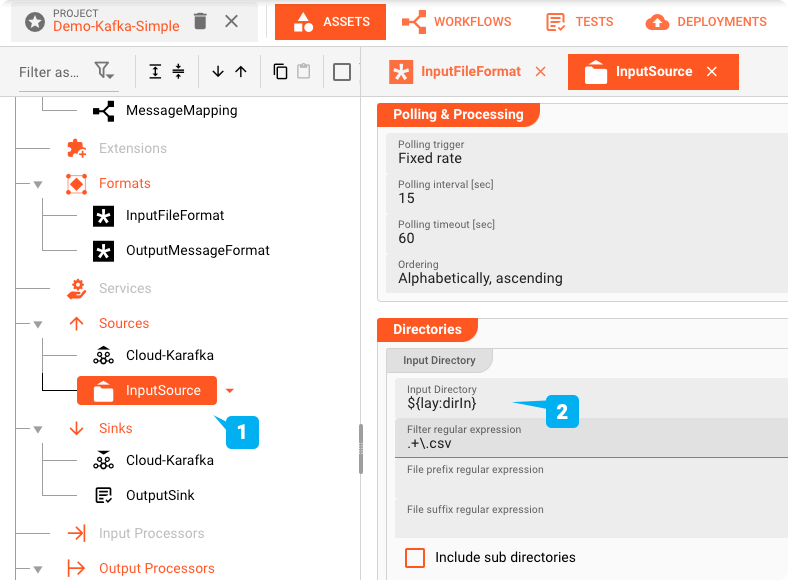
Flow Processor: Map
Mapping Assetを使用すると、入力から出力フォーマットへの値のマッピングが可能です。
Stream Output Processor: Kafka
ワークフローの最後のProcessorは、Output Processor "Kafka-Out"です。
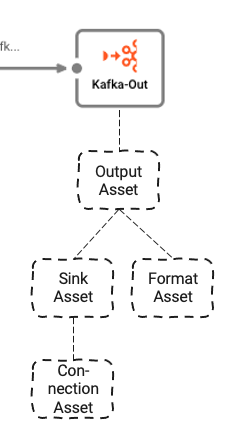
これは3つの基礎となるAssetsに依存しています:
- Output Asset: 書き込むKafkaトピックとパーティションを定義します
- Kafka Sink Asset: Output Assetがデータを送信するために使用できるSink
- Generic Format Asset: Kafkaにデータを書き込む形式を定義します
- Kafka Connection Asset: 物理的なKafka接続パラメータを定義します
Kafka Connection Asset: "Cloud-Karafka-Connection"
Kafkaに出力するためには、まずKafka Connection Assetを定義する必要があります。
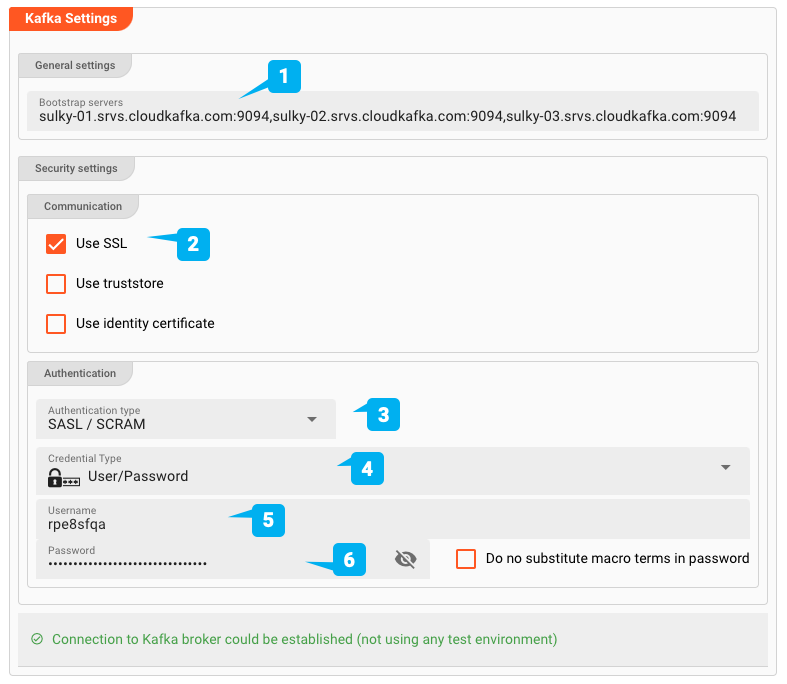
- (1) Bootstrap servers: 1つ以上のBootstrapサーバーのアドレス
- (2) Use SSL: これがSSL接続であるかどうかを定義します
- (3) Authentication type: SASL / Plaintext、またはSASL / SCRAM
- (4/5/6) Credentials: ユーザー名/パスワード
デプロイと実行
デプロイの転送
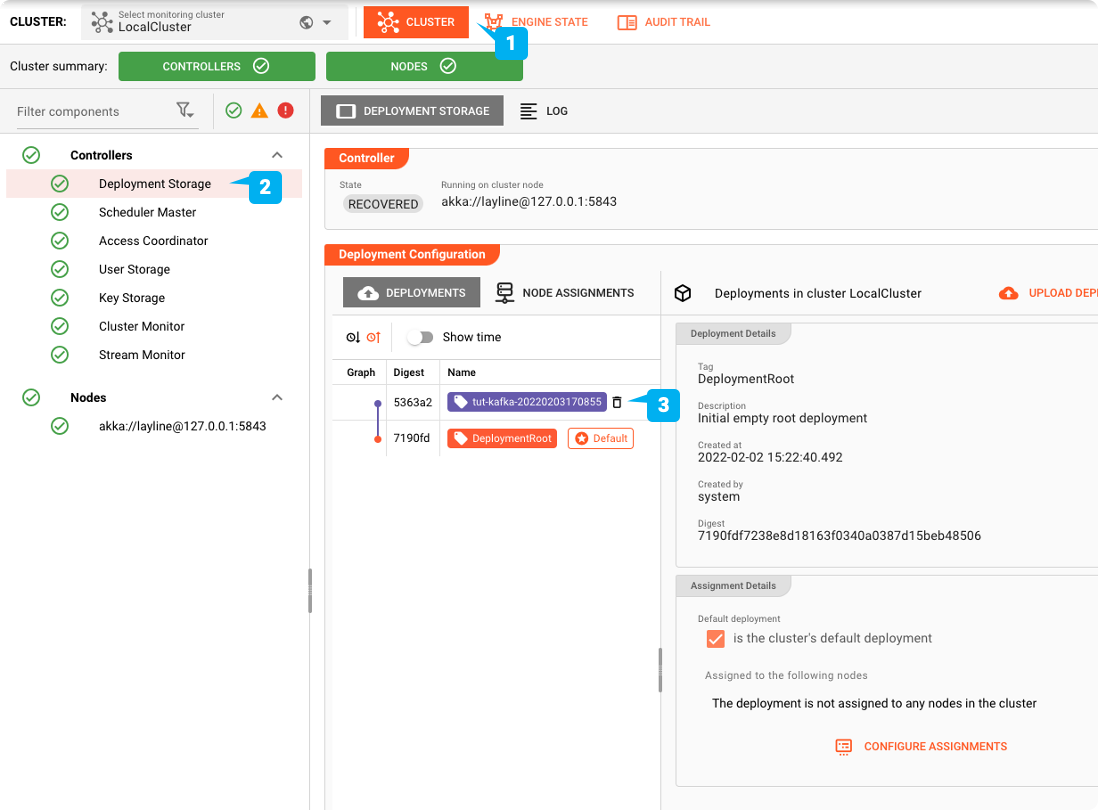
デプロイするには、プロジェクトのDEPLOYMENTタブに切り替えます:
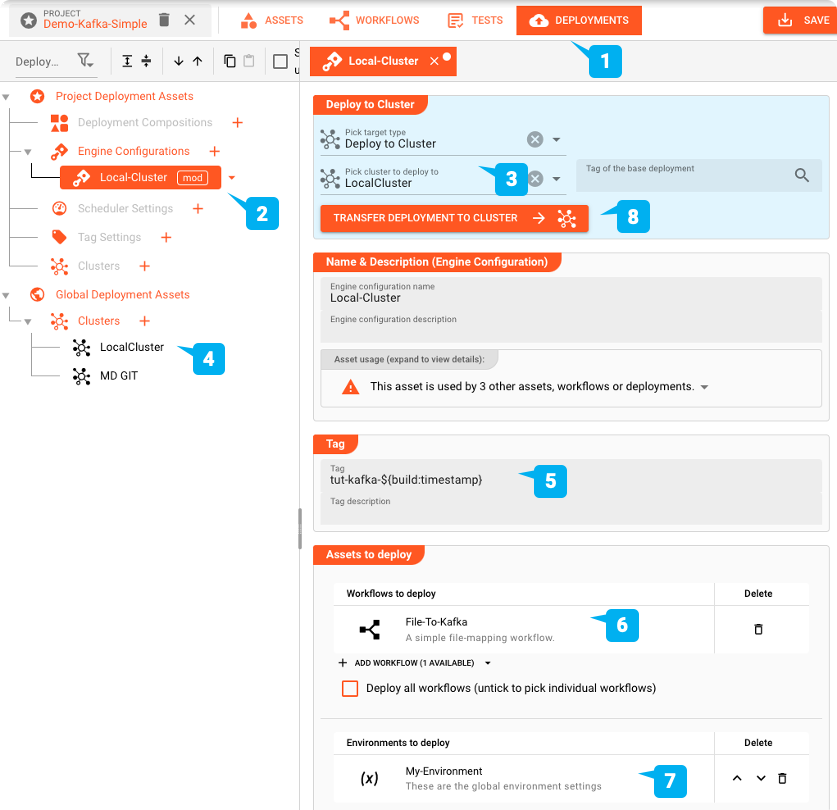
プロジェクトをデプロイするためのEngine Configurationを作成します。これは、デプロイしたいプロジェクトの部分を定義します。
デプロイの有効化
"CLUSTER"タブに切り替えます:
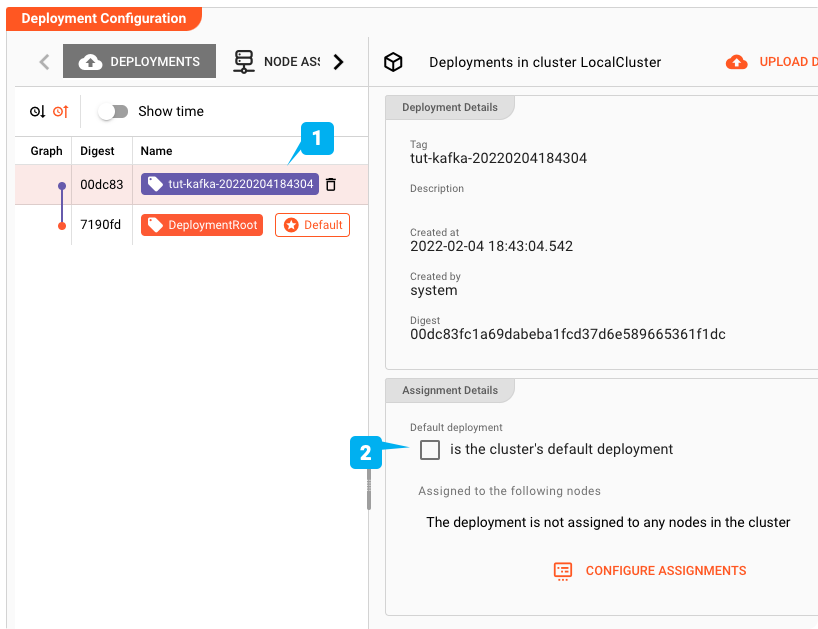
デフォルトのデプロイにする
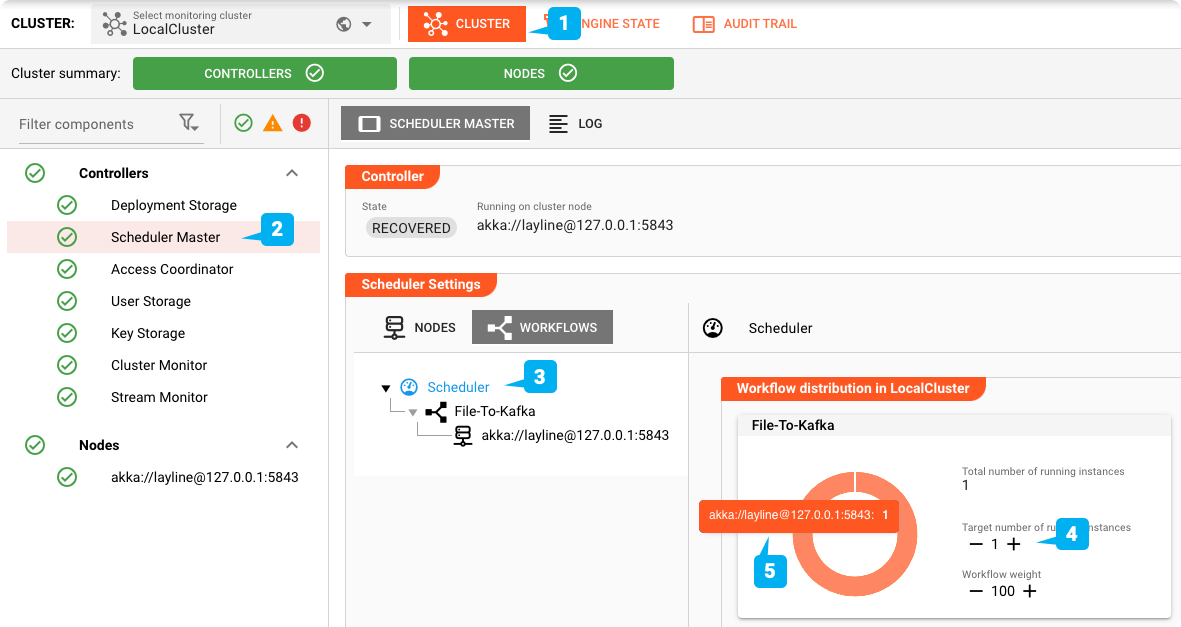
スケジュール
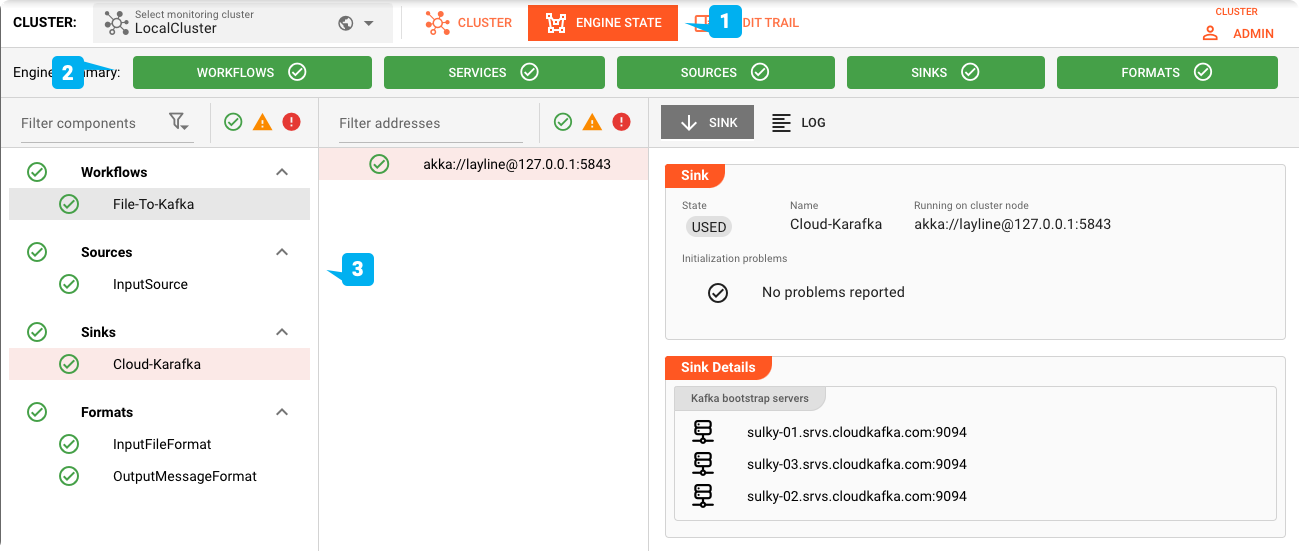
エンジンステータス
テストファイルの投入
テストするには、設定した入力ディレクトリにテストファイルを投入します。
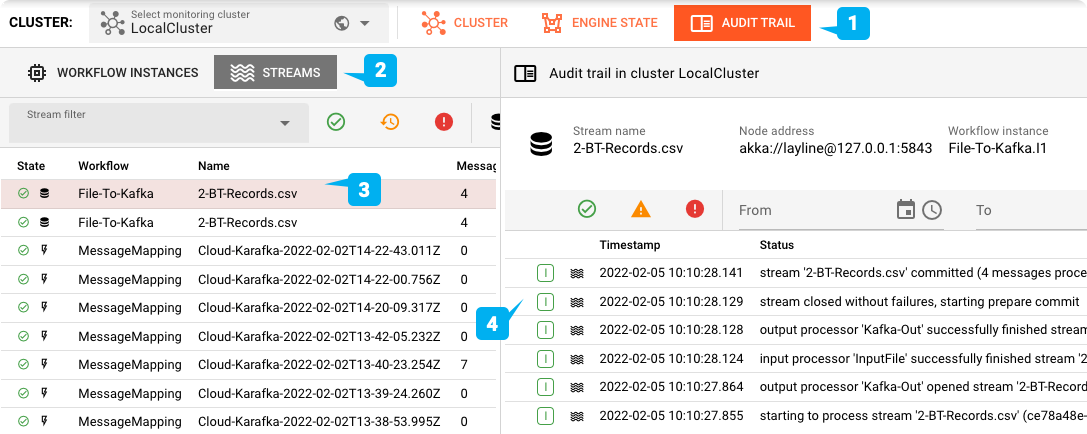
お好みのツールを使用してCloud Karafkaトピックを確認できます:

まとめ
このデモでは、File-to-Kafka Workflowを簡単に作成する方法を紹介しました。そして、以下のような多くの利点を即座に得ることができます:
- Reactive — リアクティブ処理パラダイムを採用
- High scalability — 単一のエンジンインスタンス内およびそれを超えてスケール
- Resilience — 分散環境でのフェイルオーバーセーフ
- Automatic deployment — 変更された設定をワンクリックでデプロイ
- Real-time and batch — 同じプラットフォームを使用して両方を実行
- Metrics — 監視のための自動メトリック生成(例:Prometheus)
リソース
| # | 説明 |
|---|---|
| 1 | Github: Simple Kafka Project |
| 2 | プロジェクトのディレクトリ_test_filesにある入力テストファイル |
| 3 | ファイルcloud-karafka-credentials.txtにあるCloud Karafkaの認証情報 |
- layline.ioについてもっと読むにはこちら。
- hello@layline.ioまでご連絡ください。

