知見と最新情報
データ統合、イベント処理、スケーラブルなワークフロー構築に関する記事、チュートリアル、知見をお届けします。


AIデータエンジニア: 実際に変わったこと(そして変わらなかったこと)
すべての競合ブログが「AIがデータエンジニアリングを変えている」と発表しています。それはすべて息をのむようで曖昧です。ここでは正直なインベントリを紹介します — LLMツールが本当に役立つこと、まだ触れられないこと、そして「80%自動化」の主張が実際の運用に接触すると生き残れない理由。

データ契約はあなたのData Pipelineに必要なAPIバージョニングです
スキーマドリフトはパイプラインを壊し続けています。なぜなら、変化を監視する代わりに契約を強制しているからです。ここでは、なぜデータ契約がプロデューサーとコンシューマーの間の欠けている層なのかを説明します。

ビジネスコンテキストのないデータ系譜は虚栄の指標
ほとんどの系譜ツールは美しい図を作成しますが、重要な質問に答えません。それは「このデータが間違っていると何が壊れるのか?」という質問です。ここでは、観測可能性の演技からビジネスに不可欠な系譜へと移行する方法を紹介します。

私が「ベストプラクティス」を信じるのをやめ、「Works For Us」を信頼し始めた理由
私は18か月間「完璧な」アーキテクチャを構築しました。しかし、顧客がそれを20分で削除し、cronジョブで置き換えるのを見ました。ここで私が「ベストプラクティス」の罠について学んだことと、なぜ退屈な技術がしばしば勝つのかをお話しします。

50のデータパイプラインの事後分析から学んだこと
Uber、Netflix、Stripeなどの50の公開事後分析を分析した結果、4つの失敗パターンが繰り返し現れることがわかりました。そのほとんどは設計段階で防ぐことができます。

あなたはAirflowの複雑さから逃れたわけではありません — それを分散させただけです
Airflowの横にKestra、Dagster、またはPrefectを追加しても、オーケストレーションの複雑さは減りません。それは増えるのです。隠れた調整の負債が実際にどのように見えるか、そしてそれに対処する方法について説明します。

データチームが成果を出せない理由:誰も語らない組織的ボトルネック
データチームの生産性を妨げる最大の要因は技術ではなく、組織的な摩擦です。承認チェーン、ツールチェーンの断片化、不明確な所有権がどのようにボトルネックを生み出し、どんなに優れたエンジニアリングの才能でも克服できないかを解説します。

QlikがTalendを買収 – 買収後の更新と代替案に関する観察
Talendの顧客の中には、QlikによるTalendの買収後、更新価格が大幅に上昇したと報告する人もいます。この記事では、公開されている情報と個々の顧客の経験を共有し、選択肢を評価する企業が考慮すべき点を概説します。

ソースシステムが予告なしに変更されたとき、パイプラインに何が起こるか
スキーマドリフトと上流の破壊的変更は、サイレントデータ障害の主な原因です — しかし、ほとんどのパイプラインコンテンツはインフラストラクチャに焦点を当てており、ソースシステムの動作には焦点を当てていません
ソースシステムが予告なく変更されたとき、パイプラインに何が起こるか
スキーマドリフトと上流の破壊的変更は、サイレントデータ障害の主な原因です。予期せぬ事態に備える方法をご紹介します。

金融データ統合: 実践ガイド
金融データ統合とは何か?金融データの統合が特に難しい理由、通常のETLとどのように異なるのか、そしてチームがそれを解決するために使用する実証済みのパターンについて学びます。

layline.io 対 Apache Kafka: どちらを選ぶべきか
ストリーム処理アプローチの実践的な比較 — レイテンシー、運用の複雑さ、そして実際に正しい選択を決定するチームの適合性をカバー

なぜリアルタイムデータ統合が現代のアプリケーションにとって重要なのか
ニアリアルタイムと実際のリアルタイムの違い、そしてそのギャップが思った以上にコストをかける理由

なぜほとんどのデータパイプラインは午前3時に失敗するのか(そして失敗しないものを構築する方法)
夜中に本番データパイプラインが壊れる本当の理由と、それを防ぐエンジニアリングプラクティス

誰も求めなかったストリーミング移行
あるフォーチュン500のデータアーキテクトが、Kafkaへの移行に14か月を費やしたと話してくれました — そして静かにパイプラインの半分をバッチに戻しました。なぜそれが繰り返されるのか、そして私ならどうするかをお伝えします。

Airflowパイプラインをリアルタイム化する必要があるとき
Airflowを稼働させています。チームはそれを知っています。DAGは機能しています。それなのに、なぜ突然「リアルタイムが必要だ」という声が聞こえてくるのでしょうか?そして、それに対して実際に何をすべきなのでしょうか?

実際にコストを削減するEdge Processing
ローカルデータフィルタリングがクラウド料金を90%削減する方法 — あなたのケースではどうなるか

バッチからストリーミングへ: モダンなデータパイプラインへの実践ガイド
なぜリアルタイムデータが重要なのか、移行が難しい理由、そして移行についてどのように考えるべきか — layline.ioを選ぶにせよ他の道を選ぶにせよ

クラウド請求書からの呼び出し。サーバーレスについて話したいことがあります。
見えないスケーリングから見えない請求書へ—エンジニアリングチームがFaaSを捨て、持続的で予測可能なデータエンジンを選ぶ理由。
layline.ioでApache Pekkoの力を発見
layline.ioでは、Apache Pekkoの強力な機能を活用して、包括的なローコードイベント処理プラットフォームを提供しています。私たちのソリューションを使用すれば、コードを一行も書くことなくApache Pekkoの可能性を最大限に引き出すことができます。

layline.ioによるデータオーケストレーションの力: Ubiquity Unifiショーケースシナリオ
データが支配する時代において、膨大な情報の管理とオーケストレーションは、多くのビジネスや産業の基盤となっています。

layline.io: イベントデータ処理の専門知識でハンブルクのITスタートアップシーンを変革
layline.ioは、EU Startup Newsによってドイツのハンブルクで最も影響力のあるITスタートアップの一つに選ばれました。
H-Hotels.com - layline.ioによるデジタルトランスフォーメーション
ホスピタリティ業界は近年、技術的進歩を大きく遂げています。これには、業界が業務を最適化するために活用できる最も重要なツールの一つであるデータインテグレーションソフトウェアが含まれます。

イベント駆動型非同期データ処理の利点
今日の急速に変化するビジネス環境では、あらゆる企業が大量のデータをより効率的に処理する方法を模索しています。従来のデータ処理手法には限界があり、そのため企業はイベント駆動型の非同期データ処理に注目し始めています。

layline.io - Kafkaとの比較
layline.ioはKafkaとどのように比較されるのでしょうか?これは時々耳にする質問です。私たちはなぜか不思議に思います。

サンプルシリーズ: Http-Client-Requests
ReSTインターフェースは人気があり豊富です。Yahoo Financeを例にして、layline.io内でHttp-Clientリクエストを設定する方法をお見せします。
リアルタイムデータのSniffing
複雑な処理シナリオで実際に何が起こっているのかを理解するのは難しいです。layline.ioは、実行時に複雑なWorkflowsの内部動作への洞察を得るためのプロービングツールを提供することで支援します。
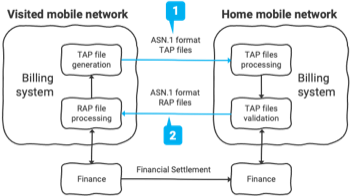
ASN.1フォーマット設定
ASN.1は依然として人気のあるデータフォーマットです。layline.ioで任意のASN.1フォーマットをどれほど簡単に設定できるかを学びましょう。
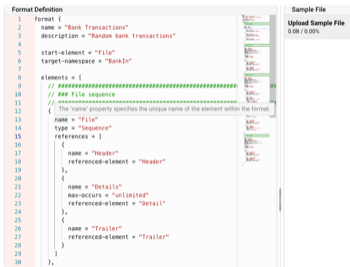
データフォーマット地獄を打破せよ
複雑なデータフォーマットやその変更に対処することは困難です。 layline.ioがどのようにしてこの課題に取り組むか、設定可能な文法言語を使用して学びましょう。

Kafkaへの出力
構造化ファイルからデータを読み取り、レコードデータをマッピングし、Kafkaクラウドにデータを出力する方法を紹介します。
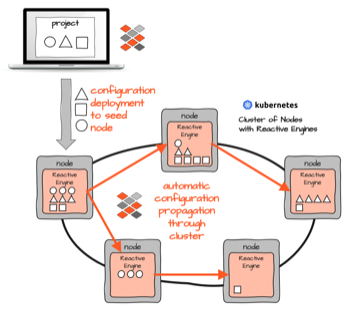
従来のK8S/Dockerモデルを使用したマイクロサービスと比較したlayline.io Workflowsの利点
Kubernetes/Docker上の従来のマイクロサービスモデルには、管理が過度に複雑になり、リソース消費が増加するという欠点があります。その背景とlayline.ioがどのように役立つかを説明します。
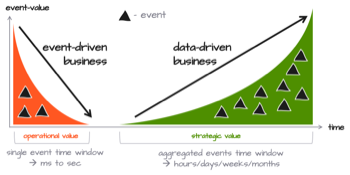
イベント駆動か破滅か!?あなたのビジネスがイベント駆動でない場合、見逃していることがある?
データ駆動だけでは見逃しているかもしれません。実際、すべてのビジネスはデータ駆動です。しかし、それが本当に何を意味するのか、そしてそれが明日あなたにとって十分であるかどうかを自問するべきです。
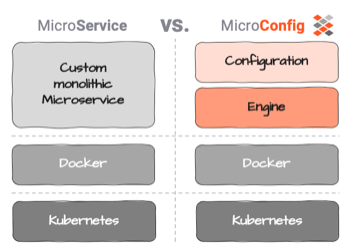
マイクロサービスの問題を修正する
ここ数年、マイクロサービスとサービス指向アーキテクチャが流行しています。しかし、欠点もあります。それらを克服できるのでしょうか?

メッセージベースのシステムにおけるデータプレッシャーへの対処
ノンストップのメッセージ駆動型ソリューションでデータプレッシャーに対処し、負荷がかかっている状態でもノンストップの稼働時間を確保する方法。
最新情報を受け取る
最新の記事、チュートリアル、アップデートを受信トレイに直接お届けします。
スパムはありません。いつでも解除できます。