
layline.ioはKafkaとどう比較されるのか?
これは時々耳にする質問です。なぜそうなのか不思議に思います。理解を深めるために、Kafkaとは何かを見てみましょう。
Kafkaとは何か?
AWSは次のように説明しています:
「Apache Kafkaは、リアルタイムでストリーミングデータを取り込み、処理するために最適化された分散データストアです。ストリーミングデータとは、通常同時にデータレコードを送信する何千ものデータソースによって継続的に生成されるデータです。ストリーミングプラットフォームは、このデータの絶え間ない流入を処理し、データを順次かつ段階的に処理する必要があります。
Kafkaはユーザーに以下の3つの主要な機能を提供します:
- レコードのストリームを公開および購読する。
- レコードが生成された順序でストリームを効果的に保存する。
- レコードのストリームをリアルタイムで処理する。
Kafkaは主に、リアルタイムのストリーミングデータパイプラインとデータストリームに適応するアプリケーションを構築するために使用されます。メッセージング、ストレージ、ストリーム処理を組み合わせて、履歴データとリアルタイムデータの両方の保存と分析を可能にします。」
Kafkaに対する我々の見解
上記の説明には技術的な専門用語が少し含まれており、これに対処する必要があります。ストリーミング処理、リアルタイムなどについて述べています。これはKafkaの文脈で何を意味するのでしょうか?
- Kafkaはまずデータストレージソリューションです。 データがキュー(トピック)に保存される特別なタイプのデータベースとして見るべきです。これらのキューに書き込む(公開)方法や読み取る(購読)方法はさまざまです。キューはFIFO原則(先入れ先出し)に従います。Kafkaはストアではなくストリーミングイベントプロセッサであるという主張もありますが、これは誤解を招くと我々は考えています。Kafkaはデータを保存し、そのデータを消費者が迅速に読み取るために設計されています。データが消費されたかどうかにかかわらず、事前に設定された保持期間後に保存されたデータを削除するように設計されています。その意味では、非常に特殊で有用な機能を備えた一時的なデータストアです。
- 個々のプロセスはキューに公開(プロデューサー)したり、キューを購読(コンシューマー)したりできます。 目的に合った既製のコネクタ(下記参照)がない場合(おそらく)、自分でカスタムコードを作成する必要があります(ほとんどはJavaを使用しますが、他のオプションもあります)。
- Kafkaはクラウドネイティブで分散環境で実行できます、これにより回復力とスケーラビリティが提供されます。
Confluent(会社)は、Kafkaに「コネクタ」と呼ばれる事前に作成された機能を追加しました。コネクタは、特定の種類のデータソース/シンクをKafkaトピックから/へ読み書きできる特別なタイプのプロデューサーとコンシューマーです。これらはできることが非常に限られており、専門的です。
さらに、「ksql」を使用してデータを「フィルタリング、ルーティング、集約、マージ」する機能を作成しました。これは、Kafkaトピックからリアルタイムで情報をフィルタリングおよびルーティングできることを示唆しています。素晴らしいことのように聞こえますが、これはKafkaトピックからデータを読み取り、フィルタリング、集約、マージし、結果を別のトピックにルーティングして他のコンシューマーが読み取るための別のタイプのコンシューマーにすぎません。これを論理的に比較する最良の方法は、SQLを使用してデータをあるテーブルから別のテーブルにコピーするテーブル駆動型データベース(例:Oracle)のアナロジーを使用することです。ただし、Kafkaでははるかに複雑です。
Kafkaにはデータを変換するための意味のある機能はほとんどありません。ここでの大きな障害の1つは、Kafkaにはデータを解析する固有の機能がないため、データを操作することができないことです。非常に限られたデータフォーマットしかサポートしていません。通常とは異なるもの(おそらく)は、プロデューサーとコンシューマーをカスタムコードで作成する必要があります。これは、主に内部に関心を持ち、外部には関心を持たない他のデータベースと同様です。全体として、Kafkaは実際にはデータを処理しないと言えます。単にデータを保存するだけです。他のシナリオは、プロデューサーとコンシューマーを持つ原子的なトピックを連鎖させることを意味します。
Kafkaは操作が難しいことでも知られています。包括的なユーザーインターフェースはありません。ほとんどすべてが設定ファイルで設定され、コマンドラインから操作されます。
まとめ
Kafkaの主な用途は次のとおりです:
- 高速データストレージ
- 大量のデータ
- 迅速に生成および消費される
この目的のためにKafkaを愛しています。素晴らしいものであり、実装において頻繁に利用していますが、これを達成するための他のソリューションもいくつかあります。
layline.ioとは何か?
layline.ioは、高速でスケーラブルで回復力のあるイベントデータプロセッサです。リアルタイムでデータを取り込み、処理し、出力することができます。処理とは、Kafkaが行う(保存する)こととは対照的に、データに対して「何かをする」ことを意味します。Kafkaとの大きな違いは、layline.ioではすべてが「Workflows」の概念を中心に展開されることです。Workflowsは、通常複雑なデータオーケストレーションに似たデータ駆動型のロジックを反映します。
これは次のように翻訳されます:
- データを解釈する、
- 分析する、
- リアルタイムで他のソースを参照して潜在的に強化する
- 統計を作成する
- フィルタリングする、
- ルーティングする、
- 異なるデータソースとシンクを統合する。
そしてこれらすべてを:
- リアルタイムで、
- トランザクションセキュア(オプション)で、
- ストレージのオーバーヘッドなしで、
- 設定可能で、
- UI駆動で
- さらに多く
例のWorkflow:
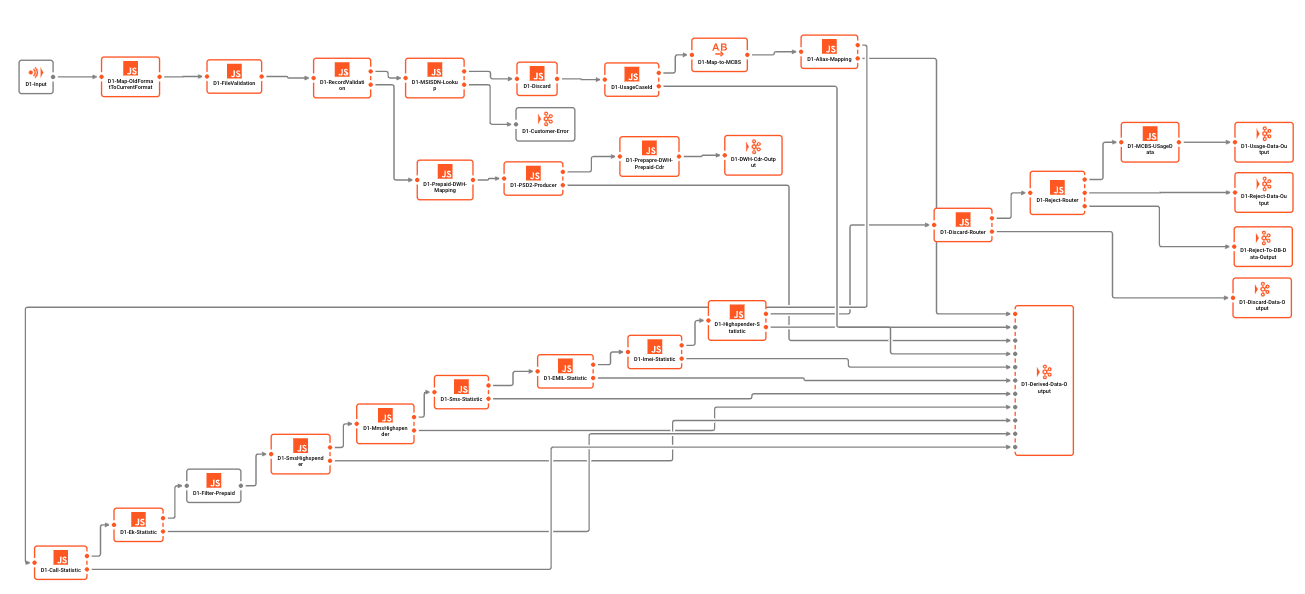
Kafkaは設計上Workflowsをサポートしていません。KafkaでWorkflowと解釈される可能性のあるものは、むしろKafkaキューとコンシューマー/プロデューサーの連鎖をWorkflowとして「売る」試みです。ただし、これらはそれぞれが個別のエンティティであり、互いに認識していません。Kafka内にWorkflowsをサポートする実際のサポートもありません。
Kafkaとlayline.ioの組み合わせ
Kafkaの視点から見ると、layline.ioはプロデューサー(書き込み)またはコンシューマー(読み取り)として見られます。layline.ioの視点から見ると、Kafkaは他のデータストア(SQL DBs、NOSQL DBs、ファイルシステムなど)と比較可能なイベントデータストアとして見られます。これは、ユースケースに応じて素晴らしい組み合わせです。この文脈でlayline.ioは、理論上無制限の数のKafkaトピックと、Kafka領域外の他のソースとシンクの間のデータオーケストレーション要素として機能します。
その観点から、Kafkaとlayline.ioは非常に補完的であり、競合するものではありません。重複は最小限です。潜在的な顧客がどちらか一方を選ぶという意味のあるシナリオは見当たりませんが、むしろ両方を選ぶでしょう。
今日のKafkaユーザーはどのように対処しているのか?
今日の典型的なKafkaユーザーは、Kafkaをそのままのものとして使用しています:特別な種類のイベントデータストアです。それにデータを書き込み、読み取るために使用しています。彼は主にカスタムコードでコンシューマーとプロデューサーを作成します。これらのカスタムコードされた部分は、上記のポイント1から6を含む必要があります(ヒント:含まれません)。さらに、それらは回復力、スケーラビリティ、レポート、モニタリング、およびそのようなコンポーネントから期待されるすべてを保証しません。これらはしばしばPythonのような単純なスクリプトツールを使用して構築され、より洗練されたマイクロサービスフレームワーク(Spring Bootなど)を使用して構築されます。
これの代わりに、layline.ioを使用することで、上記のすべてを得ることができます。
実際の導入例
この実際の顧客は、layline.ioを使用してすべての顧客使用データ(通信メタデータ)の処理を行っています。
layline.ioの実装前は、前述のシナリオに非常に似た状況にありました。いくつかのKafkaキューが単一のカスタムコードプロセスによって供給されていました。他のそのようなプロセスはそれらのキューから読み取り、他のターゲットに他のフォーマットでデータを書き込み、いくつかのロジックを適用しました。維持コストが高く、管理がほぼ不可能な混乱したエラーが発生しやすいアーキテクチャでした。
layline.ioの実装後、以前のビジネスロジックとプロセッサーが置き換えられた結果、アーキテクチャは次のようになりました:
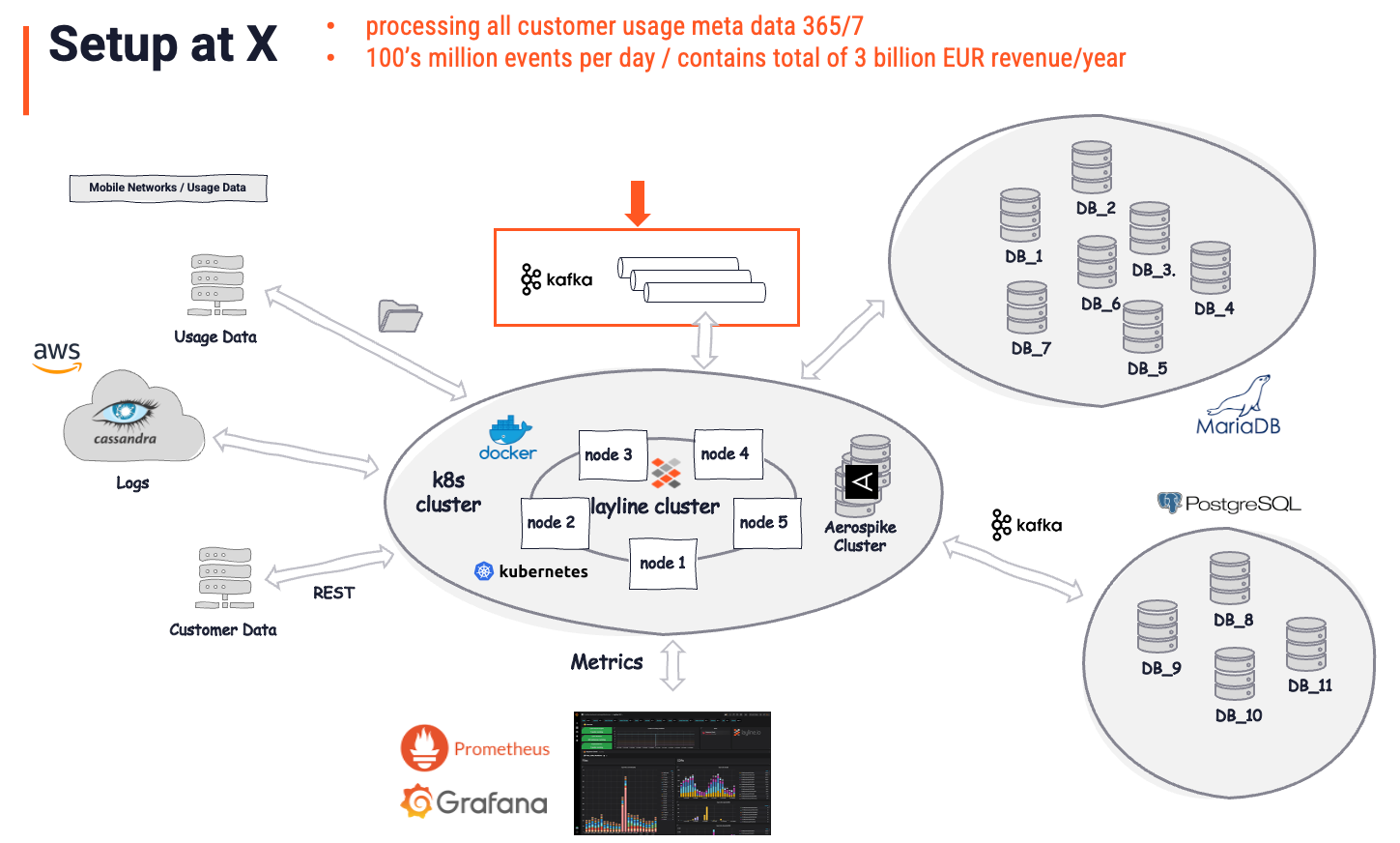
全体像は「ソリューション」と見なされます。重要なのは、layline.ioが実際のソリューションとして認識されていることです。一方、Kafkaは単なる(重要な)ストアです。layline.ioの前にKafkaが存在していました。全体のソリューションにおいて比較的小さな役割(赤い矢印とボックス)を果たしていますが、定義上まさにそれである一時的なデータストアとして機能しています。すべてのインテリジェントなデータ分析、強化、フィルタリング、変換、ルーティング、複雑なビジネスロジックなどは、layline.ioによって処理されます。Kafkaを使用して達成することが不可能なレベルのタスクです。これのどの部分がKafkaに起因するかを尋ねると、顧客の答えはおそらく「全体のソリューションの5%」でしょう。
結論
Kafkaは広くメッセージバスと見なされていますが、実際にはデータを動かすために他のアプリケーションを支援するデータの静止に関するものです。この文脈で、ユーザーの視点から見た実際のアプリケーションは、クライアントAPIを使用してKafkaからデータを供給されるものです。対照的に、layline.ioはアプリケーションのロジックの不可欠な部分を形成します(例を参照)。layline.ioは循環系プラスロジックのようなものであり、Kafkaは単に外部のよく整理された貯水池です。したがって、Kafkaとlayline.ioの重複は最小限です。
Kafkaを運用している顧客は、「Kafkaに加えてlayline.ioが意味をなすかどうか」を疑問視しません。同様に、我々はデータストアとしてのKafkaの使用を疑問視しませんが、目的に適したデータストアであるかどうかを疑問視します。顧客はむしろ、layline.ioを使用して(Kafkaが対処しない)問題をどのように解決するかを疑問視します。彼らは新しいことを行うか、過去にある程度カスタムコードされた既存のプロセス(例:マイクロサービス)を置き換えるかもしれません。
付録:layline.ioとKafkaの簡単な比較
完全な比較ではありませんが、役立ちます:
| 項目 | Kafka | layline.io |
|---|---|---|
| タイプ | メッセージキュー | 並行プラットフォーム |
| Workflowサポート | 実際にはありません。ただのストアです。 | ソリューションの一部として組み込まれています |
| データストア | はい | いいえ |
| データフォーマットサポート | データフォーマットの理解はありません。ksqlのコンテキストでのみ、CSV、JSON、Avro、ProtoBufなどのフォーマットを限定的にサポートします。 | データ内容の完全な理解。強い型付け。ASCIIやバイナリ、階層構造、ASN.1など、非常に複雑なデータフォーマットをサポートします。 |
| ビジネスロジック | サポートなし | フルサポート。これはストアとデータ処理ソリューションの大きな違いです。 |
| データ強化 | サポートされていません。データ強化のために第三者を参照することはできません。 | フルサポート。 |
| リアルタイム | Kafkaはストアです。これは、ストア(バッファ)からデータを読み取るものに応じてリアルタイムになります。 | 完全。これ以上リアルタイムにはなりません。中間ストレージなしでデータが即座に処理され、出力されます。 |
| カスタムメトリクス | ユースケースに特化したカスタムメトリクスはありません | 任意のタイプのカスタムメトリクス(例:「4711人の顧客が最後の時間間隔でサービスyにサインアップしました」) |
| パフォーマンス | 高い | 高い |
| スケーラブル | はい | はい |
| 回復力/HA | はい | はい |
| 永続性 | はい。それがKafkaの目的です。 | いいえ。layline.ioの目的ではありませんが、Kafkaのような永続層と非常にうまく機能します。 |
| UI駆動の設定 | いいえ | はい |
| メモリ強度 | 高い | 低い |
| ハードウェアフットプリント | 高い | 低い |
| オープンソース | はい、Community Editionの場合。Confluentソリューション(例:ksql)の場合はいいえ | まだありません。 |
| クラウド対応オファー | はい、Confluentの場合 | まだありません。 |
- layline.ioについてもっと読むにはこちら。
- お問い合わせはhello@layline.ioまで。


